


这篇教程面向没有 Linux 部署经验的新手用户,从一台空白 Ubuntu 22.04 机器开始,逐步安装 Miniconda、创建 Python 环境、安装 vLLM 与 Caovan vLLM SM75 Turbo3 external plugin,最后用 RTX 2080Ti 显卡启动 Qwen3.6-27B-AWQ-INT4 模型服务。
(本插件已经升级到v0.4.33版,最新版下载插件下载地址和升级方法请参考最新文章《caovan-vLLM SM75 Turbo3 v0.4.22 升级到 v0.4.33》)
插件最新版本为:
caovan-vllm-sm75-turbo3-v0.4.13-external-plugin.zip

目前实测插件能够支持的模型:
Huihui-Qwen3.6-27B-abliterated-int4-AutoRound
Qwen3.6-27B-heretic-v2-mtp-int4-AutoRound
一、插件能做什么?
Caovan vLLM SM75 Turbo3 是面向 NVIDIA RTX 2080Ti / SM75 架构的 vLLM 外部加速插件。它不会要求用户手动填写复杂底层参数,而是通过启动器 caovan-vllm-serve 自动完成硬件探测和参数注入。
- 自动检测 GPU 数量、SM 架构、TP 并行数、上下文长度与显存水位。
- 自动配置 MTP 推测解码参数。
- 自动配置 GMU,即
gpu_memory_utilization。 - 自动注入 PIECEWISE CUDA Graph 编译策略。
- 自动启用 Elastic-KV 显存安全预留。
- 2 张 GPU 默认使用 MTP=3,超过 2 张 GPU 默认使用 MTP=4。
- 保留外部插件形态,不需要修改模型文件。
二、本文测试环境
| 项目 | 测试配置 |
|---|---|
| 操作系统 | Ubuntu 22.04 LTS |
| 显卡 | NVIDIA RTX 2080Ti 22GB,SM75 架构,2 卡测试为主 |
| Python | ≥Python 3.10.20 |
| vLLM | vLLM 0.21.0,配套本地 wheel |
| 插件版本 | caovan-vllm-sm75-turbo3 v0.4.13 |
| 测试模型 | /data/qwen/Qwen3.6-27B-AWQ-INT4 |
| KV Cache | fp8 |
| 上下文长度 | 262144 |
重要说明:本插件当前已验证的环境是 ≥Python 3.10.20。
三、下载本文插件安装包
插件包:
caovan-vllm-sm75-turbo3-v0.4.13-external-plugin.zip
请把插件包下载下来后放到用户主目录 ~/ 下:
cd ~ ls -lh ~/caovan-vllm-sm75-turbo3-v0.4.13-external-plugin.zip

模型文件建议放在:
/data/qwen/Qwen3.6-27B-AWQ-INT4
如果你的模型目录不同,后面的启动命令中把模型路径替换成自己的路径即可。
四、安装 NVIDIA 驱动与基础工具
先更新系统并安装基础工具:
sudo -v sudo apt update sudo apt install -y build-essential git wget curl unzip pciutils ca-certificates
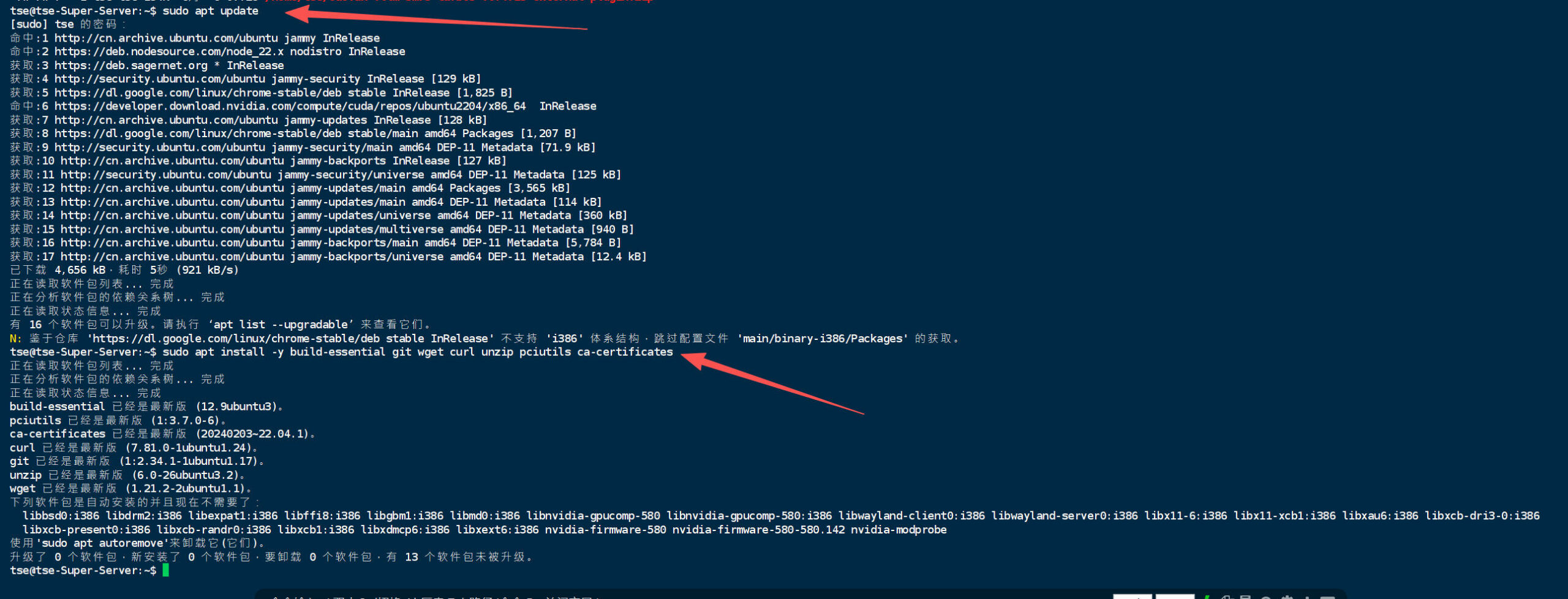
