MaxKB = Max Knowledge Base,是一款基于大语言模型和 RAG 的开源知识库问答系统,广泛应用于智能客服、企业内部知识库、学术研究与教育等场景。
本教程以Ubuntu 22.04服务器(搭载4 * 2080Ti 22G魔改显卡)为例,安装MaxKB的全流程!
☞☞☞ 定制同款Ubuntu服务器 ☜☜☜

☞☞☞ 定制同款Ubuntu服务器 ☜☜☜
在线安装
如果不更换端口,则可以直接用如下的docker命令
docker run -d --name=maxkb --restart=always -p 8080:8080 -v ~/.maxkb:/var/lib/postgresql/data -v ~/.python-packages:/opt/maxkb/app/sandbox/python-packages registry.fit2cloud.com/maxkb/maxkb
如果要指定端口,比如指定8002端口,则用如下的命令
docker run -d --name=maxkb --restart=always -p 8002:8080 -v ~/.maxkb:/var/lib/postgresql/data -v ~/.python-packages:/opt/maxkb/app/sandbox/python-packages registry.fit2cloud.com/maxkb/maxkb
安装成功之后,默认的登录信息如下
http://目标服务器 IP 地址:8080
默认登录信息
用户名:admin 默认密码:MaxKB@123..
初次登录可以修改默认密码
添加OpenAI兼容的api LLM
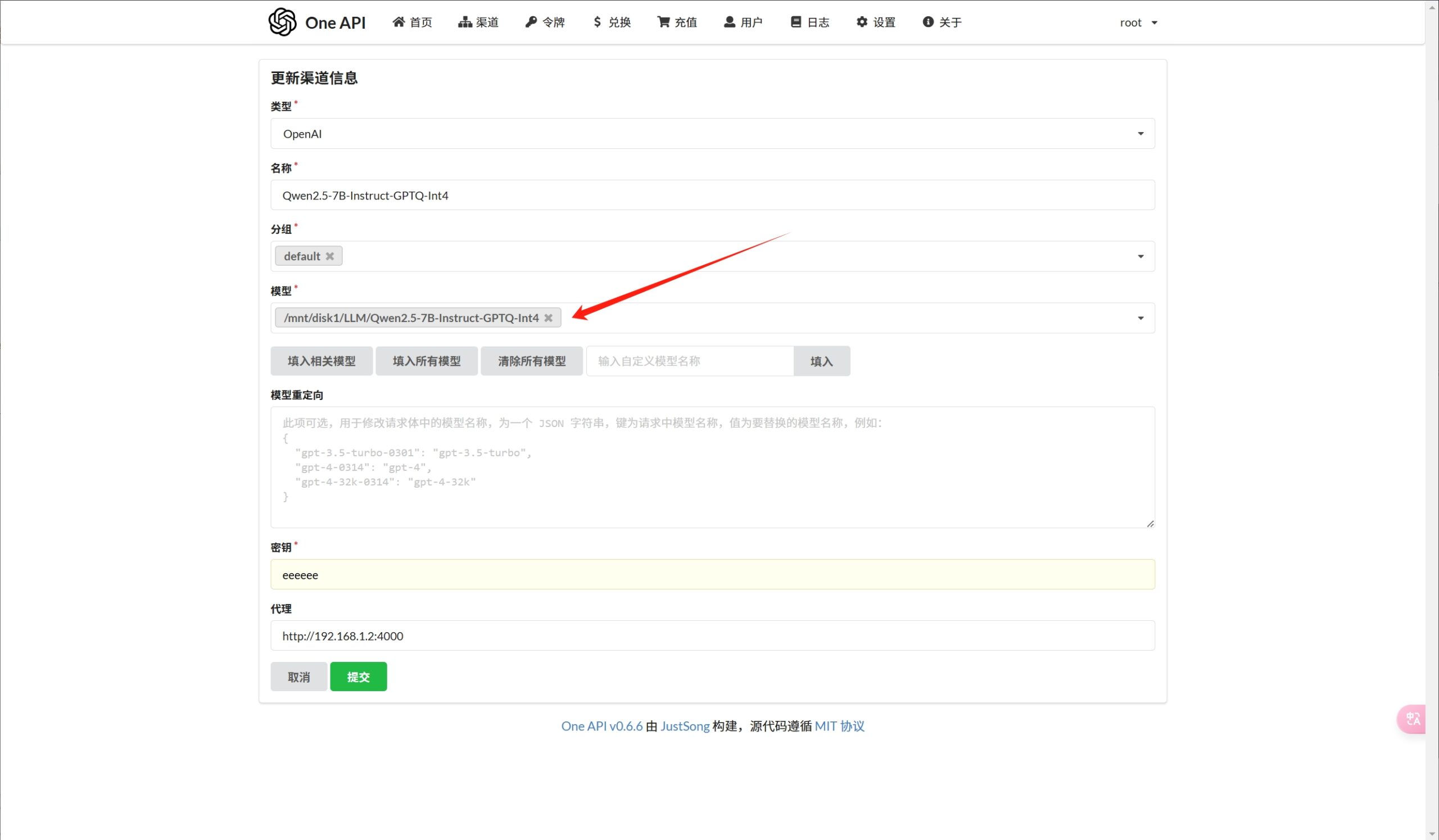
特别需要注意的是,添加本地模型如果是vllm+oneapi框架驱动的LLM,参考如下的配置
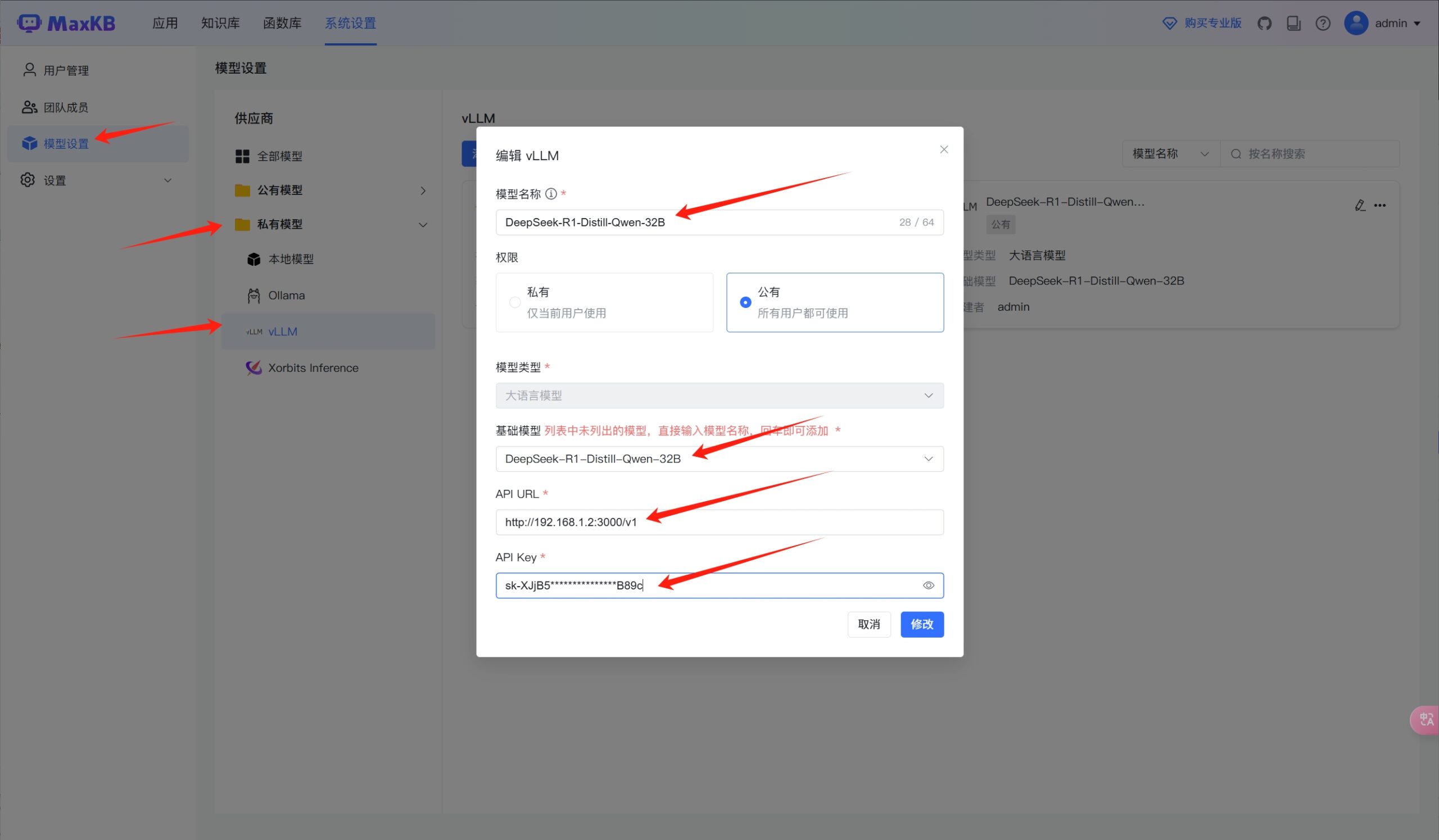
尤其是API URL一栏,即使做了域名解析,也需要填写IP地址;
另外就是基础模型一栏,模型名称一定要与oneapi中的模型名称保持一致,否则会无法识别!
