


PCIe、NVLink、NVSwitch技术对比
| 特性 | PCIe | NVLink | NVSwitch |
|---|---|---|---|
| 主要用途 | 通用互联接口,连接 GPU、CPU、SSD 等设备 | NVIDIA GPU-GPU 或 GPU-CPU 高速互联 | 多 GPU 系统的全互联,实现 GPU 间直接通信 |
| 连接设备数量 | 理论无限制(共享总带宽) | 通常最多 8 块 GPU | 支持 16 GPU 以上的全互联 |
| 单连接带宽 | PCIe 4.0: 32GB/s(双向) PCIe 5.0: 64GB/s(双向) |
NVLink 3.0(A100): 600GB/s(双向) NVLink 4.0(H100): 900GB/s(双向) |
7.2TB/s(H100 集群内部总带宽) |
| 延迟 | 较高(受主板总线和 CPU 调度限制) | 较低(GPU-GPU 直接通信) | 更低(支持多 GPU 高效协作) |
| 拓扑结构 | 树形结构 | 点对点互联(链式或星型) | 多 GPU 全互联 |
| 适用范围 | 通用,支持所有扩展设备 | NVIDIA GPU 专用 | 高端 GPU 集群(如 DGX/DCS 系列) |
| 成本 | 主板自带,无需额外费用 | 需 NVLink Bridge,成本较高 | 集成于 DGX/DCS 系列服务器,需配套硬件 |
| 典型应用场景 | 单机小规模 GPU 系统或通用计算 | 深度学习分布式训练、GPU 高效协作 | 超大规模分布式集群(16+ GPU,全互联任务) |
关键总结
- 带宽与性能
- NVLink 带宽显著高于 PCIe(NVLink 4.0 可达 900GB/s,PCIe 5.0 仅 64GB/s)。
- NVSwitch 总带宽高达 7.2TB/s,适合大规模集群任务。
- 延迟与拓扑
