在前面的文章里面我们介绍过如果通过ollama+openwebui的方式来运行本地的大语言模型,这种方法也是我最喜欢的一种方法,它最接近ChatGPT的使用习惯!不过这种方法依然有几个技术门框和一些弊病,包括:
一、需要我们安装的程序较多,包括ollama、wsl、docker desktop、openwebui等;
二、需要我们掌握一定的Linux操作系统的知识;
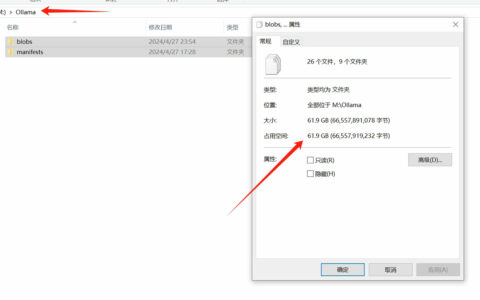
三、模型的默认位置在C盘,如果要修改默认位置的话需要手动去修改环境变量;
四、模型的存放方式以缓存的形式,文件名是一堆很长的字符串,不利于分类识别;
五、通过ollama的tag的方式去下载模型,国内的网络环境下载速度较慢,等待时间太长!
对于普通的用户来说,在本地运行LLM有更加简单的方法,只需要安装一次程序就可以!这种方法就是通过LM Studio的客户端来实现!
LM Studio介绍