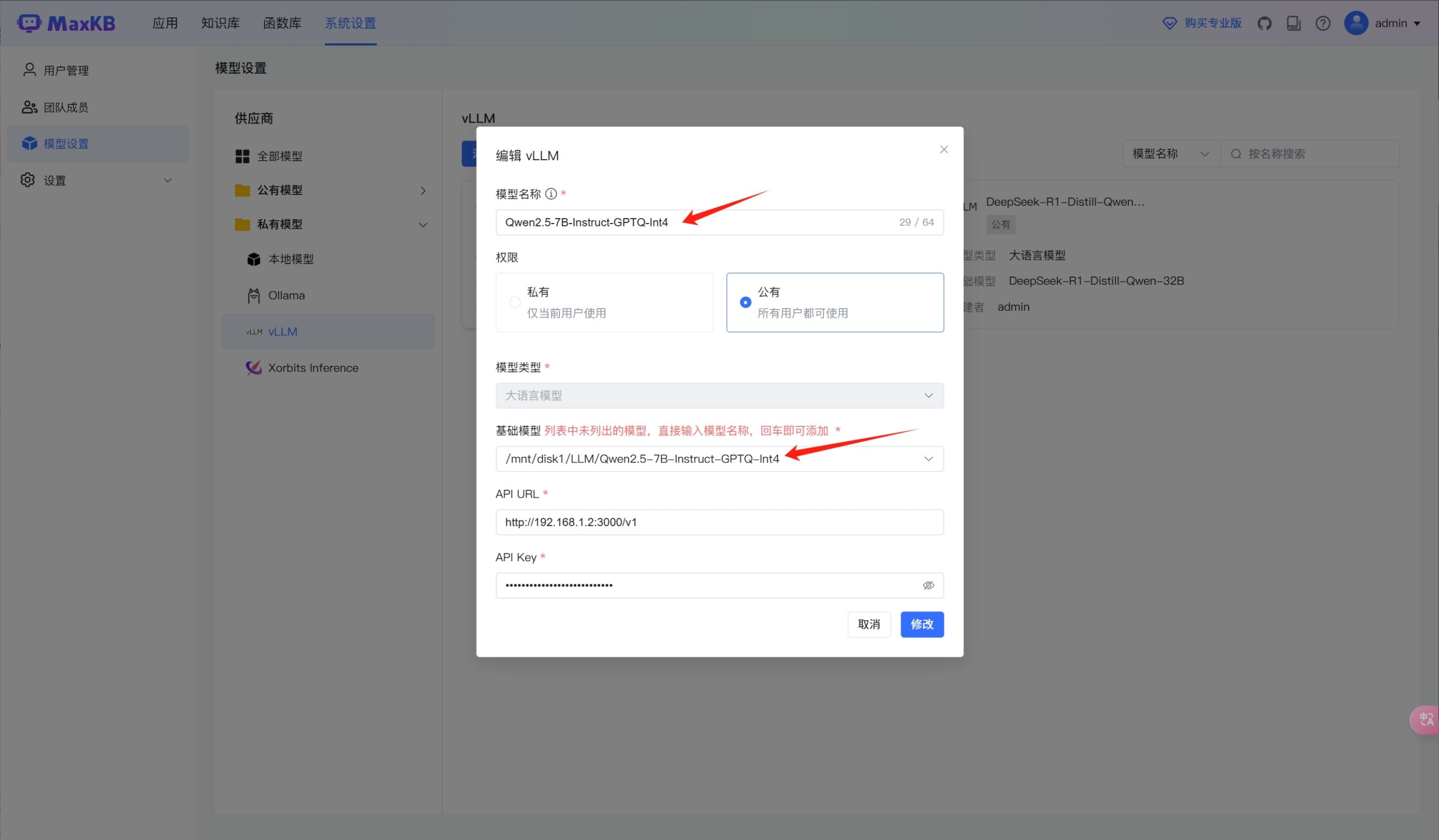
在示例中,模型的基础模型的名称是带路径的,这是为了与oneapi中的模型名称保持一致!