- NVLink/NVSwitch 通过点对点或全互联结构降低延迟,适合实时协作任务。
- PCIe 受树形拓扑限制,延迟较高。
- 适用场景
- PCIe:通用计算、单机小规模 GPU。
- NVLink:深度学习训练、多 GPU 协作。
- NVSwitch:超大规模集群(如 AI 超算中心)。
- 成本
- PCIe 成本最低,NVLink/NVSwitch 需额外硬件投入,适合高性能需求场景。
A100各系显卡对比图
| 参数类别 | A100 PCIe | A100 SXM | A800 |
|---|---|---|---|
| 架构 | Ampere | Ampere | Ampere |
| CUDA Core 数量 | 6,912 个 | 6,912 个 | 6,912 个 |
| Tensor Core 数量 | 432 个(第三代 Tensor Core) | 432 个(第三代 Tensor Core) | 432 个(第三代 Tensor Core) |
| 显存容量 | 40 GB 或 80 GB HBM2e | 40 GB 或 80 GB HBM2e | 80 GB HBM2e |
| 显存带宽 | 1,555 GB/s(80 GB 版本) | 1,555 GB/s(80 GB 版本) | 1,330 GB/s |
| FP64 性能 | 9.7 TFLOPS | 9.7 TFLOPS | 9.7 TFLOPS |
| FP32 性能 | 19.5 TFLOPS | 19.5 TFLOPS | 19.5 TFLOPS |
| FP16/BF16 性能 | 312 TFLOPS | 312 TFLOPS | 312 TFLOPS |
| FPS 性能 | 不支持 | 不支持 | 不支持 |
| NVLink 支持 | 不支持 | 支持(600GB/s 双向) | 支持(400GB/s 双向) |
| TDP(热设计功耗) | 250W | 400W | 300W |
