


👇👇👇👇👇👇👇👇👇👇👇👇👇👇👇👇👇👇👇👇👇👇
(插件最新版已经更新为v0.4.35版,可以直接跳转到《Caovan vLLM SM75 Turbo3 v0.4.35 vLLM外部推理加速插件的安装与使用教程》查看)
本文详细介绍 Caovan vLLM SM75 Turbo3 v0.4.33 的安装与使用方法,适用于 2×RTX 2080Ti 22G / SM75 显卡运行 Qwen3.6-27B-AWQ-INT4。教程包含环境要求、插件安装、doctor 检查、vLLM 启动命令、关键日志判断、常见问题排查,以及 v0.4.33 相比 v0.4.22 的核心变化说明。

一、版本说明
Caovan vLLM SM75 Turbo3 external plugin v0.4.33 是面向 RTX 2080Ti / SM75 架构的阶段性新版本。
相比之前公开使用较多的 v0.4.22,v0.4.33 的重点不再只是自动注入启动参数,而是进一步引入了:
Caovan GDNCore Real Prefill AcceptanceLock Iota MTP=3 稳定路线 split-QK + fused V/GDN decode path external_gdn_kernel=none tilelang=not required runtime_cuda_extension=not required
简单来说,v0.4.33 的目标是:
继续保持 2×RTX 2080Ti 22G 的显存安全 不使用 MTP=4 这种容易 OOM 的路线 不依赖 FlashQLA / TileLang / 外部 GDN kernel 通过自研 GDNCore 接管 real-prefill 通过 AcceptanceLock 保护 MTP speculative decoding 的接受率
如果你之前使用的是 v0.4.22,可以把 v0.4.33 理解为一个新的阶段性升级版:它保留了 AutoSpec、DynamicTP、AutoMem、Elastic-KV 等自动化能力,同时进一步把优化推进到底层 GDNCore 和 decode path。
二、适用环境
本教程主要面向如下环境:
系统:Ubuntu 22.04 显卡:2×RTX 2080Ti 22G 架构:SM75 模型:Qwen3.6-27B-AWQ-INT4 推理框架:vLLM 插件版本:caovan-vllm-sm75-turbo3 v0.4.33 Python 环境:Miniconda / Conda
实测环境中使用的关键软件栈包括:
Python 3.11 PyTorch 2.11.0+cu130 CUDA runtime 13.0 Triton 3.6.0 vLLM 0.21.0 ptxas /usr/local/cuda/bin/ptxas
注意:不同机器的软件栈可能存在差异。如果环境差异较大,建议先运行 caovan-sm75-doctor 检查。
三、准备插件压缩包
下载插件:
将插件压缩包上传到服务器用户目录,例如:
~/caovan-vllm-sm75-turbo3-v0.4.33-external-plugin.zip
压缩包内应包含:
CHANGELOG.md LICENSE README.md VERSION docs/ pyproject.toml src/ dist/caovan_vllm_sm75_turbo3-0.4.33-py3-none-any.whl
其中真正安装的是 dist/ 目录下的 wheel 文件。
四、安装 v0.4.33 插件
请复制以下完整命令执行:
cd ~ source ~/miniconda3/etc/profile.d/conda.sh conda activate caovan-vllm rm -rf ~/caovan-vllm-sm75-turbo3-v0.4.33 unzip -o ~/caovan-vllm-sm75-turbo3-v0.4.33-external-plugin.zip -d ~/caovan-vllm-sm75-turbo3-v0.4.33 cd ~/caovan-vllm-sm75-turbo3-v0.4.33 pip install --force-reinstall dist/caovan_vllm_sm75_turbo3-0.4.33-py3-none-any.whl caovan-sm75-doctor
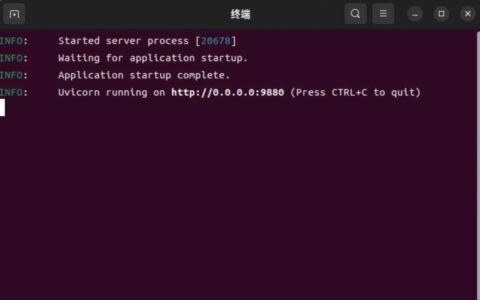
如果安装成功,终端中应该能看到类似信息:
Successfully installed caovan-vllm-sm75-turbo3-0.4.33
然后 caovan-sm75-doctor 会输出当前 Python、CUDA、GPU、Triton、vLLM、GDNCore、AutoSpec、AutoMem 等检查结果。
五、doctor 检查重点
运行:
caovan-sm75-doctor
需要重点确认以下信息。
1. 插件版本正确
应该看到:
Caovan vLLM SM75 Turbo3 external plugin v0.4.33