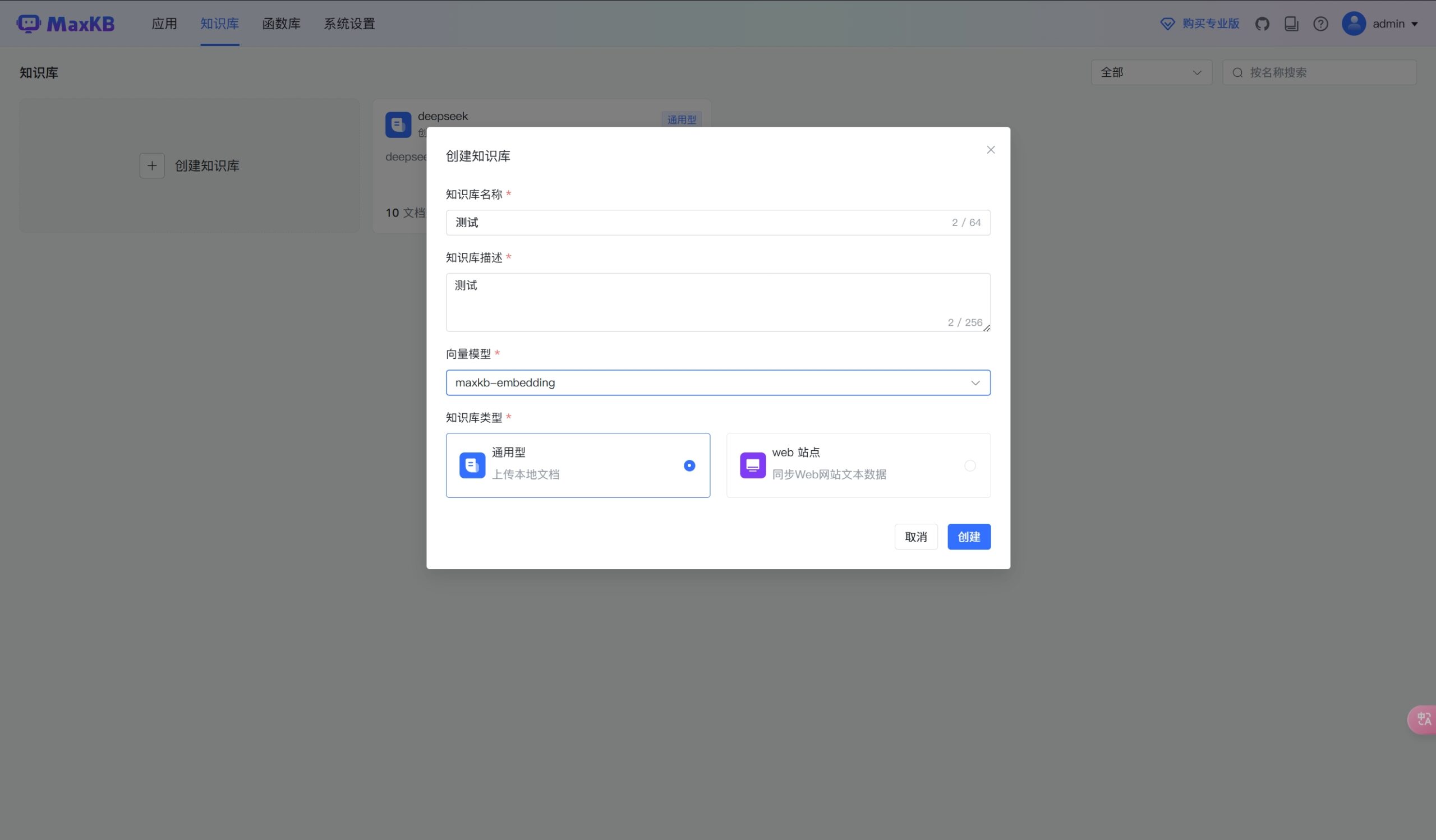
创建知识库
MaxKB比fastGPT和RAGFlow更方便的一点是MaxKB安装后自带一个embedding模型,在创建知识库的时候可以直接选择这个默认的maxkb-embedding模型;
知识库的类型分为:通用型和web站点
通用型说白了就是需要自己上传文档的,web站点就是可以提供一个网站地址,系统自己去抓取网站上的内容;
以通用型知识库为例,文档上传之后会自动进行向量化处理;

但是我们还需要全选文件——生成问题,这里选择的就是生成式大模型来处理这个步骤,原理就是大模型根据上传的文件内容来预设一些用户可能会问到的问题!