| 接口类型 | PCIe 4.0 | SXM4(板载插槽) | SXM4(板载插槽) |
| 目标市场 | 工作站、小型服务器 | 数据中心、高性能计算 | 数据中心(出口限制版本) |
关键总结
- 核心性能一致性
- 三款 GPU 的 CUDA Core、Tensor Core 及 FP64/FP32/FP16 计算性能完全一致,均基于 Ampere 架构。
- 显存容量差异:A800 仅提供 80 GB HBM2e 版本,而 A100 PCIe/SXM 支持 40 GB 或 80 GB 选项。
- 显存带宽与 NVLink
- 显存带宽:A800 显存带宽(1,330 GB/s)低于 A100 的 80 GB 版本(1,555 GB/s),可能影响大规模数据处理效率。
- NVLink 支持:A100 SXM 提供最高 NVLink 带宽(600GB/s),A800 为 400GB/s,A100 PCIe 不支持 NVLink。
- 功耗与接口
- TDP:A100 SXM 功耗最高(400W),适合高性能计算场景;A800(300W)在性能与功耗间平衡;A100 PCIe(250W)适合低功耗环境。
- 接口:A100 PCIe 使用通用 PCIe 4.0,而 SXM 版本需专用板载插槽,优化数据中心内部连接。
- 市场定位
- A100 PCIe:适合工作站或小型服务器,依赖 PCIe 扩展性。
- A100 SXM:专为数据中心设计,支持高带宽 NVLink 和多 GPU 协作。
- A800:面向受出口限制的数据中心,性能略降但符合特定合规要求。
应用场景建议
- 科学计算/深度学习训练:优先选择 A100 SXM(高 NVLink 带宽,适合多 GPU 并行)。
- 边缘计算/小型服务器:A100 PCIe 性价比更高,功耗更低。
- 合规敏感场景:A800 满足出口限制需求,适合特定区域的数据中心。
英伟达显卡主要分类、命名规则及功能总结