查看显卡是否被系统识别:
lspci | grep -i nvidia
安装 NVIDIA 驱动。CUDA 13.x 对 Linux 驱动版本要求较高,建议使用 580 或更高版本驱动。不同 Ubuntu 软件源中的驱动包名可能不同,请以你机器上 ubuntu-drivers devices 显示的推荐版本为准。
ubuntu-drivers devices sudo apt install -y nvidia-driver-580 sudo reboot
重启后验证:
nvidia-smi
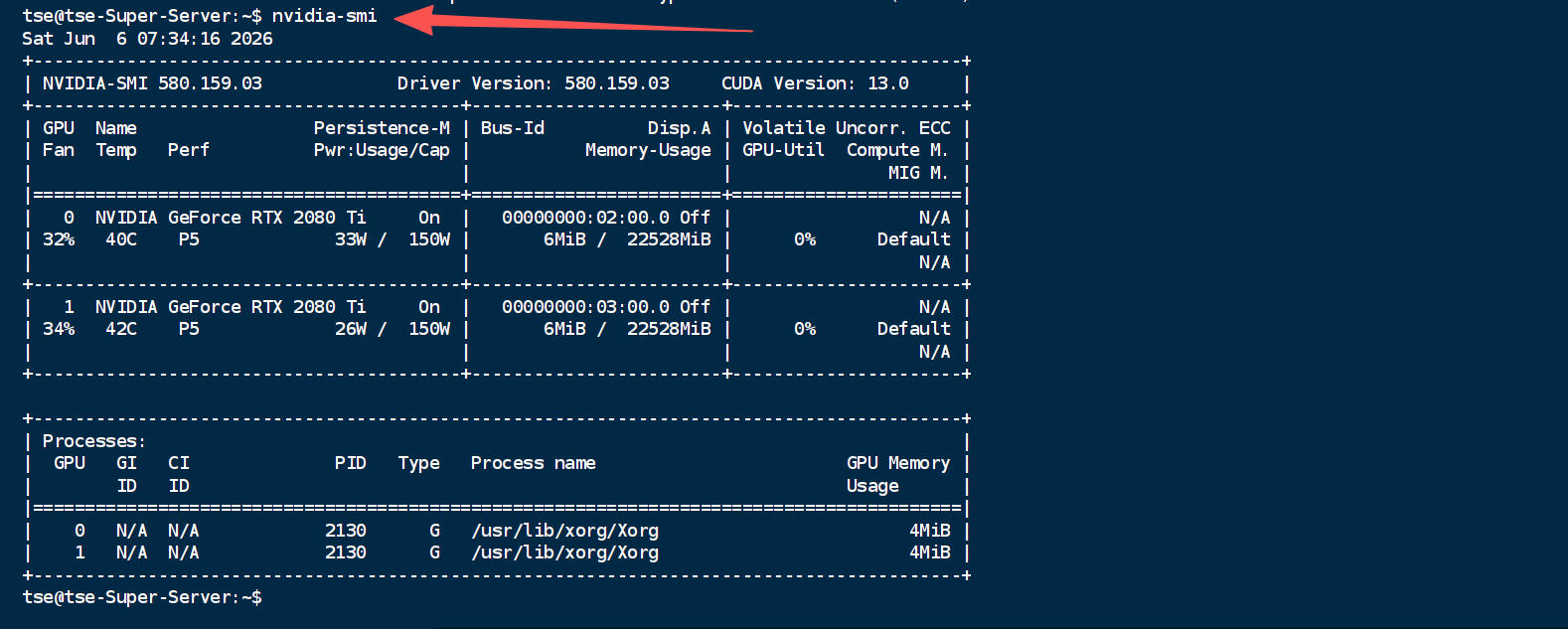
如果 nvidia-smi 能正常显示 RTX 2080Ti、驱动版本、显存信息,就可以继续下一步。
五、安装 Miniconda
下载并安装 Miniconda:
cd ~ wget -O Miniconda3-latest-Linux-x86_64.sh \ https://repo.anaconda.com/miniconda/Miniconda3-latest-Linux-x86_64.sh bash Miniconda3-latest-Linux-x86_64.sh -b -p "$HOME/miniconda3" source "$HOME/miniconda3/etc/profile.d/conda.sh" conda init bash
重新打开终端,或者执行:
source ~/miniconda3/etc/profile.d/conda.sh conda --version

六、创建专用 Conda 环境
创建专用环境。这里固定使用 Python 3.10.20:
source ~/miniconda3/etc/profile.d/conda.sh conda create -n caovan-vllm python=3.10.20 pip setuptools wheel -y

conda activate caovan-vllm

python -V

正确输出应类似:
Python 3.10.20
七、安装 vLLM 0.21.0
进入环境后,通过 pip 安装 vLLM 0.21.0
python -m pip install --upgrade pip setuptools wheel
python -m pip install "vllm==0.21.0"

如果你在国内网络环境下安装速度较慢,可以临时使用常见 pip 镜像源,例如:
python -m pip install "vllm==0.21.0" -i https://mirrors.aliyun.com/pypi/simple/
安装完成后检查:
python - <<'PY'
import sys
import vllm
print("python:", sys.version.split()[0])
print("vllm:", vllm.__version__, vllm.__file__)
PY

推荐看到:
python: 3.10.20 ... vllm: 0.21.0 ...
八、安装 Caovan vLLM SM75 Turbo3 插件
解压并安装草凡插件:
cd ~ unzip -o ~/caovan-vllm-sm75-turbo3-v0.4.13-external-plugin.zip -d ~