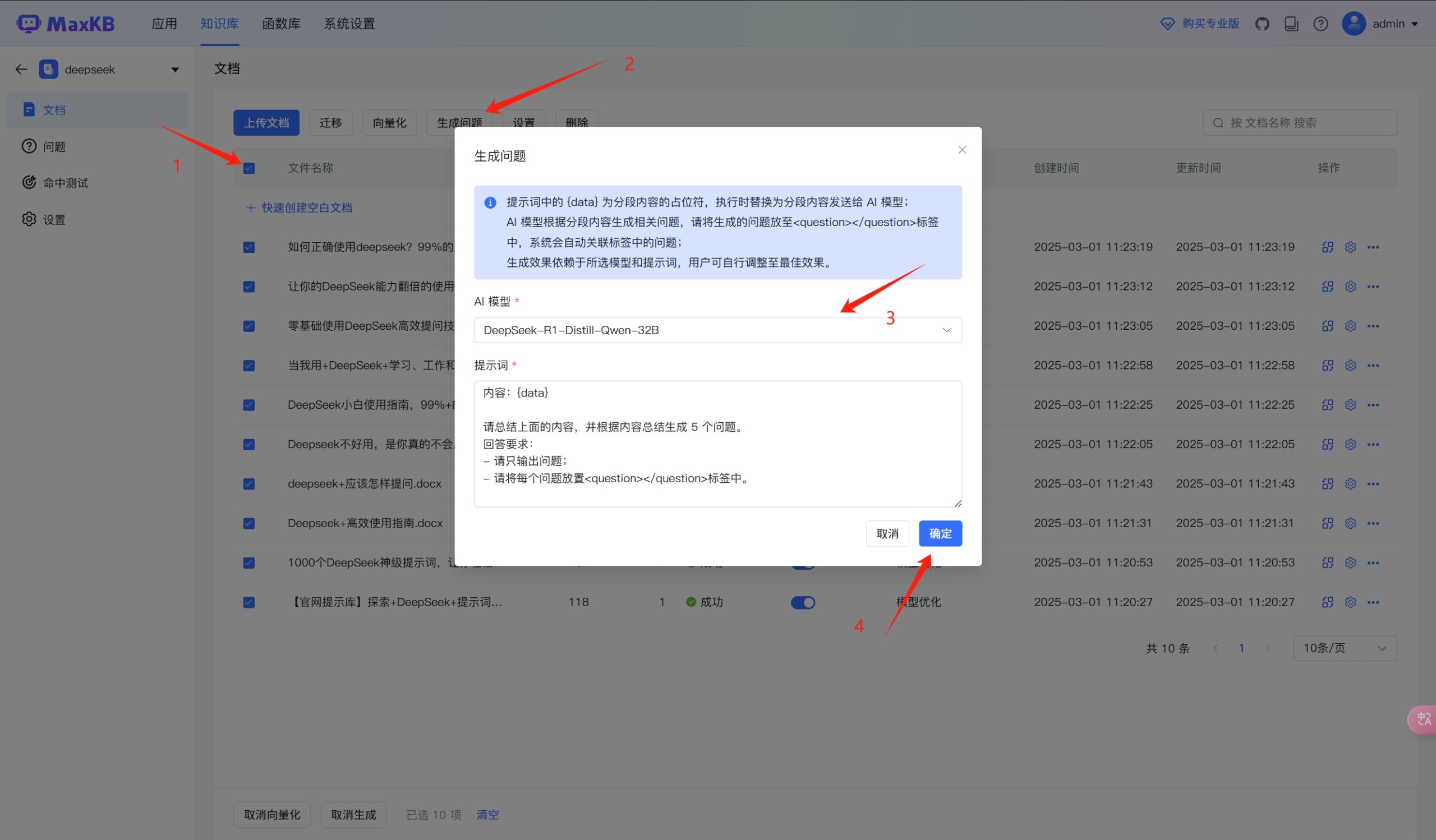
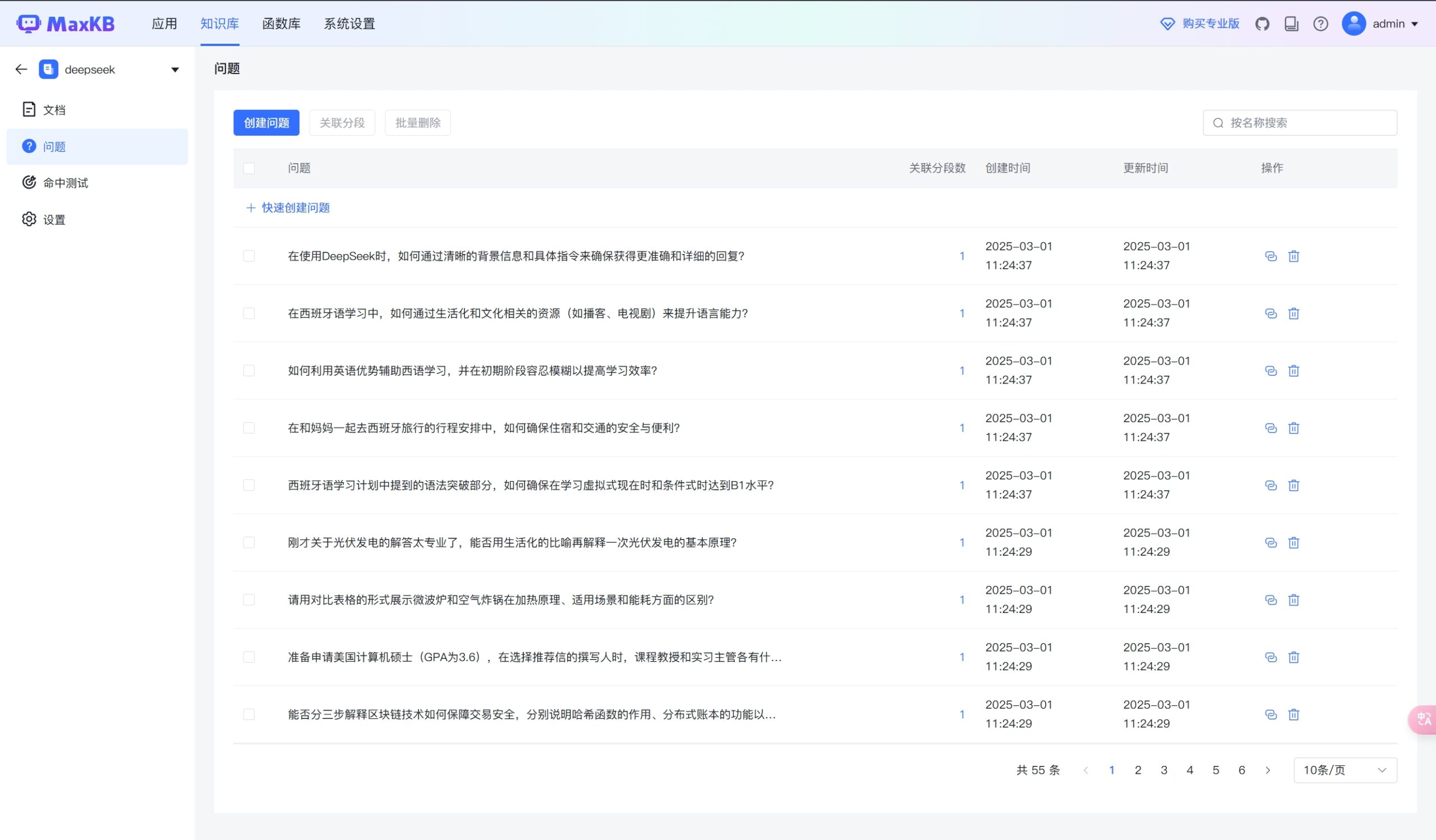
生成问题之后更加有利于大语言模型检索
创建应用