程序官网:https://lmstudio.ai/
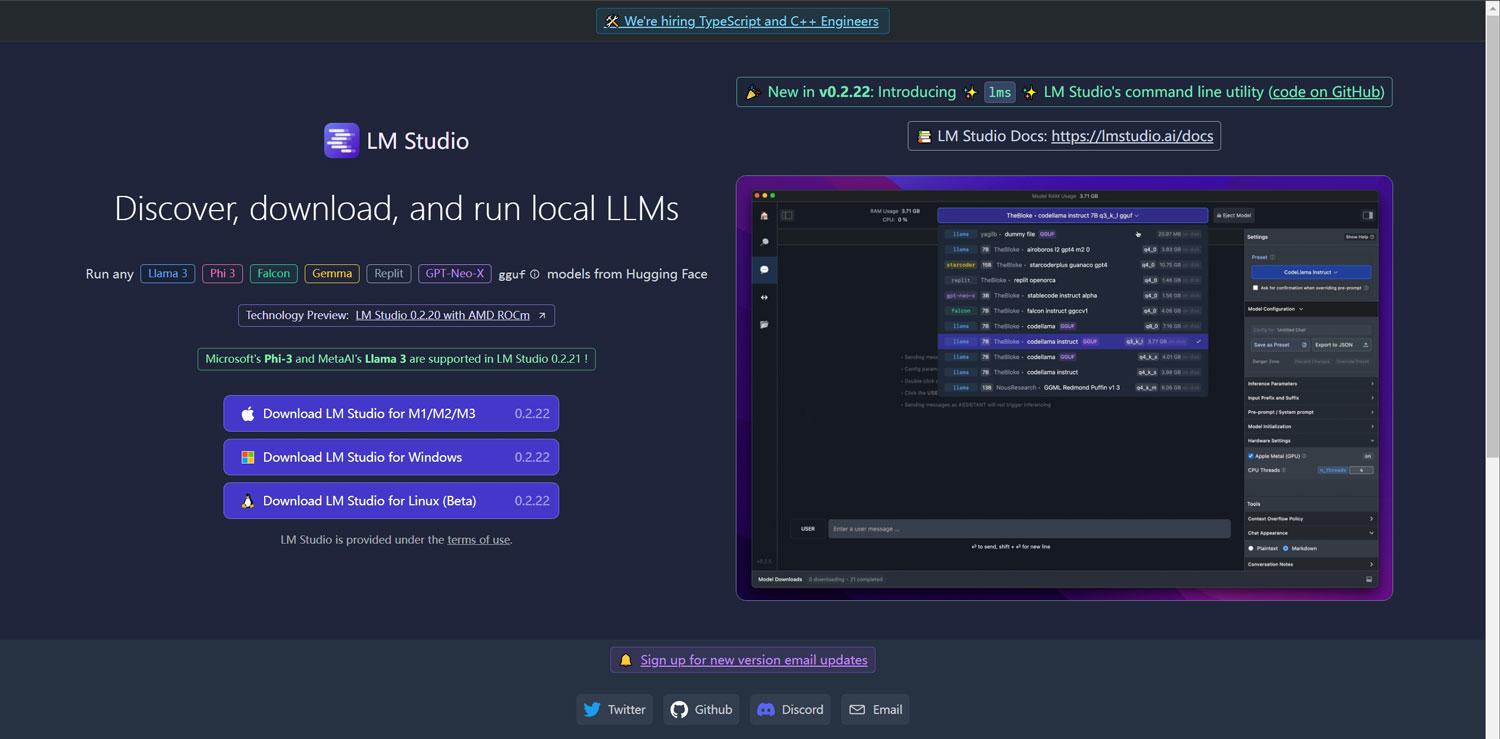
LM Studio相比较ollama来说有如下的优势:
一、支持gguf格式的LLM模型文件,gguf格式的模型文件可以直接在LM Studio中来使用,不需要进行二次转换;
二、可以很方便地设置GPU的利用率和其他参数,在界面就可以直接设置这些参数!
三、不需要安装docker,也不需要运行在wsl中,可以直接在Windows下运行;
四、本地模型可以存放在任何位置;
安装和使用
安装客户端
打开官网,可以根据你自己的操作系统下载相应的客户端版本,Windows系统就下载Windows版本的客户端
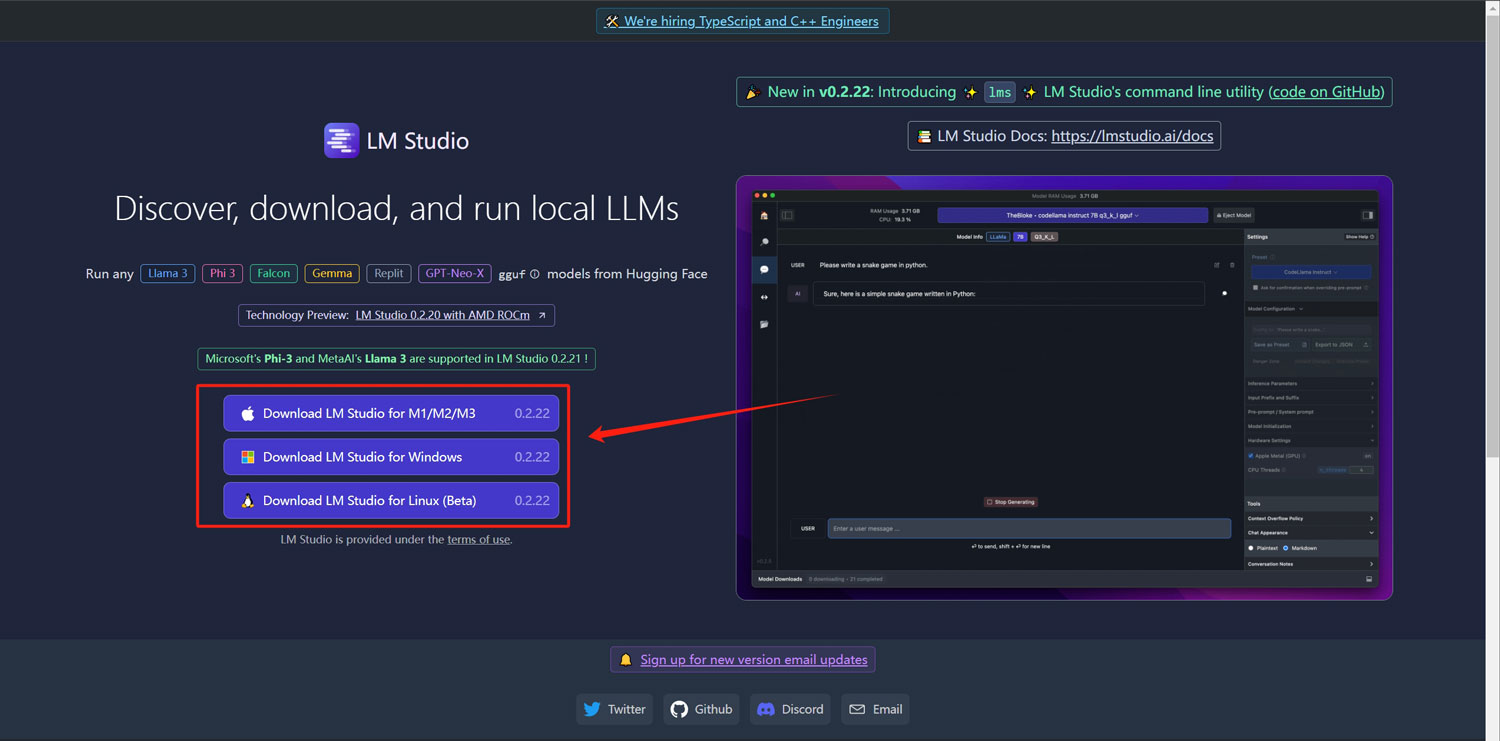
客户端下载完成之后,直接双击安装即可!全程就只有这一步安装的流程!
下载模型