| 类别 | 系列 | 主要特点 | 应用场景 | 典型用户 | 典型显卡 | 诞生时间 |
|---|---|---|---|---|---|---|
| 消费级显卡 | RTX 系列 | 面向消费级市场,兼顾游戏、图形渲染和轻量深度学习任务。 | 游戏、图形渲染、轻量级深度学习、AI 推理 | 游戏玩家、AI 初学者 | RTX 3090、RTX 4090 | 2018 年 (RTX 20) |
| 数据中心显卡 | A 系列 | 高性能训练和推理显卡,适合大规模深度学习训练。 | 大规模深度学习训练、推理、高性能计算 (HPC) | 数据中心、AI 研究团队 | A100、A10、A4 | 2020 年 (Ampere) |
| 数据中心显卡(特供) | A800 系列 | A 系列的特供版,性能略低但适合中国市场。 | 针对中国市场的特供显卡,调整性能以符合出口限制 | 中国市场的大模型训练和推理 | A800 | 2021 年 (A800) |
| 高端数据中心显卡 | H 系列 | NVIDIA 的高端显卡,支持超大规模模型训练(如 GPT-3/4)。 | 超大规模深度学习训练、推理、低精度计算 (FPB) | 超大规模 AI 项目、HPC 任务 | H100、H200 | 2022 年 (Hopper) |
| 高端数据中心显卡(特供) | H800 系列 | H 系列的特供版,性能略低但适合中国市场。 | 针对中国市场的特供显卡,调整性能以符合出口限制 | 中国市场的大模型训练和推理 | H800 | 2021 年 (A800) 或 2022 (Hopper)* |
| 专业图形显卡 | L 系列 | 专业图形和推理显卡,适合数据可视化和轻量推理任务。 | 数据可视化、AI 推理、工作站任务 | 数据分析师、工作站用户 | L40、L20、L4 | 2022 年 (Ada) |