如果这里仍然显示旧版本,比如 v0.4.22、v0.4.28、v0.4.30、v0.4.32,说明当前环境中插件没有正确覆盖安装。
2. GPU 架构识别正确
应该能看到类似:
gpu0=NVIDIA GeForce RTX 2080 Ti, capability=(7, 5) gpu1=NVIDIA GeForce RTX 2080 Ti, capability=(7, 5)
其中 capability=(7, 5) 就是 SM75。
3. vLLM 状态正常
应该看到:
vLLM 状态:PASS
如果 vLLM 导入失败,通常说明当前 Conda 环境不对,或者 vLLM 没有正确安装。
4. GDN 接口检查通过
v0.4.33 会自动检查 vLLM 内部 GDN 路径。不同 vLLM 版本内部目录可能不同,所以某个候选路径跳过并不一定是错误。
常见正常情况类似:
GDN 候选路径:跳过 modular-qwen-gdn-v021 GDN 接口检查:PASS family=legacy-gdn-linear-attn-v020
只要最终有 PASS 路径接管,就说明正常。
5. GDNCore 检查通过
v0.4.33 的核心是 Caovan GDNCore Real Prefill AcceptanceLock Iota。doctor 中应该显示类似:
Caovan GDNCore:PASS GDNCore backend=caovan_gdncore GDNCore external_gdn_kernel_dependency=none GDNCore tilelang=not required GDNCore runtime_cuda_extension=not required
这说明 v0.4.33 不依赖 FlashQLA、TileLang 或外部 GDN runtime extension。
6. AutoSpec 结果保持 MTP=3
在 2×RTX 2080Ti 22G 环境中,推荐保持 MTP=3:
AutoSpec 结果:MTP=3
这里不建议使用 MTP=4。虽然 MTP=4 在某些情况下可以提高速度,但在 2×2080Ti 22G 上容易带来 OOM 风险。v0.4.33 的路线是保持 MTP=3,通过底层 GDNCore 和 decode path 优化提高效率,而不是用 MTP=4 硬拉速度。
六、启动 vLLM 服务
确认 doctor 正常后,可以使用以下命令启动服务:
cd ~
source ~/miniconda3/etc/profile.d/conda.sh
conda activate caovan-vllm
export CUDA_VISIBLE_DEVICES=0,1
export OMP_NUM_THREADS=12
export PYTORCH_CUDA_ALLOC_CONF=expandable_segments:True
export PYTORCH_NVML_BASED_CUDA_CHECK=1
export CAOVAN_REQUIRE_TURBO3=1
export CAOVAN_CACHE_DIR="${XDG_CACHE_HOME:-$HOME/.cache}/caovan-sm75-turbo3"
unset CAOVAN_FLASHQLA_PRECOMPILE
unset CAOVAN_FLASHQLA_FORCE
unset CAOVAN_FLASHQLA_DISABLE
export TORCHINDUCTOR_CACHE_DIR="${XDG_CACHE_HOME:-$HOME/.cache}/torchinductor"
export TORCHINDUCTOR_COMPILE_THREADS=1
export TRITON_CACHE_AUTOTUNING=1
export TRITON_PTXAS_PATH=/usr/local/cuda/bin/ptxas
caovan-vllm-serve /data/qwen/Qwen3.6-27B-AWQ-INT4 \
--host 0.0.0.0 \
--port 8000 \
--served-model-name Qwen3.6-27B-AWQ-INT4 \
--tensor-parallel-size 2 \
--dtype half \
--max-model-len 262144 \
--max-num-seqs 2 \
--max-num-batched-tokens 8192 \
--kv-cache-dtype fp8 \
--disable-custom-all-reduce \
--enable-prefix-caching \
--mamba-cache-mode align \
--additional-config '{"caovan":true,"caovan_mode":"auto","caovan_require_turbo3":true}' \
--reasoning-parser qwen3 \
--enable-auto-tool-choice \
--tool-call-parser qwen3_coder
七、启动参数说明
CUDA_VISIBLE_DEVICES
export CUDA_VISIBLE_DEVICES=0,1