虽然LM Studio也可以从客户端去直接下载模型,不过作为国内的用户我强烈不建议你这么做!因为通过客户端下载模型是从外网去下载,速度非常之慢!
你可以直接从国内的魔搭社区(https://modelscope.cn/)去下载gguf版本的模型,下载的速度通常在几M到几十M之间,下载速度要快很多!
模型下载下来之后,按照“\models\Publisher\Repository”的路径保存,可以保存在任何你想要的磁盘或者文件夹中!
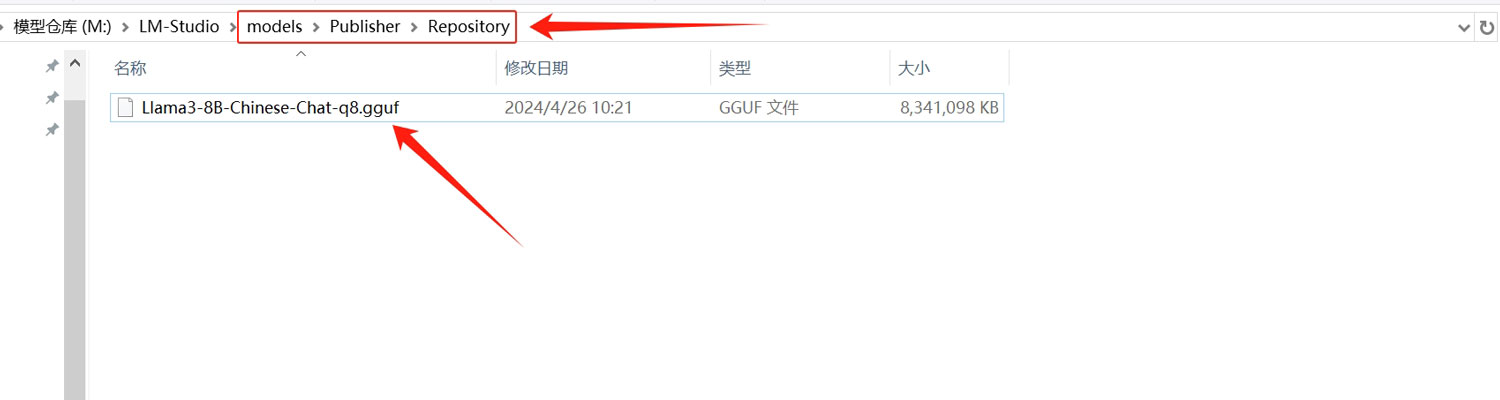
然后在LM Studio客户端点击左侧的“My Models”菜单,点击“Change”选择模型存放的路径,如果models文件夹保存在其他文件夹的子文件夹中,路径选择到models文件夹的上一级文件夹即可,不需要再进入models文件夹中!系统会自动识别到“\models\Publisher\Repository”文件夹中保存的gguf的模型文件!