| 入门级数据中心显卡 | T 系列 | 入门级显卡,低功耗,适合推理和虚拟化任务。 | 云推理服务、虚拟化工作站、轻量化 AI 推理任务 | 节能型数据中心、云服务 | T4 | 2018 年 (Turing) |
英伟达主流显卡性能对比图
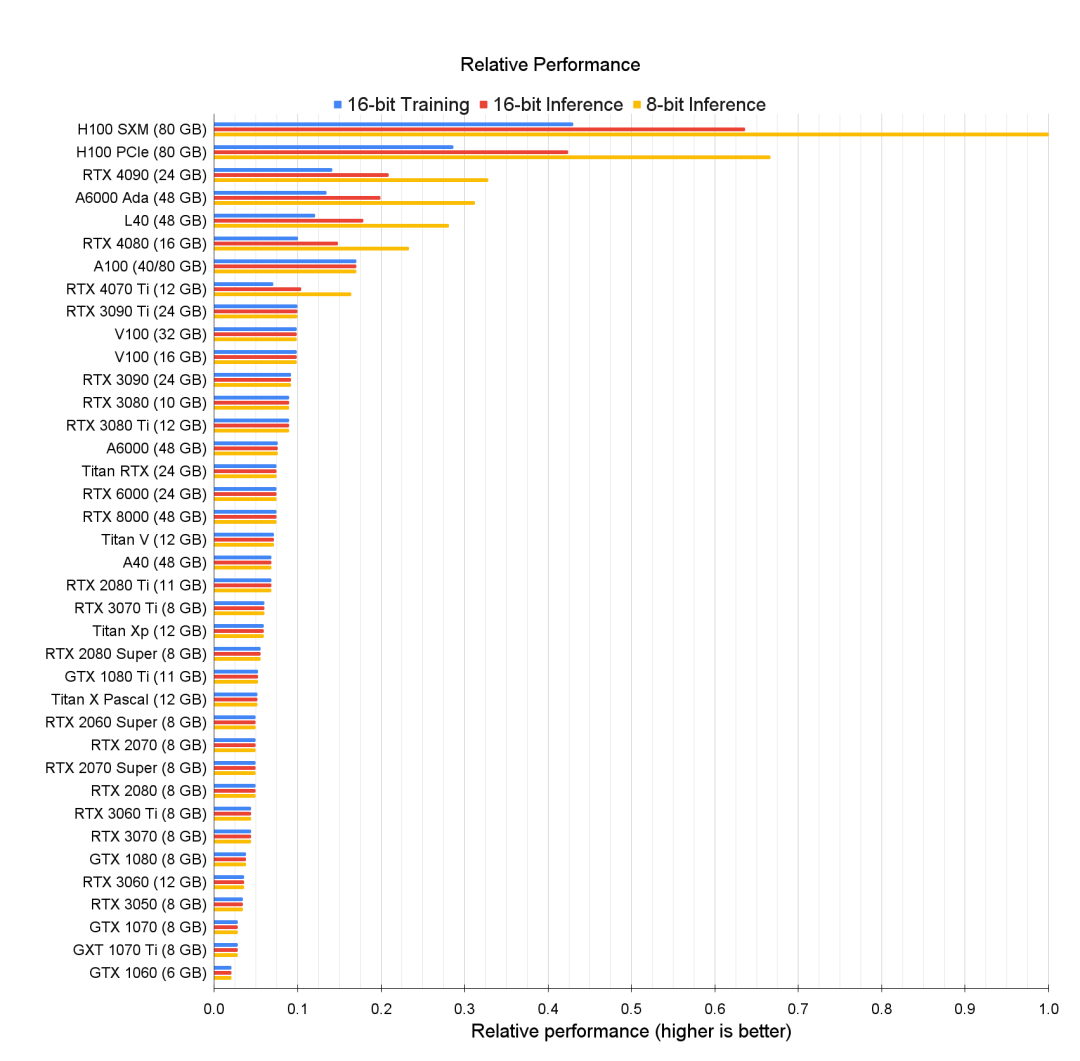
英伟达主流显卡性价比对比图

不同尺寸、不同精度大模型推理所需显存及硬件推荐
| 模型尺寸 | 精度 | 显存需求 (GB) | 推荐显卡 |
|---|---|---|---|
| 7B | FP16 | 12 | RTX 4080 / RTX 4090 |
| INT8 | 8 | RTX 4080 / T4 | |
| INT4 | 6 | RTX 4080 / RTX 3060 | |
| INT2 | 4 | RTX 3060 / RTX 4080 | |
| 13B | FP16 | 24 | RTX 4090 |
| INT8 | 16 | RTX 4090 | |
| INT4 | 12 | RTX 4090 / RTX 4080 | |
| INT2 | 8 | RTX 4080 / RTX 4090 | |
| 30B | FP16 | 60 | A100 (40GB) * 2 |
| INT8 | 40 | L40 (48GB) | |
| INT4 | 24 | RTX 4090 | |
| INT2 | 16 | T4 (16GB) | |
| 70B | FP16 | 120 | A100 (80GB) * 2 |
| INT8 | 80 | L40 (48GB) * 2 | |
| INT4 | 48 | L40 (48GB) | |
| INT2 | 32 | RTX 4090 | |
| 110B | FP16 | 200 | H100 (80GB) * 3 |
| INT8 | 140 | H100 (80GB) * 2 | |
| INT4 | 72 | A10 (24GB) * 3 | |