表示只使用 GPU0 和 GPU1 两张显卡。
如果你的机器中有 4 张显卡,但只希望 vLLM 使用前两张,就保持这个设置。
OMP_NUM_THREADS
export OMP_NUM_THREADS=12
用于控制 CPU 线程数量,避免 CPU 线程过度争抢。
PYTORCH_CUDA_ALLOC_CONF
export PYTORCH_CUDA_ALLOC_CONF=expandable_segments:True
用于缓解 PyTorch CUDA 内存碎片问题。
CAOVAN_REQUIRE_TURBO3
export CAOVAN_REQUIRE_TURBO3=1
表示要求启用 Caovan Turbo3 插件。如果插件没有正确启用,应尽早暴露问题。
CAOVAN_CACHE_DIR
export CAOVAN_CACHE_DIR="${XDG_CACHE_HOME:-$HOME/.cache}/caovan-sm75-turbo3"
用于指定 Caovan 插件缓存目录。
unset FlashQLA 相关变量
unset CAOVAN_FLASHQLA_PRECOMPILE unset CAOVAN_FLASHQLA_FORCE unset CAOVAN_FLASHQLA_DISABLE
v0.4.33 不依赖 FlashQLA,因此这里清理掉旧版本可能遗留的 FlashQLA 环境变量,避免混淆。
TORCHINDUCTOR_CACHE_DIR
export TORCHINDUCTOR_CACHE_DIR="${XDG_CACHE_HOME:-$HOME/.cache}/torchinductor"
用于指定 TorchInductor 缓存目录。
TRITON_PTXAS_PATH
export TRITON_PTXAS_PATH=/usr/local/cuda/bin/ptxas
确保 Triton 使用正确的 ptxas。
–tensor-parallel-size 2
--tensor-parallel-size 2
表示模型使用两张显卡做 tensor parallel。
–max-model-len 262144
--max-model-len 262144
表示最大上下文长度为 262144。
如果你的显存、模型、并发或使用场景不同,这个参数需要谨慎调整。
–max-num-seqs 2
--max-num-seqs 2
表示最多同时处理 2 个序列。
–max-num-batched-tokens 8192
--max-num-batched-tokens 8192
控制 batch token 上限。
–kv-cache-dtype fp8
--kv-cache-dtype fp8
使用 FP8 KV cache,降低显存压力。
–mamba-cache-mode align
--mamba-cache-mode align
用于 GDN / Mamba 相关路径的 cache 对齐。
–additional-config
--additional-config '{"caovan":true,"caovan_mode":"auto","caovan_require_turbo3":true}'
这是 Caovan 插件的关键配置。一般用户不需要额外手写 MTP 或 gpu_memory_utilization,插件会通过 AutoSpec 和 AutoMem 自动处理。
八、如何判断 v0.4.33 是否真正生效
启动后重点看日志。
1. 确认插件启用
应该看到类似:
Caovan SM75 Turbo3
或者:
caovan_mode=auto
2. 确认 MTP=3
应该看到:
speculative_config=auto MTP=3
如果显示 MTP=4,不符合 v0.4.33 的推荐路线。2×RTX 2080Ti 22G 不建议默认使用 MTP=4。
3. 确认 GDNCore real-prefill 生效
真实请求后应该出现:
[Caovan GDNCore] ACTIVE REAL PREFILL
这说明 Caovan GDNCore 已经进入真实 prefill 路径,而不是只停留在 selftest 或 doctor 检查阶段。
4. 确认 decode path
v0.4.33 应该回到 acceptance-locked split-QK 路线。日志中重点看类似:
Caovan SM75 Turbo3 ACTIVE DISPATCH confirmed
如果看到 v0.4.32 的 single-launch 路线,说明版本或环境变量可能混用了。
5. 观察吞吐速度
在测试环境中,v0.4.33 的目标是恢复到 80+ tokens/s,并尽量稳定在 88–92 tokens/s 区间。
日志中可能看到类似:
Avg generation throughput: 88 tokens/s Avg generation throughput: 90 tokens/s Avg generation throughput: 92 tokens/s
不同 prompt、上下文长度、输出长度、并发状态都会影响速度,所以不要只看单个瞬时值,要看一段时间内的稳定区间。