创建应用关键的地方有几个,第一,选择一个AI模型;第二关联一个创建好的知识库;
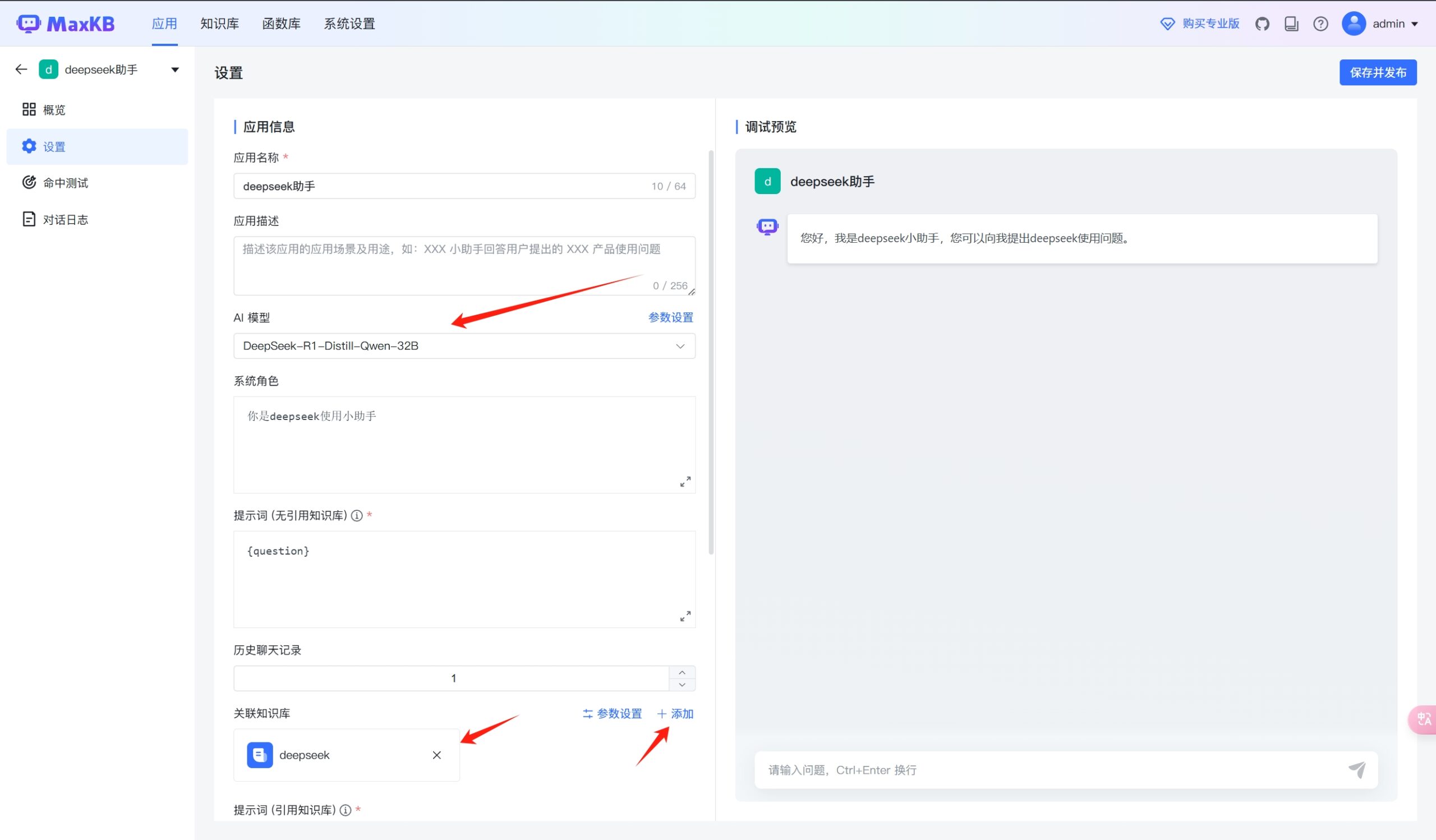
针对DeepSeek-R1这种具有深度思考功能的模型,还可以自己选择要不要输出思考的内容!