python -m pip install --upgrade --force-reinstall --no-deps \ ~/caovan-vllm-sm75-turbo3-v0.4.13/dist/caovan_vllm_sm75_turbo3-0.4.13-py3-none-any.whl

检查插件版本:
python - <<'PY'
import sys
import importlib.metadata as md
import caovan_vllm_sm75_turbo3
print("python:", sys.version.split()[0])
print("caovan import version:", caovan_vllm_sm75_turbo3.__version__)
print("caovan metadata version:", md.version("caovan-vllm-sm75-turbo3"))
PY

正常输出应包含:
caovan import version: 0.4.13 caovan metadata version: 0.4.13
如果需要卸载该插件,可以运行如下的命令:
python -m pip uninstall -y caovan-vllm-sm75-turbo3 caovan_vllm_sm75_turbo3 rm -rf ~/caovan-vllm-sm75-turbo3-v0.4.13 echo "==== 检查插件是否已卸载 ====" python - <<'PY' try: import caovan_vllm_sm75_turbo3 print("插件仍存在:", caovan_vllm_sm75_turbo3.__file__) except Exception as e: print("插件已卸载:", e) PY echo echo "==== 检查命令是否还存在 ====" command -v caovan-vllm-serve || echo "caovan-vllm-serve 已不存在" command -v caovan-sm75-doctor || echo "caovan-sm75-doctor 已不存在"
九、运行 doctor 检查
先运行基础检查:
caovan-sm75-doctor
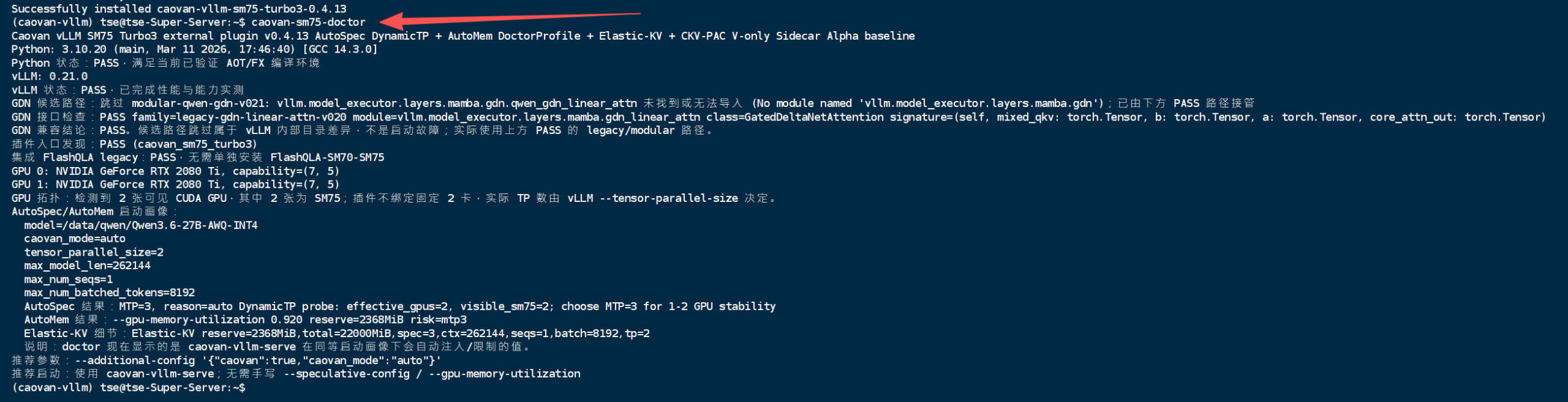
也可以带上实际模型和启动参数,让 doctor 预估 AutoSpec / AutoMem 的结果:
caovan-sm75-doctor /data/qwen/Qwen3.6-27B-AWQ-INT4 \ --tensor-parallel-size 2 \ --max-model-len 262144 \ --max-num-seqs 1 \ --max-num-batched-tokens 8192
重点看这些信息:
Python 状态:PASSvLLM 状态:PASSGDN 接口检查:PASSGPU 拓扑中能看到 RTX 2080Ti / SM75- AutoSpec 结果会显示插件准备自动使用的 MTP 参数
- AutoMem 结果会显示插件准备自动注入的
gpu_memory_utilization
如果看到某个候选 GDN 新路径被跳过,但最终 legacy-gdn-linear-attn-v020 是 PASS,这属于正常兼容路径,不是故障。
十、启动 2 卡推理服务
下面是 2 张 RTX 2080Ti 的推荐启动命令。注意:不要手写 --speculative-config,也不要手写 --gpu-memory-utilization,这两个参数交给插件自动配置。