6. 观察 Draft acceptance rate
v0.4.33 的一个重点是保护 speculative decoding 接受率。日志中可以关注:
Avg Draft acceptance rate
如果接受率长期低于预期,说明 decode path、prompt 类型或底层 kernel 可能影响了 MTP 接受率。
v0.4.33 的 AcceptanceLock 思路就是为了避免 v0.4.32 那种“kernel launch 减少了,但接受率下降、最终速度变慢”的问题。
九、测试 API 是否正常
服务启动后,可以在另一个终端测试接口:
curl http://127.0.0.1:8000/v1/models
如果服务正常,应该能看到模型列表。
也可以测试对话接口:
curl http://127.0.0.1:8000/v1/chat/completions \
-H "Content-Type: application/json" \
-d '{
"model": "Qwen3.6-27B-AWQ-INT4",
"messages": [
{"role": "user", "content": "请用三句话介绍一下你自己。"}
],
"max_tokens": 256,
"temperature": 0.7
}'
如果返回正常文本,说明接口可用。
十、v0.4.33 相比 v0.4.22 的核心变化
1. 从参数自动化走向底层 GDNCore 接管
v0.4.22 的重点是 AutoSpec、DynamicTP、AutoMem、Elastic-KV 等自动化启动画像能力。
v0.4.33 在此基础上进一步启用 Caovan GDNCore real-prefill,让插件真正进入 GDN prefill 热路径。
2. 不再依赖 FlashQLA / TileLang / 外部 GDN kernel
v0.4.33 的 GDNCore 路线不需要 FlashQLA,不需要 TileLang,也不需要外部 runtime CUDA extension。
这可以减少用户安装复杂度,也降低不同用户环境中出现兼容性问题的概率。
3. 固定 MTP=3,避免 MTP=4 OOM
2×RTX 2080Ti 22G 上,MTP=4 虽然可能提高速度,但更容易 OOM。
v0.4.33 的思路是:
MTP=3 不变 显存压力不增加 通过底层计算路径优化提速
4. 引入 AcceptanceLock
v0.4.33 不盲目追求 kernel fusion,而是保护 speculative decoding 的 draft acceptance rate。
它保留 split-QK + fused V/GDN 路线,避免 v0.4.32 中 single-launch 路线造成接受率下降的问题。
5. 更适合作为阶段性稳定版本
v0.4.33 同时具备:
GDNCore real-prefill MTP=3 稳定路线 AutoMem / Elastic-KV 外部 GDN 依赖清理 AcceptanceLock decode path 较高 draft acceptance 较稳定 tokens/s
因此可以作为 v0.4.22 之后的阶段性新版本。
十一、常见问题
问题 1:doctor 里跳过 modular-qwen-gdn-v021 是不是错误?
不一定。
vLLM 不同版本内部目录结构可能不同。只要后面有 legacy GDN 路径 PASS,就说明插件已经找到可接管路径。
问题 2:为什么不用 MTP=4?
因为 2×RTX 2080Ti 22G 上 MTP=4 容易 OOM。
v0.4.33 的目标不是用更高 MTP 参数硬拉速度,而是在 MTP=3 下通过 GDNCore 和 decode path 优化效率。
问题 3:为什么 v0.4.33 不依赖 FlashQLA?
FlashQLA 是很重要的 Qwen Linear Attention / GDN prefill kernel 项目,对本项目早期路线有参考价值。
但 v0.4.33 的目标是面向 SM75 / 2080Ti 用户分发一个更低依赖、更可控的插件。因此当前版本选择自研 Caovan GDNCore,不再把 FlashQLA / TileLang / 外部 GDN runtime 作为直接依赖。
问题 4:为什么不继续使用 v0.4.32 的 single-launch 路线?
因为实测发现,single-launch 虽然减少了一次 kernel launch,但会降低 speculative decoding 的接受率,最终速度反而下降。
v0.4.33 恢复 split-QK + fused V/GDN,是为了保护 MTP acceptance。
问题 5:启动后第一次很慢怎么办?
第一次启动可能会触发 Triton / TorchInductor / vLLM 的编译和缓存构建。
建议确认以下目录是否有写入权限:
echo $CAOVAN_CACHE_DIR echo $TORCHINDUCTOR_CACHE_DIR
如果缓存目录正常,后续启动通常会更快。
问题 6:如何确认不是旧版本残留?