不过这里好像有个bug,即使不点选,好像也会输出思考的内容。
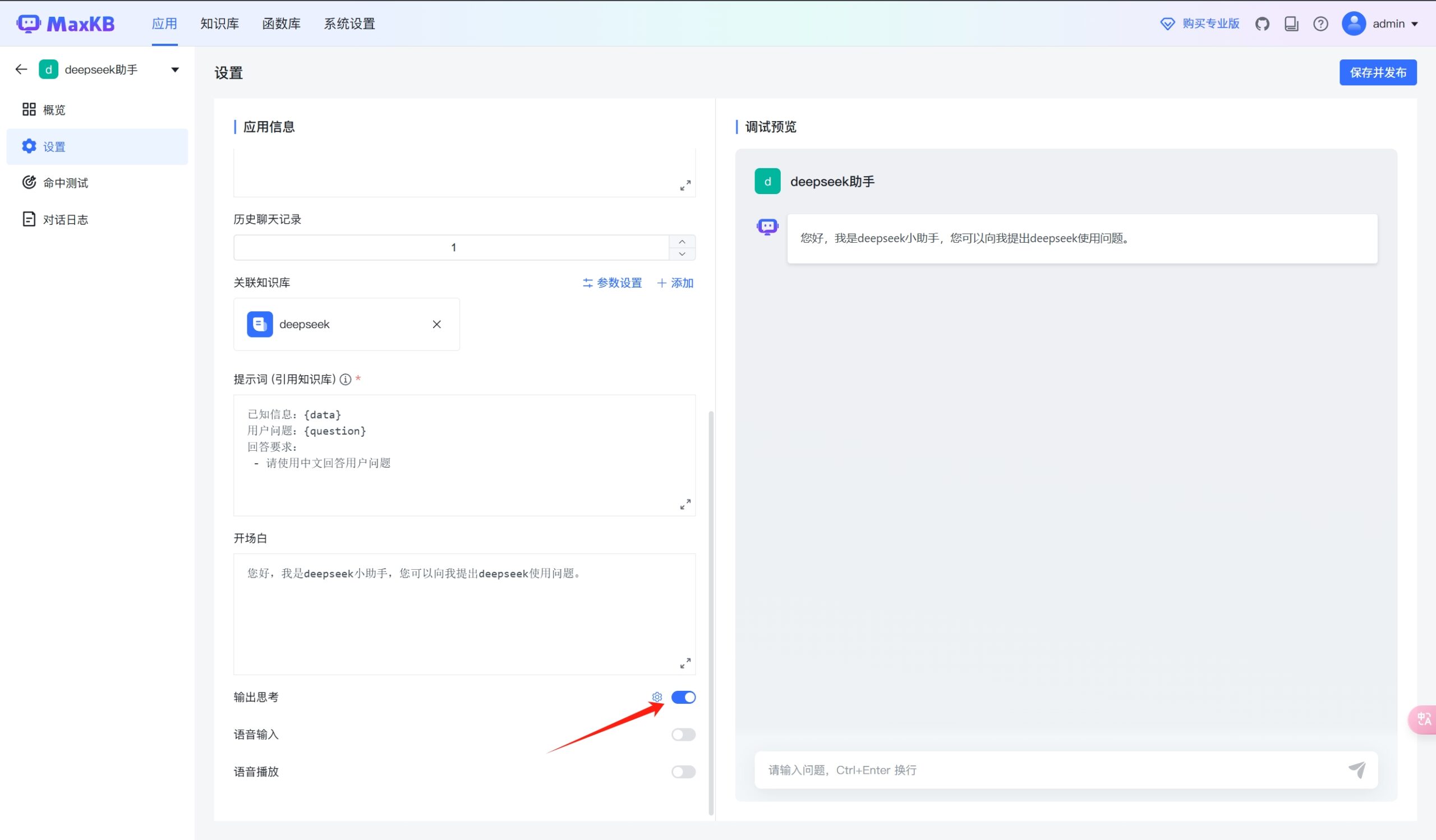
在关联了知识库的应用中进行聊天的时候,AI首先会从知识库中寻找与问题相关的信息,然后再准确做出回答!