export CUDA_VISIBLE_DEVICES=0,1
export OMP_NUM_THREADS=12
export PYTORCH_CUDA_ALLOC_CONF=expandable_segments:True
export PYTORCH_NVML_BASED_CUDA_CHECK=1
export TORCHINDUCTOR_CACHE_DIR="${XDG_CACHE_HOME:-$HOME/.cache}/torchinductor"
export TORCHINDUCTOR_COMPILE_THREADS=1
export TRITON_CACHE_AUTOTUNING=1
export TRITON_PTXAS_BLACKWELL_PATH=/usr/local/cuda/bin/ptxas
caovan-vllm-serve /data/qwen/Qwen3.6-27B-AWQ-INT4 \
--host 0.0.0.0 \
--port 8000 \
--served-model-name Qwen3.6-27B-AWQ-INT4 \
--tensor-parallel-size 2 \
--dtype half \
--max-model-len 262144 \
--max-num-seqs 1 \
--max-num-batched-tokens 8192 \
--kv-cache-dtype fp8 \
--disable-custom-all-reduce \
--enable-prefix-caching \
--mamba-cache-mode align \
--enable-flashinfer-autotune \
--additional-config '{"caovan":true,"caovan_mode":"auto"}' \
--reasoning-parser qwen3 \
--enable-auto-tool-choice \
--tool-call-parser qwen3_coder
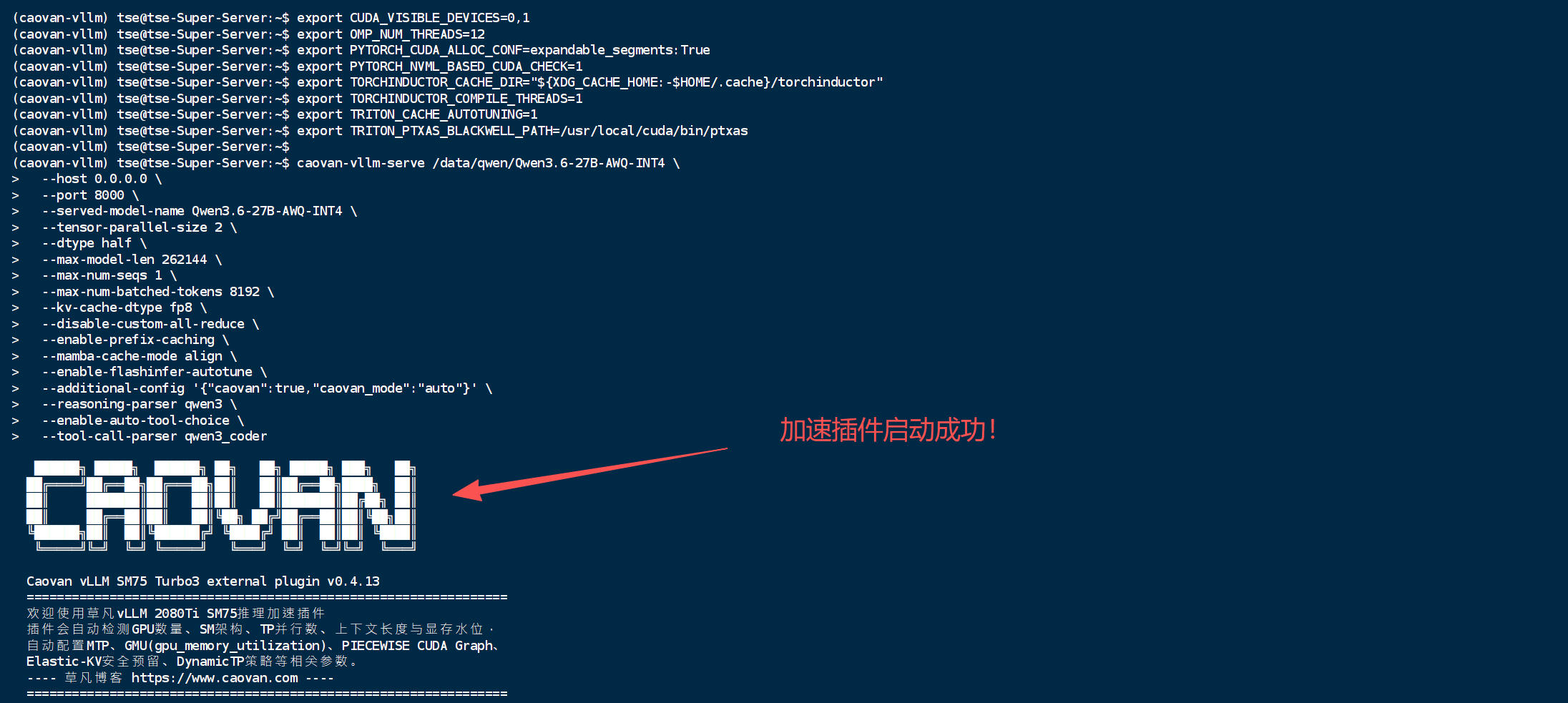

启动成功时会看到 CAOVAN logo,并显示自动配置结果。2 卡情况下,插件会自动采用:
DynamicTP: effective_gpus=2 AutoSpec: MTP=3 AutoMem: 自动注入 gpu_memory_utilization PIECEWISE CUDA Graph: 自动注入
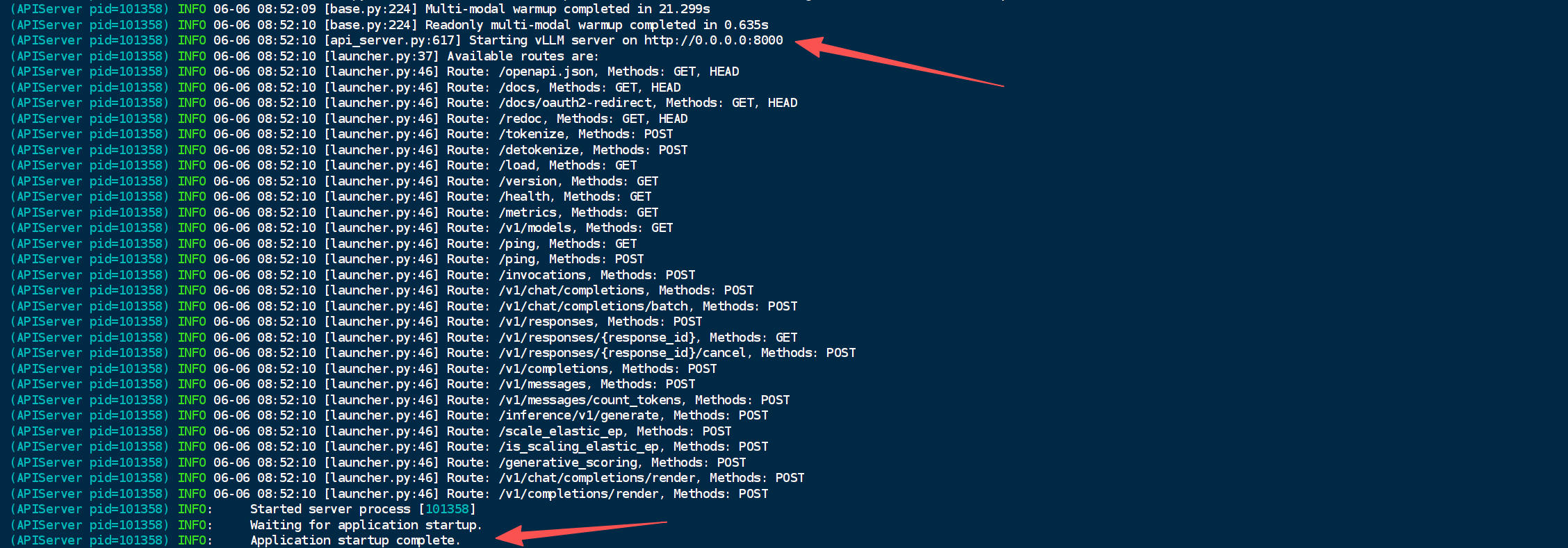
vLLM启动完成,你会看到如下的画面,看到“Starting vLLM server on http://0.0.0.0:8000”和“Application startup complete.”等内容正面vLLM已经正常启动并且对外提供api服务!
十一、用 one-api 接入api 并对外提供模型服务
关于安装和配置one-api的方法,可以参考博客中的另外一篇文章《Ubuntu22.04+4x2080Ti22G+vLLM+Qwen3.6-27B-AWQ-INT4 部署教程》中关于one-api的安装和配置等内容;
在one-api中增加一个渠道,将上面启动的模型api信息填入到渠道中
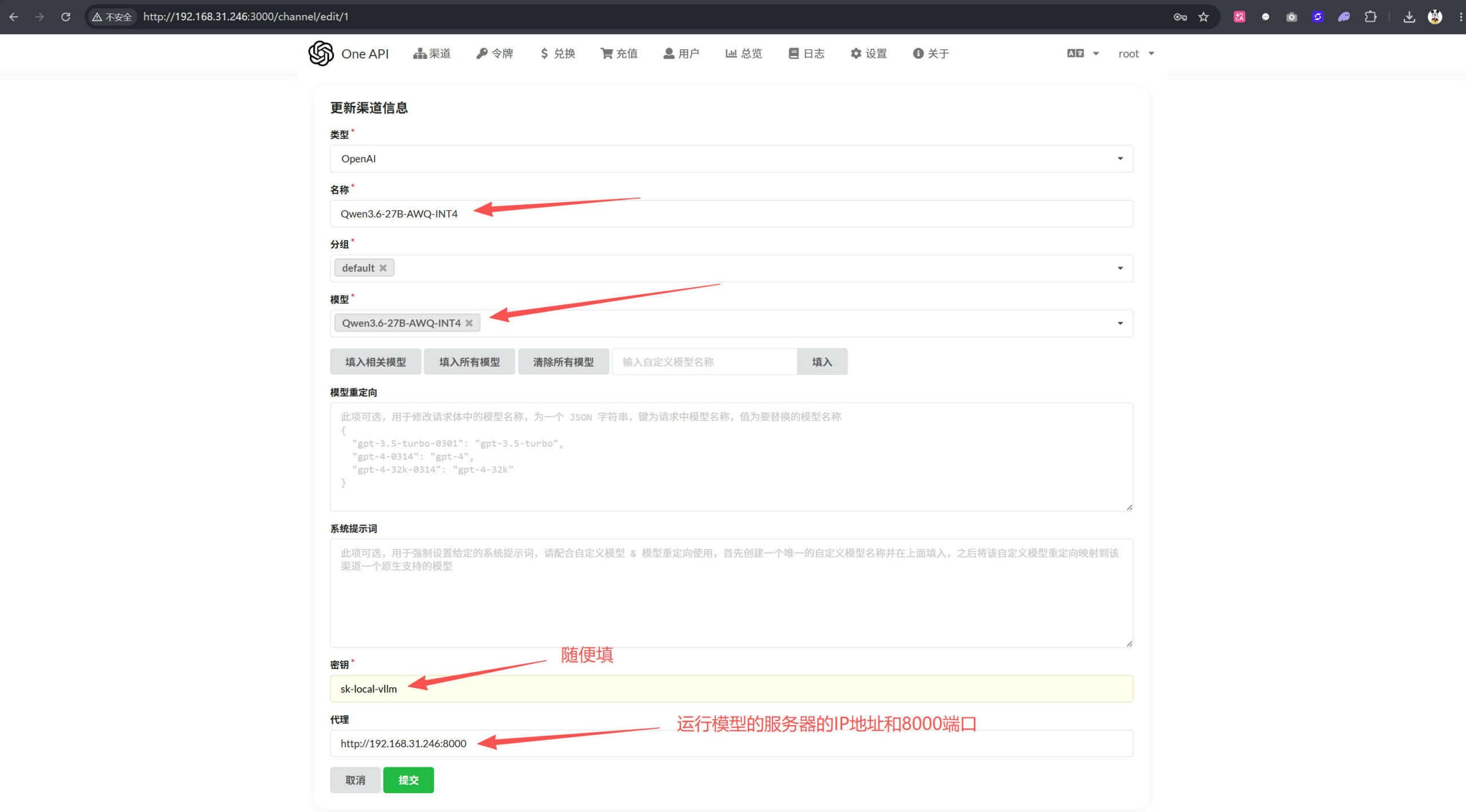
然后通过one-api分发,对外就可以提供兼容openai的模型服务!这些内容在这里不赘述!