| INT2 | 48 | A10 (24GB) * 2 |
不同尺寸、不同精度大模型训练所需显存及硬件推荐
| 模型尺寸 | 精度 | 显存需求(GB) | 推荐硬件配置 |
|---|---|---|---|
| 7B | AMP | 120 | A100 (40GB) * 3 |
| FP16 | 60 | A100 (40GB) * 2 | |
| 13B | AMP | 240 | A100 (80GB) * 3 |
| FP16 | 120 | A100 (80GB) * 2 | |
| 30B | AMP | 600 | H100 (80GB) * 8 |
| FP16 | 300 | H100 (80GB) * 4 | |
| 70B | AMP | 1200 | H100 (80GB) * 16 |
| FP16 | 600 | H100 (80GB) * 8 | |
| 110B | AMP | 2000 | H100 (80GB) * 25 |
| FP16 | 900 | H100 (80GB) * 12 |
不同尺寸、不同精度大模型高效微调所需显存及硬件推荐
| 模型尺寸 | 精度 | 显存需求 (GB) | 推荐硬件配置 |
|---|---|---|---|
| 7B | Freeze (FP16) | 20 | RTX 4090 |
| LoRA (FP16) | 16 | RTX 4090 | |
| QLoRA (INT8) | 10 | RTX 4080 | |
| QLoRA (INT4) | 6 | RTX 3060 | |
| 13B | Freeze (FP16) | 40 | RTX 4090 / A100 (40GB) |
| LoRA (FP16) | 32 | A100 (40GB) | |
| QLoRA (INT8) | 20 | L40 (48GB) | |