常用的命令
删除已存在的容器
docker rm -f maxkb
重启现有容器
docker restart maxkb
查看现有容器状态
docker ps -a
大文件无法处理的解决方案
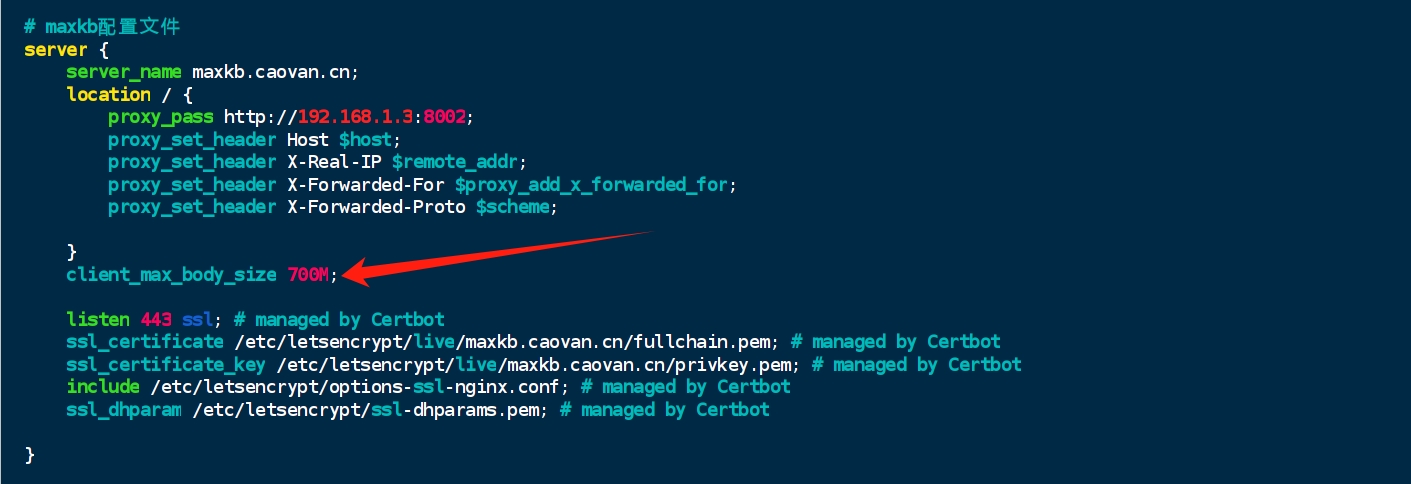
我们在使用MaxKB的过程中,可能会遇到文件上传之后无法生成预览,也无法上传成功的奇怪问题,导致这个问题的原因就是服务器对程序上传文件的大小有限定,我们需要修改nginx中关于文件大小的限制
编辑nginx配置文件
sudo vim /etc/nginx/sites-available/default
增加如下的参数:
client_max_body_size 700M;
然后重启nginx生效
sudo systemctl reload nginx
然后你再次上传大文件的时候,就可以正常预览和上传成功啦!
原创文章,作者:朋远方,如若转载,请注明出处:https://caovan.com/ubuntufuwuqimaxkbdebushuliucheng/.html
 微信扫一扫
微信扫一扫 





![[图文对照]stable diffusion人物服装提示词大全](https://caovan.com/./uploads/2023/08/clothingpromptcaovan-480x300.jpg)