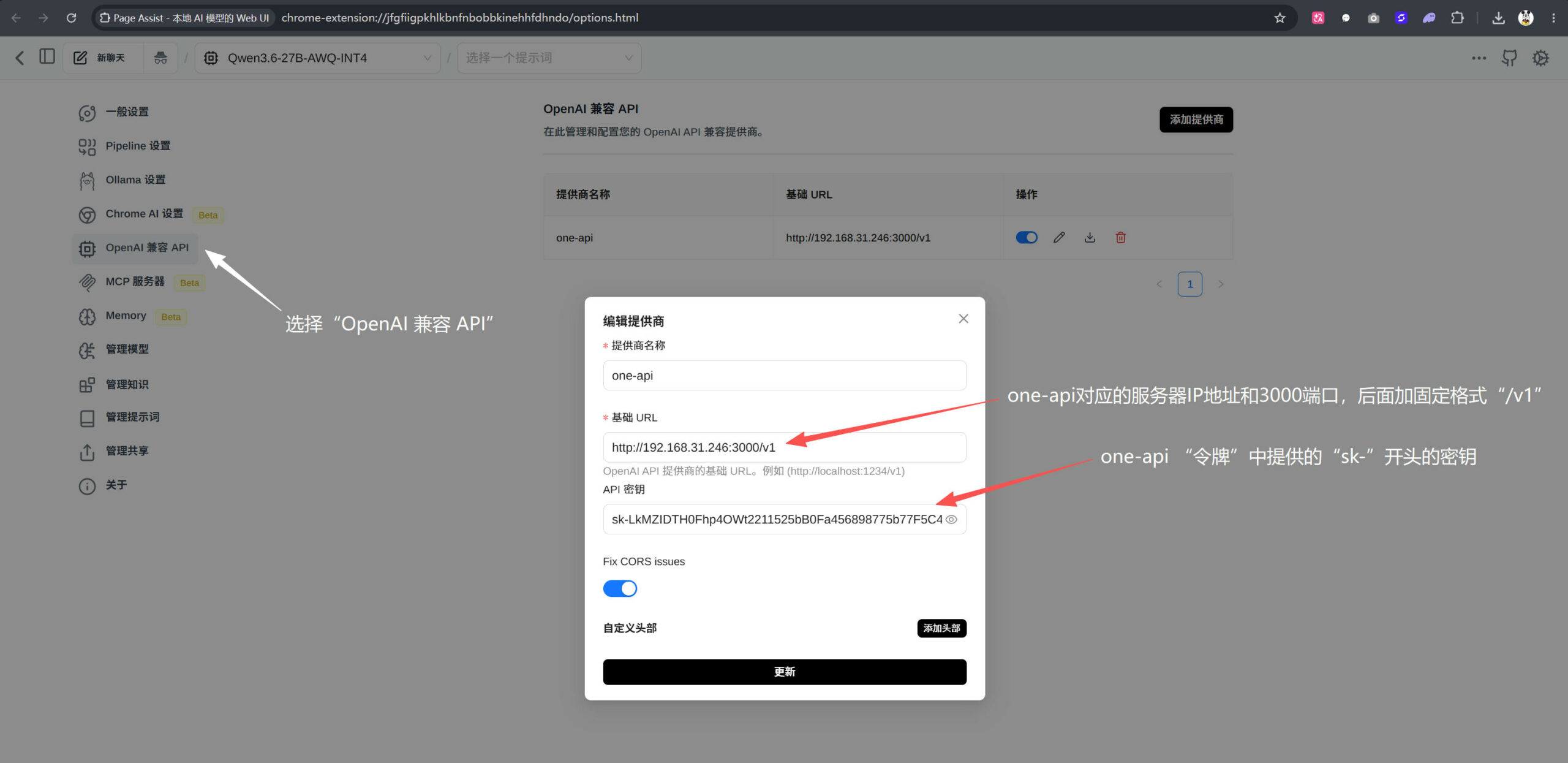
十二、用 Page Assist 接入本地模型并测试模型推理速度
下面是通过chrome浏览器插件“Page Assist”调用本地one-api中的兼容openai接口接入模型的截图
第一步:打开“Page Assist”,点击右上角的齿轮进入设置界面,选择左侧菜单中的“OpenAI 兼容 API”,点击“添加提供商”,在弹窗中根据图示设置;