| QLoRA (INT4) | 12 | RTX 4090 | |
| 30B | Freeze (FP16) | 80 | A100 (80GB) |
| LoRA (FP16) | 64 | A100 (80GB) | |
| QLoRA (INT8) | 40 | L40 (48GB) | |
| QLoRA (INT4) | 24 | RTX 4090 | |
| 70B | Freeze (FP16) | 200 | H100 (80GB) * 3 |
| LoRA (FP16) | 160 | H100 (80GB) * 2 | |
| QLoRA (INT8) | 80 | H100 (80GB) | |
| QLoRA (INT4) | 48 | L40 (48GB) | |
| 110B | Freeze (FP16) | 360 | H100 (80GB) * 5 |
| LoRA (FP16) | 240 | H100 (80GB) * 3 | |
| QLoRA (INT8) | 140 | H100 (80GB) * 2 | |
| QLoRA (INT4) | 72 | A10 (24GB) * 3 |
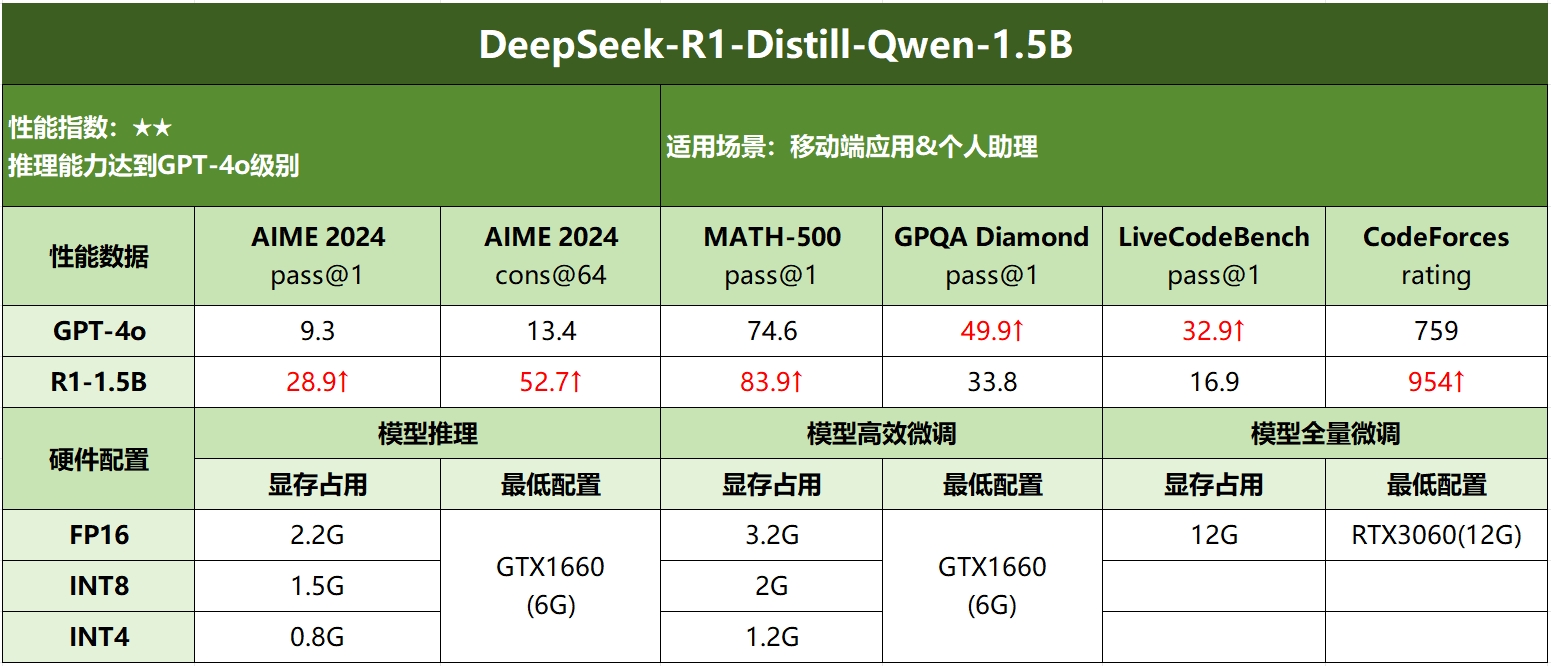
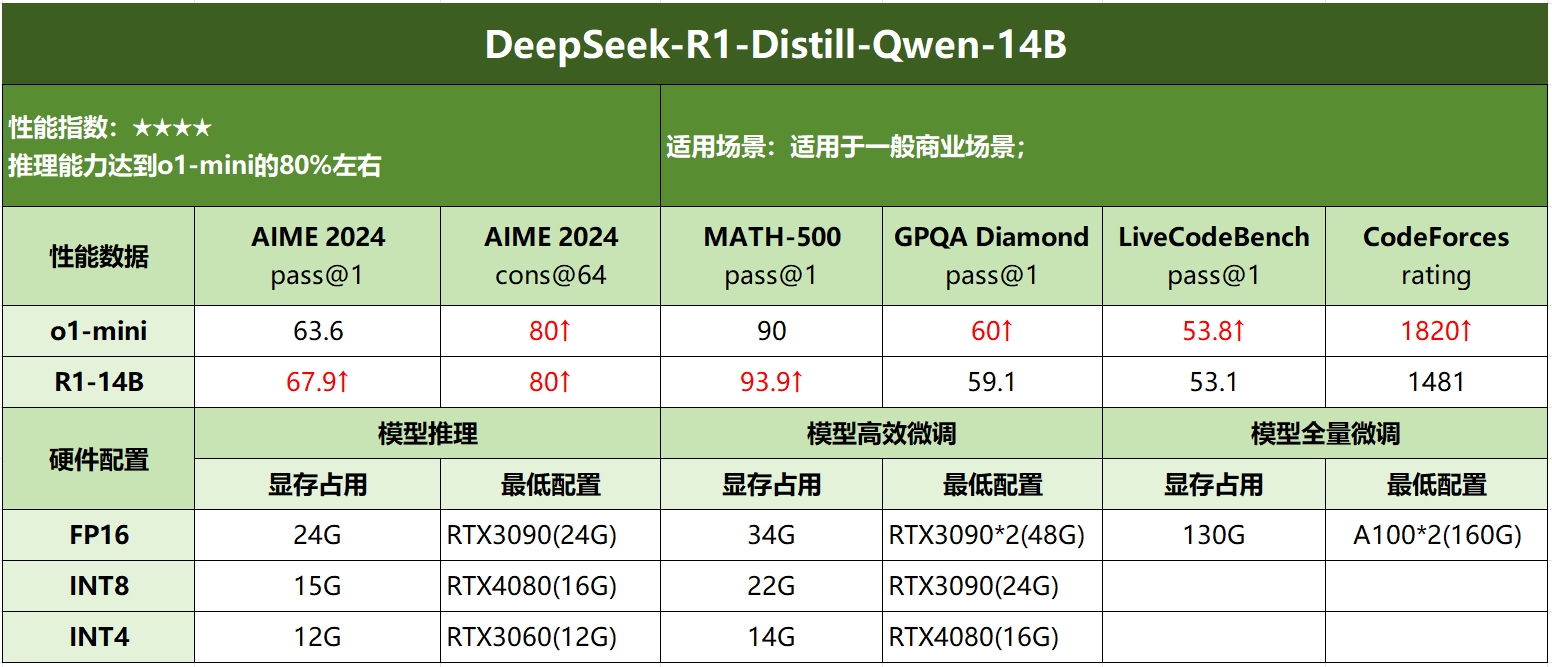
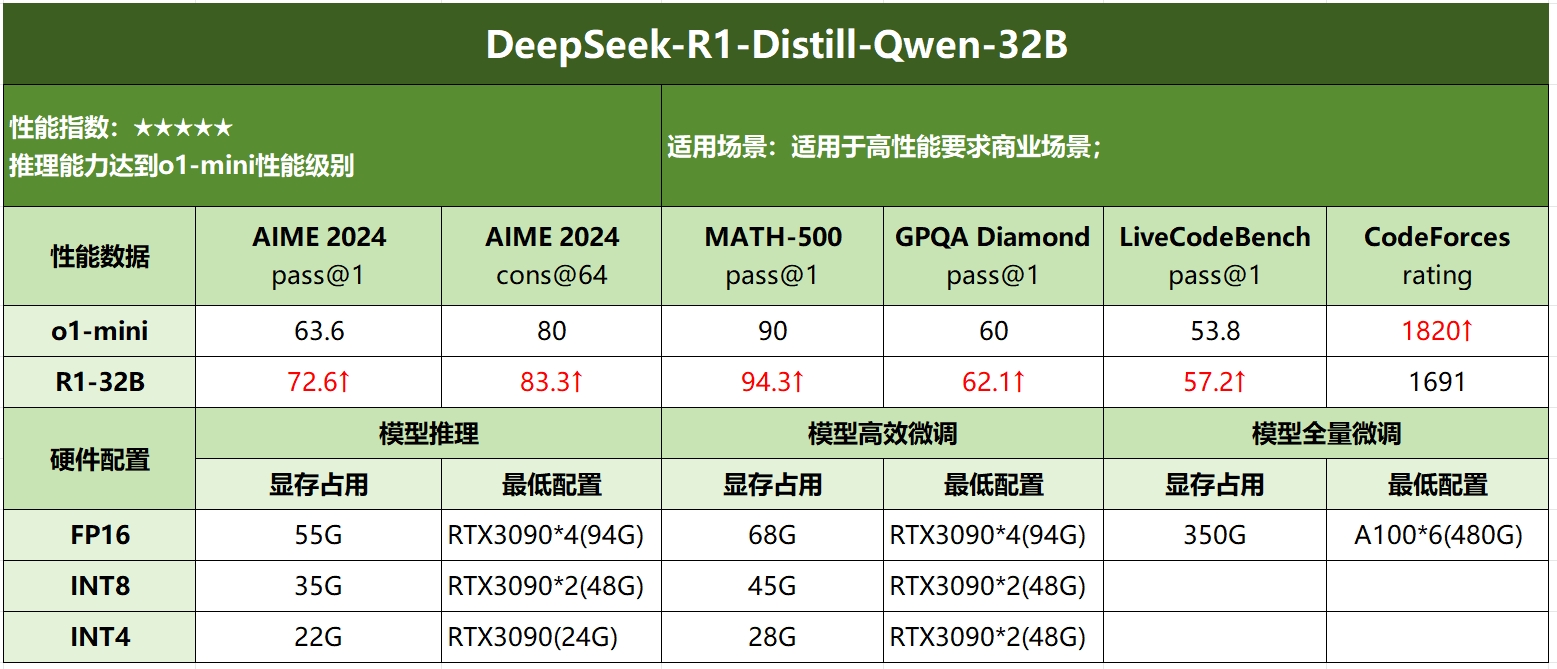
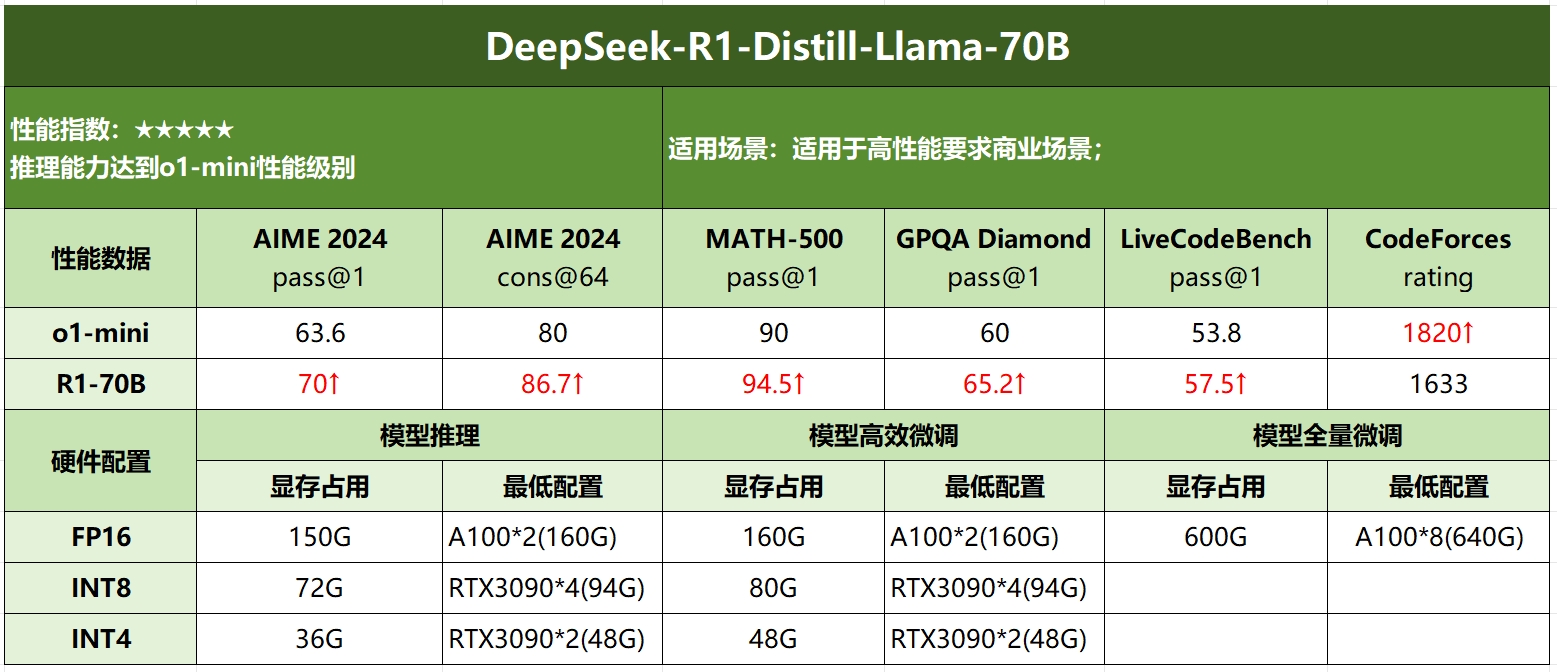
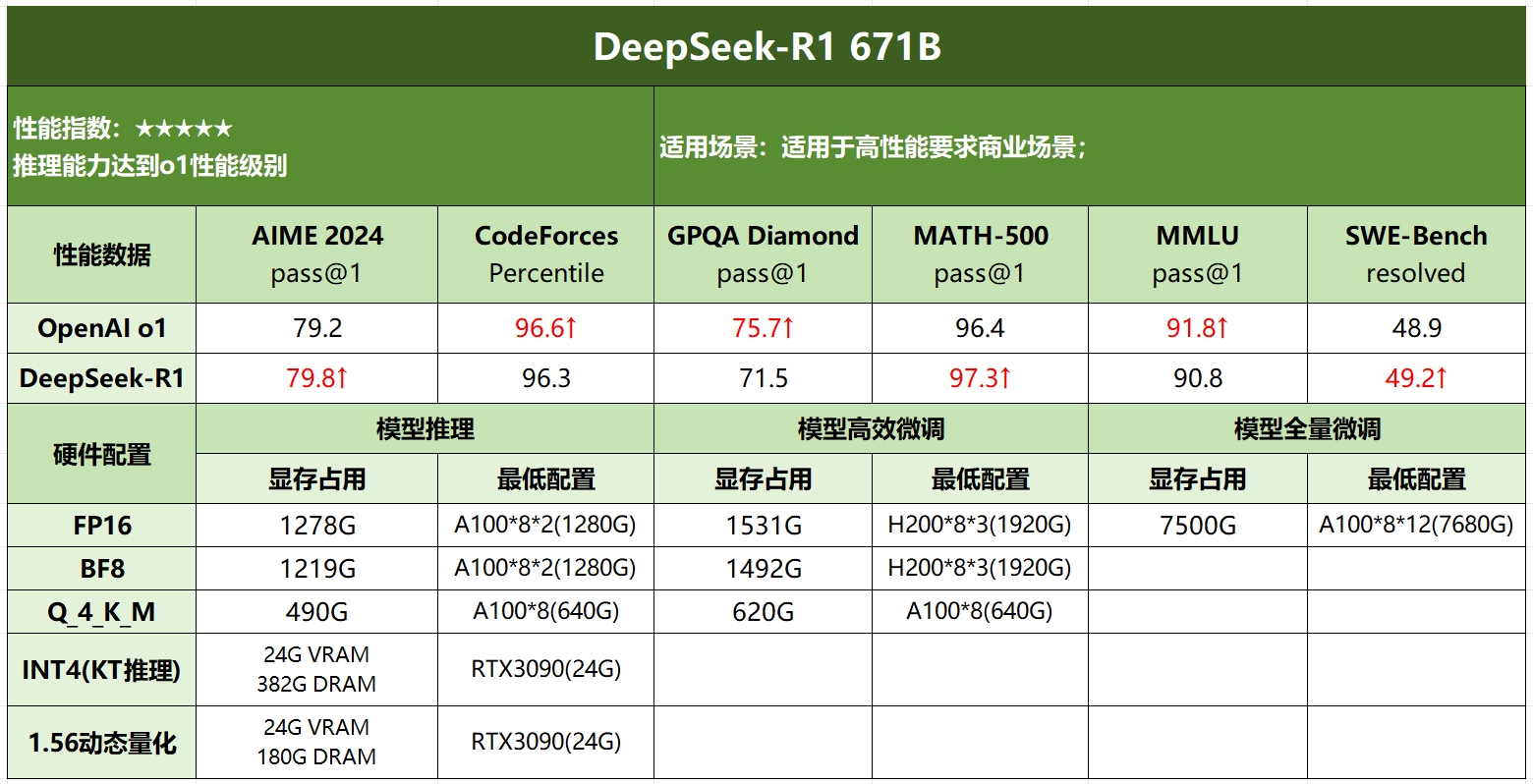
DeepSeek R1各模型硬件需求
| 模型名称 | 显存需求(推理) | 推荐CPU | 推荐GPU | 推荐内存 |
|---|---|---|---|---|