执行:
python - <<'PY'
import caovan_vllm_sm75_turbo3 as p
print("version =", p.__version__)
print("file =", p.__file__)
PY
应该输出:
version = 0.4.33
如果版本不对,需要重新安装 wheel。
十二、回滚到旧版本
如果需要临时回滚到 v0.4.22,可以重新安装 v0.4.22 的 wheel。
示例:
cd ~/caovan-vllm-sm75-turbo3-v0.4.22 pip install --force-reinstall dist/caovan_vllm_sm75_turbo3-0.4.22-py3-none-any.whl caovan-sm75-doctor
回滚后再次启动服务即可。
十三、总结
Caovan vLLM SM75 Turbo3 v0.4.33 是一个重要的阶段性版本。
它相比 v0.4.22 的核心变化不是简单改参数,而是把优化推进到底层 GDNCore 和 decode path:
自研 GDNCore Real Prefill AcceptanceLock Iota MTP=3 稳定路线 split-QK + fused V/GDN 不依赖 FlashQLA / TileLang / 外部 GDN kernel 不使用 MTP=4 硬拉速度
对于 2×RTX 2080Ti 22G 用户来说,v0.4.33 的意义在于:在不明显增加显存风险的情况下,进一步提高 Qwen3.6-27B-AWQ-INT4 的真实推理效率,并为后续继续开发 key-head grouped decode kernel、V/GDN tile 几何优化等底层路径打下基础。
如果你正在使用 v0.4.22,并且希望测试新的 GDNCore real-prefill 和 AcceptanceLock 路线,可以按照本文教程升级到 v0.4.33。
原创文章,作者:朋远方,如若转载,请注明出处:https://caovan.com/caovan-vllm-sm75-turbo3-v0433-install-guide/.html
 微信扫一扫
微信扫一扫 




评论列表(11条)
大佬,请教下,我怕oom,添加了–kv-offloading-backend native –kv-offloading-size 16参数,好像和插件自带参数冲突了,插件有这种防oom的机制吗?
@1801:这个情况大概率不是“插件有防 OOM 机制”和 –kv-offloading-backend native –kv-offloading-size 16 冲突,而是这两个参数会改变 vLLM 的 KV Cache 内存分配逻辑,和插件自动注入的 AutoMem / Elastic-KV 显存预算不是同一个假设。
推荐参数,是按 2×2080Ti 22G + Qwen3.6-27B-AWQ-INT4 + MTP=3 + KV 常驻 GPU/FP8 KV Cache 这套形态来设计的。也就是说,插件会自动做显存预留、MTP 风险控制和 KV 预算保护。
如果再额外叠加:
–kv-offloading-backend native
–kv-offloading-size 16
就相当于又启用了 vLLM 原生 KV offloading 机制。它理论上可以减少一部分 GPU KV 压力,但也会引入 CPU 内存、pinned memory、PCIe 传输、KV 分块调度等额外变量,不一定能解决 OOM,反而可能让插件的 AutoMem / Elastic-KV 预算判断失准。
建议先不要加这两个参数,直接按文章里的原始启动命令跑通。如果仍然 OOM,再优先从这些参数降级排查:
–max-model-len
–max-num-seqs
–max-num-batched-tokens
比如先保持:
–max-num-seqs 2
–max-num-batched-tokens 8192
–kv-cache-dtype fp8
不要额外加 KV offloading。
如果方便的话,把完整启动命令、caovan-sm75-doctor 输出,以及 OOM 前后最后 100 行日志贴出来分析分析。
有没有打到vllm0.21.0官方docker里的教程
@l411:暂时没有,插件是在纯Ubuntu 系统环境中开发的,目前没有适配docker 的版本
大佬我的双2080TI 44G Qwen3.6-27B-AWQ-INT4 256K 一读本地文件就卡住了,vllm服务正常,其他会话也正常。请问你们有这种情况吗?
@1126:读本地文件指的是加载模型吗?
可以推理其他模型吗,脚本该如何调整?
wsl可以使用不?有没有windows方案
@5993:该插件只对纯Ubuntu系统有效,目前还没有推出Windows方案!
大佬,请问这个配置下,prefill速度高吗?首字延迟大吗?
@john:新版本v0.4.35文章中对prefill做了专门的测试和解答:
https://caovan.com/caovan-vllm-sm75-turbo3-v0435-rtx-2080ti-guide/.html