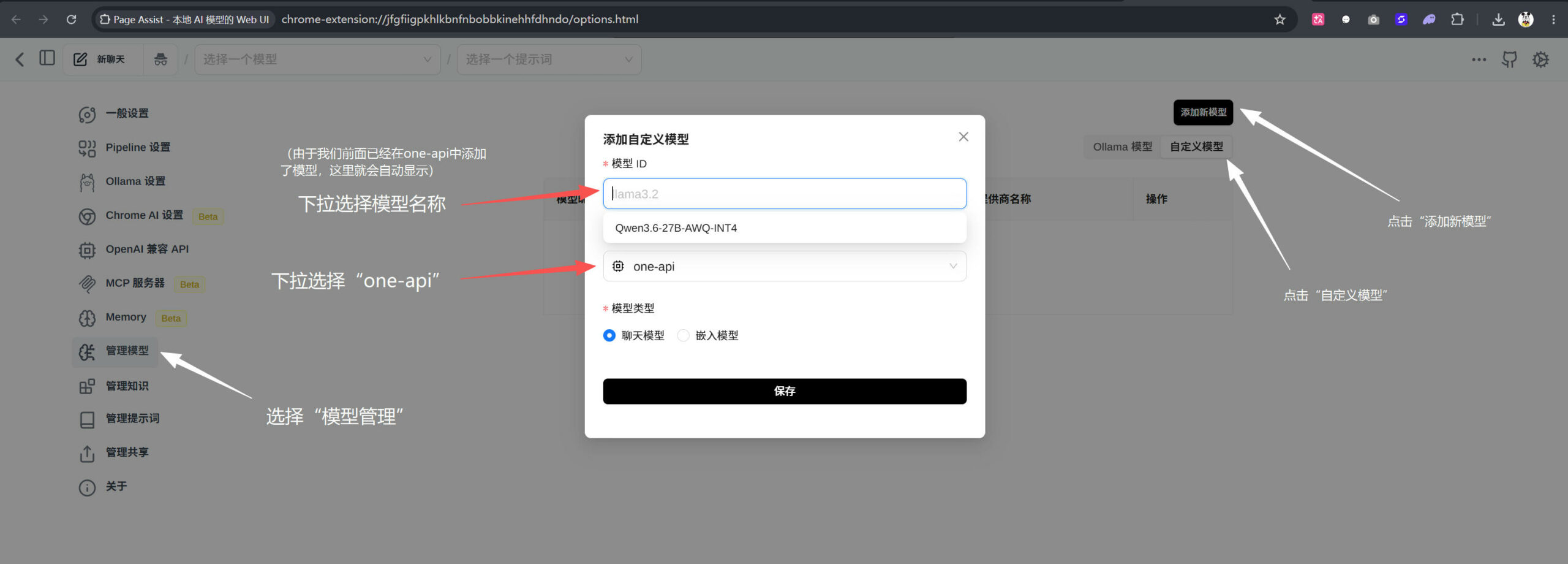
第二步:选择左侧菜单中的“模型管理”,点击“添加新模型”,选择“自定义模型”,在弹窗中参考如下的图示设置;
第三步:点击左上角的“新聊天”,下拉选择配置好的模型,开始和AI进行聊天;
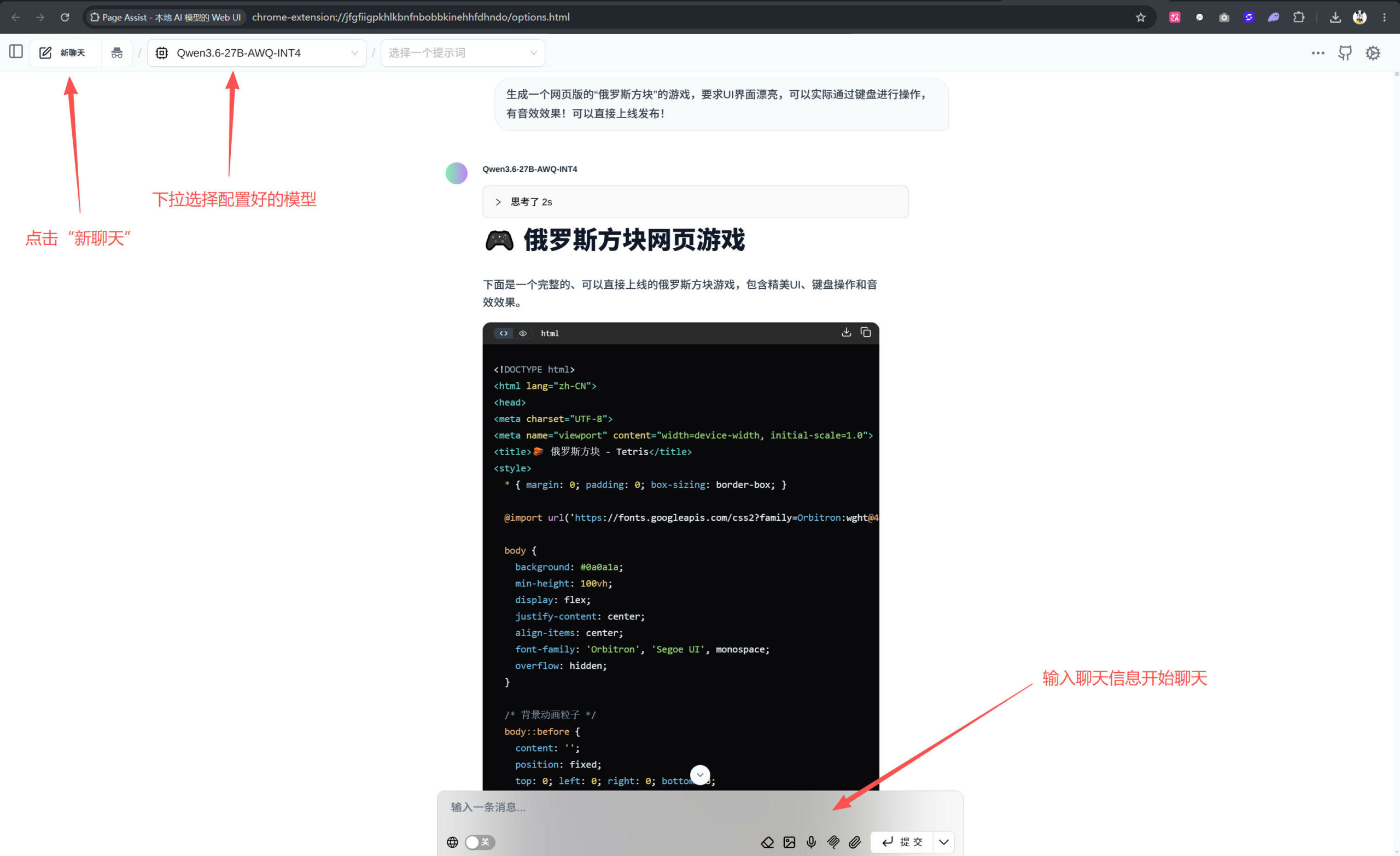
Qwen3.6-27B模型确实不错,生成的网页游戏功能完整、UI美观,可以直接玩!