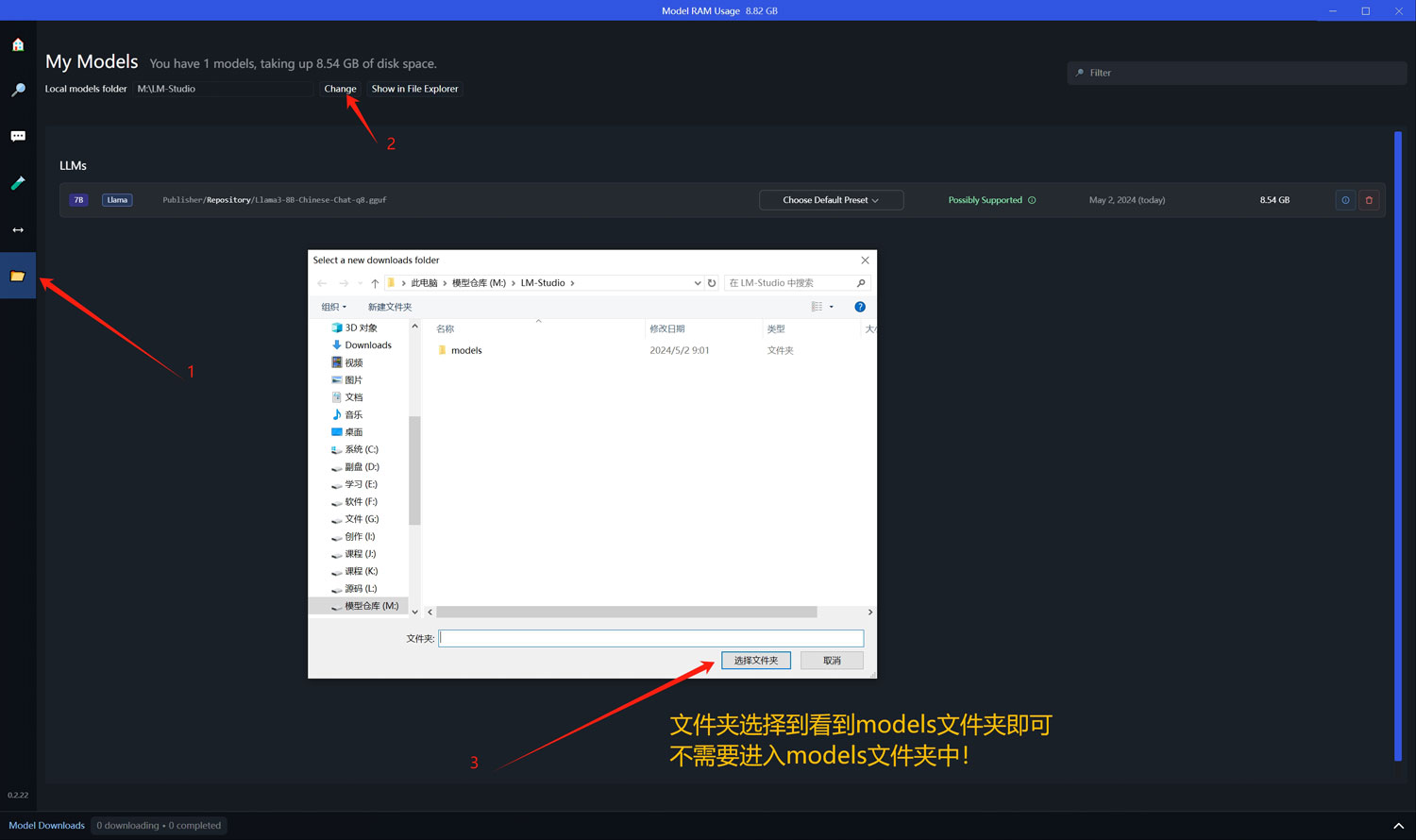
使用方法
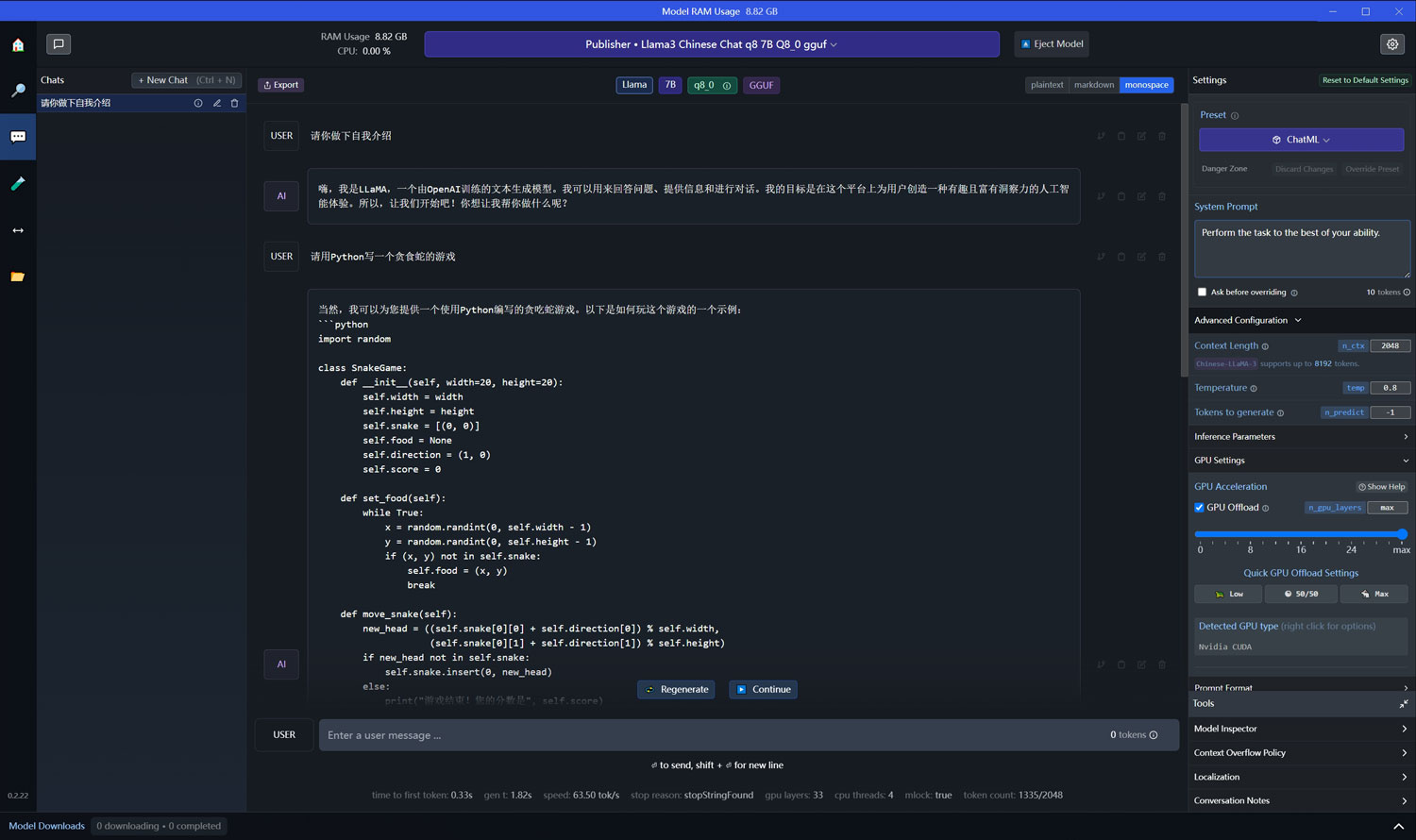
点击客户端左边的“AI Chat”菜单,进入到聊天的界面,从顶部选择一个聊天的LLM模型,即可跟该模型进行聊天交流!
