安装Python 3.8或更高版本
确保服务器上安装了Python 3.8或更高版本。如果没有,请先安装:
sudo apt update sudo apt install python3.8 python3.8-venv python3.8-dev
创建和激活虚拟环境
python3.8 -m venv faster-whisper-env source faster-whisper-env/bin/activate
安装faster-whisper
pip install faster-whisper
安装Flask和其他依赖
pip install flask
创建一个服务端Python脚本
sudo vim whisper_server.py
让后将下面的代码粘贴进去
from flask import Flask, request, jsonify
from faster_whisper import WhisperModel
app = Flask(__name__)
# 加载本地模型
model_path = "/home/arthur/faster-whisper-large-v3"
model = WhisperModel(model_path, device="cuda", compute_type="float16")
@app.route('/transcribe', methods=['POST'])
def transcribe():
file = request.files['file']
beam_size = int(request.form.get('beam_size', 5))
segments, info = model.transcribe(file, beam_size=beam_size)
result = {
"language": info.language,
"language_probability": info.language_probability,
"transcription": [{"start": s.start, "end": s.end, "text": s.text} for s in segments]
}
return jsonify(result)
if __name__ == '__main__':
app.run(host='0.0.0.0', port=5000)
启动服务
python3 whisper_server.py
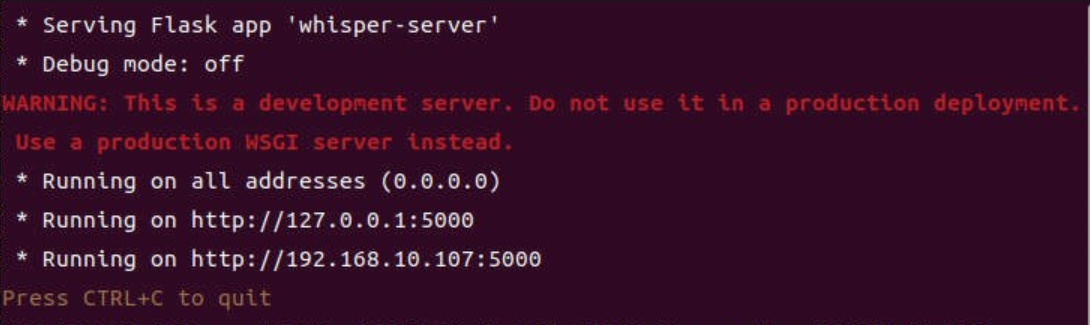
启动之后你可以看到类似如下的内容打印出来:
客户端文件示例
import requests
url = 'http://<your-server-ip>:5000/transcribe'
file_path = 'path_to_your_audio_file.mp3'
with open(file_path, 'rb') as f:
files = {'file': f}
data = {'beam_size': 5}
response = requests.post(url, files=files, data=data)
result = response.json()
print(result)
原创文章,作者:朋远方,如若转载,请注明出处:https://caovan.com/zaiubuntufuwuqishangbushufaster-whisperfuwuduan/.html
 微信扫一扫
微信扫一扫