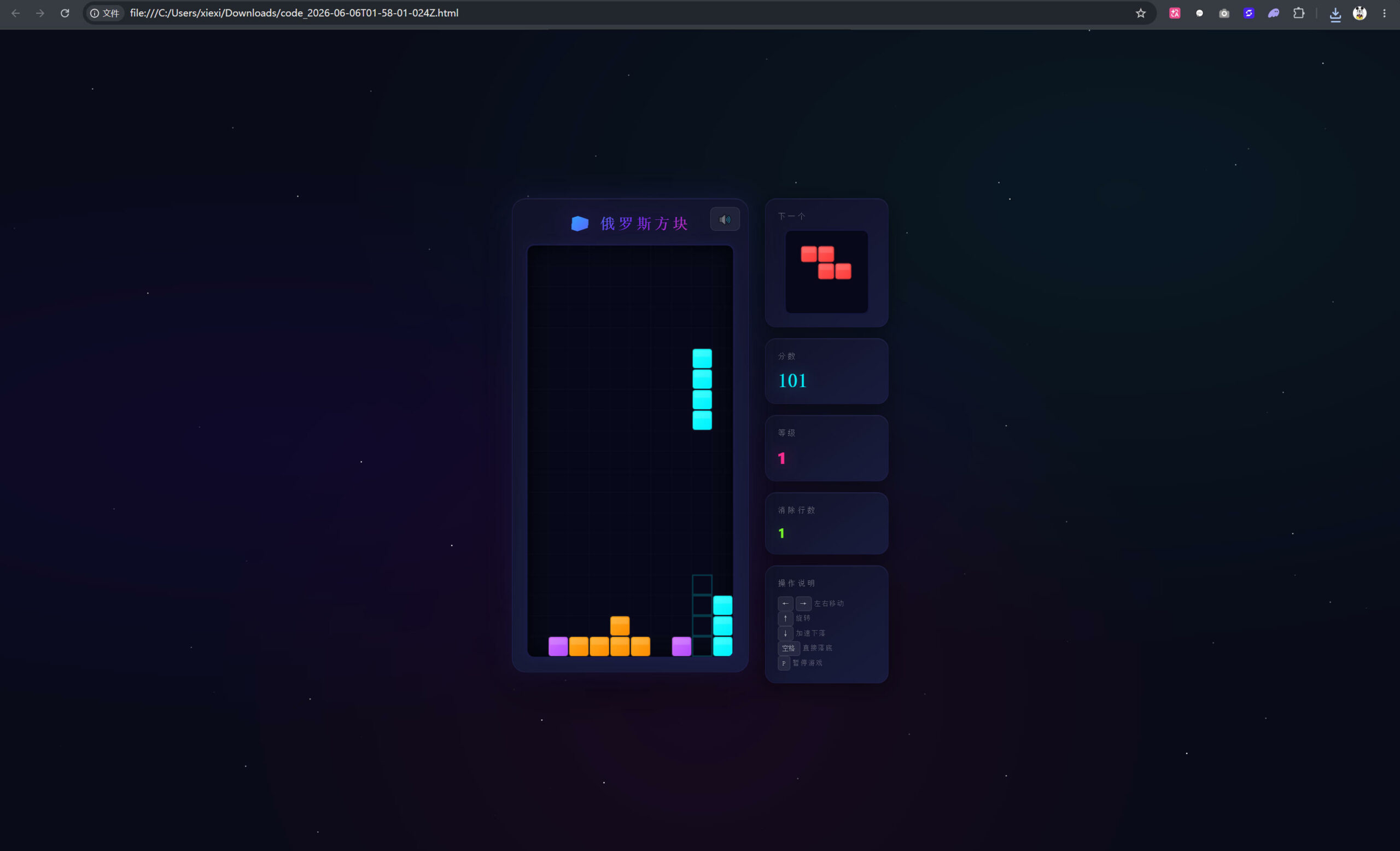
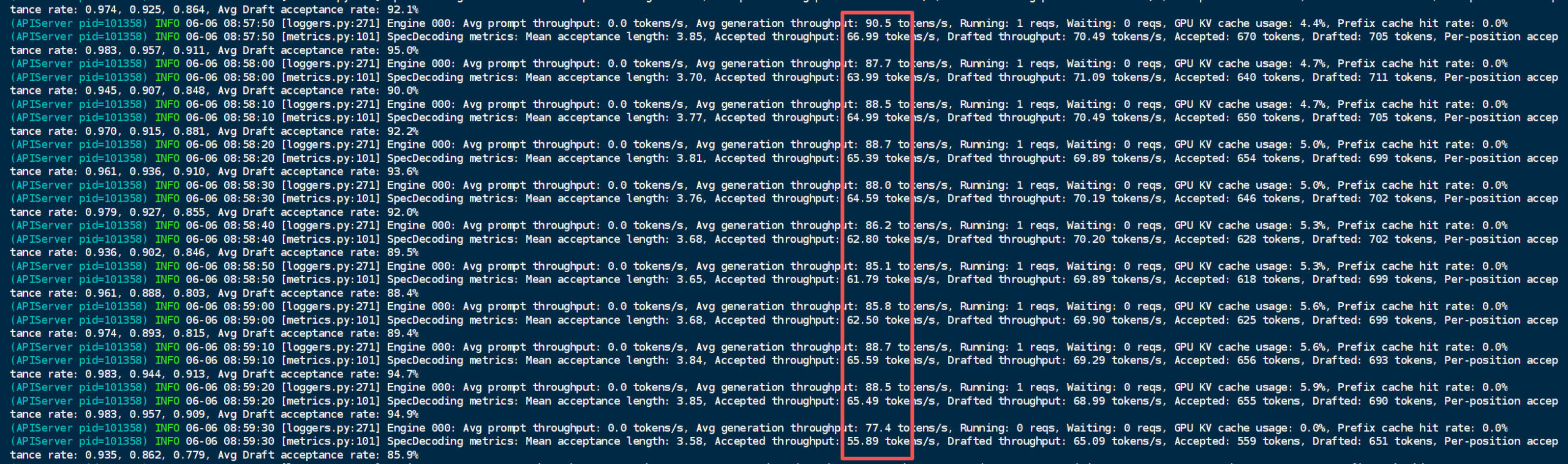
如下是博主2张2080Ti 22G+nvlink启动插件后实测的模型推理速度,从77.4 tokens/s 到 90.5 tokens/s 之间。如果用比较激进的参数,比如将”caovan_mode”的参数设置为“fast”,历史测试中的峰值速度达到105+ tokens/s,不过如果只有2张22G的显卡,不建议将”caovan_mode”的参数设置为”fast”,因为后面可能会出现由于显存不足导致的报错!
大多数情况下,”caovan_mode”的参数建议保持默认的“auto”,是比较稳定的加速状态!