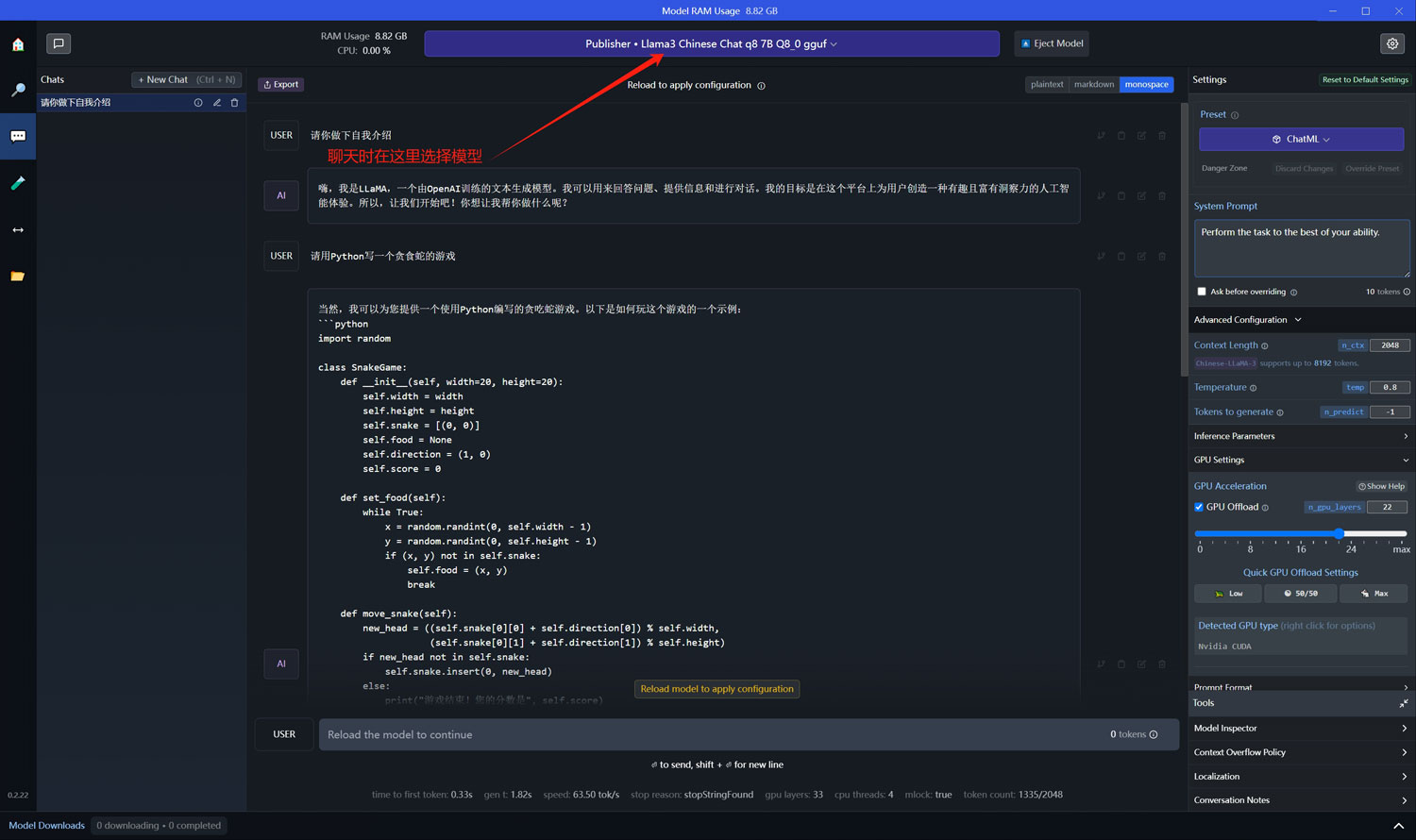
在右侧,我们可以设置“Context Length”、“Temperature”、“Tokens to generate”以及GPU显存的使用量等参数,大多数情况下我们保持默认即可!只有GPU的显存可以根据我们自己的实际情况和需要来设置!
原创文章,作者:朋远方,如若转载,请注明出处:https://caovan.com/tongguolm-studioyunxingbendedellmdayuyanmoxing/.html
 微信扫一扫
微信扫一扫