| DeepSeek-R1-Distill-Qwen-1.5B | 4GB+ | Xeon W-2400系列 | GTX 1660 | 8GB+ |
| DeepSeek-R1-3B | 8GB+ | Xeon W-2400系列 | RTX 3060 | 16GB+ |
| DeepSeek-R1-Distill-Qwen-7B | 14GB+ | Xeon W-2400系列 | RTX 4080 | 16GB+ |
| BDeepSeek-R1-Distill-Llama-8B | 16GB+ | Xeon W-2400系列 | RTX 4080 | 16GB+ |
| DeepSeek-R1-Distill-Qwen-14B | 28GB+ | Xeon W-3400系列 | RTX 3090 * 2 | 32GB+ |
| DeepSeek-R1-Distill-Qwen-32B | 58GB+ | Xeon W-3400系列 | RTX 3090 * 4 | 64GB+ |
| DeepSeek-R1-Distill-Llama-70B | 140GB+ | EPYC 7002系列 | A100 * 2 | 128GB+ |
| DeepSeek-R1-671B (Q4_K_M) | 490GB+ | EPYC 7002系列 | A100 * 8 * 1 | 512GB+ |
| DeepSeek-R1-671B | 1200GB+ | EPYC 7002系列 | A100 * 8 * 2 | 1T+ |


原创文章,作者:朋远方,如若转载,请注明出处:https://caovan.com/damoxingheyingjianpeizhiduizhaobiao/.html
 微信扫一扫
微信扫一扫 



![[图文对照]stable diffusion人物表情提示词大全](https://caovan.com/./uploads/2023/08/face-promptcaovan-480x300.jpg)