caovan_mode 主要有这几类可选值:
| 参数值 | 含义 | 自动 MTP 策略 | 推荐场景 |
|---|---|---|---|
auto |
默认推荐模式,插件根据实际启动 GPU/TP 数自动选择 | 1~2 张 GPU:MTP=3;大于 2 张 GPU:MTP=4 | 普通用户默认用这个 |
stable |
稳定优先模式 | 固定 MTP=3 | 2 卡、长输出、生产稳定优先 |
fast |
速度优先模式 | 固定 MTP=4 | 想冲峰值速度,接受一定实验风险 |
十三、4 卡启动示例
如果机器有 4 张 RTX 2080Ti,可以这样启动。插件检测到 --tensor-parallel-size 4 后,会自动使用 MTP=4。
export CUDA_VISIBLE_DEVICES=0,1,2,3
export OMP_NUM_THREADS=12
export PYTORCH_CUDA_ALLOC_CONF=expandable_segments:True
export PYTORCH_NVML_BASED_CUDA_CHECK=1
export TORCHINDUCTOR_CACHE_DIR="${XDG_CACHE_HOME:-$HOME/.cache}/torchinductor"
export TORCHINDUCTOR_COMPILE_THREADS=1
export TRITON_CACHE_AUTOTUNING=1
export TRITON_PTXAS_BLACKWELL_PATH=/usr/local/cuda/bin/ptxas
caovan-vllm-serve /data/qwen/Qwen3.6-27B-AWQ-INT4 \
--host 0.0.0.0 \
--port 8000 \
--served-model-name Qwen3.6-27B-AWQ-INT4 \
--tensor-parallel-size 4 \
--dtype half \
--max-model-len 262144 \
--max-num-seqs 1 \
--max-num-batched-tokens 8192 \
--kv-cache-dtype fp8 \
--disable-custom-all-reduce \
--enable-prefix-caching \
--mamba-cache-mode align \
--enable-flashinfer-autotune \
--additional-config '{"caovan":true,"caovan_mode":"auto"}' \
--reasoning-parser qwen3 \
--enable-auto-tool-choice \
--tool-call-parser qwen3_coder
十四、插件自动参数规则
| 场景 | 自动策略 | 原因 |
|---|---|---|
| 1~2 张 GPU | 默认 MTP=3 | 2 卡 MTP=4 虽然速度很高,但长时间运行更容易触发底层异步稳定性风险。 |
| 大于 2 张 GPU | 默认 MTP=4 | 更多 GPU 通常显存与并行余量更充足,适合更激进的推测解码。 |
| 不填写 GMU | 插件自动注入 gpu_memory_utilization |
避免用户手动填写过高导致 OOM 或底层临界错误。 |
| 不填写 compilation-config | 插件自动注入 PIECEWISE CUDA Graph | 保持 vLLM_COMPILE 高速路线。 |
如果你明确要覆盖自动 MTP,可以使用环境变量:
export CAOVAN_AUTO_SPEC=3 # 或 export CAOVAN_AUTO_SPEC=4
十五、实测数据对照
下面是本轮开发中对关键路线的测试观察。不同 prompt、输出长度、显卡温度、驱动和系统环境都会影响速度,表格中的数据用于帮助理解插件策略,不代表所有机器都能完全相同。
| 测试路线 | 观察到的现象 | 结论 |
|---|---|---|
| Python 3.10.0 + vLLM_COMPILE | AOT / Torch FX 编译阶段容易出现栈深度问题 | 不推荐,教程固定 Python 3.10.20 |
| Python 3.10.20 + vLLM 0.21.0 | AOT 编译、PIECEWISE CUDA Graph 能正常通过 | 作为当前推荐基础环境 |
| 2 卡 + MTP=3 | 速度相比 MTP=4 略低,但稳定性更好 | 当前 2 卡默认策略 |
| 2 卡 + MTP=4 | 可出现 99~105 tokens/s 的高速度窗口,但长时间运行存在底层异步稳定性风险 | 不再作为 2 卡默认策略 |
| v0.4.13 DynamicTP | 根据 TP/GPU 数自动选择 MTP:2 卡 MTP=3,大于 2 卡 MTP=4 | 当前推荐对外发布策略 |
十六、常见问题
1. 看到 FA2 不支持 SM75,是不是报错?
日志里可能出现类似:
Cannot use FA version 2 is not supported due to FA2 is only supported on devices with compute capability >= 8
RTX 2080Ti 是 SM75,确实不支持 FA2。这条通常不是致命错误,vLLM 会继续选择 FlashInfer / TRITON_ATTN 等可用后端。
2. 为什么 doctor 里有 GDN 候选路径跳过?
插件会先探测多个 vLLM 内部路径。某些新路径不存在时会跳过,只要最终看到:
GDN 接口检查:PASS
就说明当前 vLLM 的 legacy GDN 路径可用。
3. 为什么不让用户自己填写 MTP?
因为 MTP 与 GPU 数量、显存余量、上下文长度、vLLM 编译形状都有关系。插件已经内置 DynamicTP 规则:2 卡默认 MTP=3,大于 2 卡默认 MTP=4。普通用户不需要手动理解这些底层参数。
4. 为什么不让用户自己填写 gpu_memory_utilization?
这个参数过高容易把 KV cache 池撑得太满,导致后续临时 buffer 没有空间。插件会根据 GPU 显存、上下文长度、MTP、TP 并行数自动计算 GMU,普通用户不需要填写。
5. 第一次请求为什么有 JIT warning?
第一次请求可能触发 Triton kernel JIT 编译,导致首轮速度偏低。后续请求通常会恢复正常。
6. 如何停止服务?
pkill -f "vllm.*Qwen3.6-27B-AWQ-INT4" || true
参考项目 / 致谢 / References
[1] vLLM Project. vLLM: high-throughput LLM serving engine.
https://github.com/vllm-project/vllm
[2] Qwen Team, Alibaba Group. FlashQLA: Flash Qwen Linear Attention.
https://github.com/QwenLM/FlashQLA
https://qwen.ai/blog?id=flashqla
[3] FlashInfer Team. FlashInfer: GPU kernels for LLM serving.
https://github.com/flashinfer-ai/flashinfer
[4] Qwen Team, Alibaba Group. Qwen / Qwen3 / Qwen3.6 model family.
https://github.com/QwenLM/Qwen
https://github.com/QwenLM/Qwen3
https://github.com/QwenLM/Qwen3.6
[5] PyTorch Contributors. PyTorch.
https://github.com/pytorch/pytorch
[6] Triton Contributors. Triton.
https://github.com/triton-lang/triton
[7] Flash Linear Attention Contributors. Flash Linear Attention.
https://github.com/fla-org/flash-linear-attention
[8] Hugging Face. Transformers.
https://github.com/huggingface/transformers
[9] vLLM Project. compressed-tensors.
https://github.com/vllm-project/compressed-tensors
[10] Dao-AILab. FlashAttention.
https://github.com/Dao-AILab/flash-attention
[11] NVIDIA. CUDA Toolkit.
https://developer.nvidia.com/cuda-toolkit
[12] weicj. vLLM-2080Ti-Definitive.
https://github.com/weicj/vLLM-2080Ti-Definitive
[13] weicj. 2080Ti-LLM-Toolbox.
https://github.com/weicj/2080Ti-LLM-Toolbox
[14] weicj. FlashQLA-SM70-SM75.
https://github.com/weicj/FlashQLA-SM70-SM75
[15] vLLM Project. FlashQLA integration discussion.
https://github.com/vllm-project/vllm/issues/43089
特别感谢@SPOTLITE 贡献:
https://github.com/weicj/vLLM-2080Ti-Definitive
https://github.com/weicj/2080Ti-LLM-Toolbox
https://github.com/weicj/FlashQLA-SM70-SM75
原创文章,作者:朋远方,如若转载,请注明出处:https://caovan.com/rtx-2080ti-vllm-sm75-turbo3-caovan-plugin-ubuntu-miniconda/.html
 微信扫一扫
微信扫一扫 







评论列表(25条)
我的CUDA版本升级到了13.3,加载报错,核心错误:
Error building extension ‘caovan_flash_qla_legacy_gdn_sm75_v018’:
error: need ‘typename’ before ‘decltype’ … [-Wtemplate-body]
ninja: build stopped: subcommand failed.
根因:插件自带的 gdn_forward.cu CUDA kernel 与 CUDA 13.3 的 nvcc 编译器不兼容(C++ 模板语法在新版 nvcc 更严格),编译失败后 .so 文件没生成,插件无法加载。
@橘子发条:你可以在虚拟环境中配置单独的CUDA,运行如下的命令试试:
conda activate 你的虚拟环境名称
conda install -y -c nvidia cuda-toolkit=13.0
mkdir -p “$CONDA_PREFIX/etc/conda/activate.d”
cat > “$CONDA_PREFIX/etc/conda/activate.d/caovan-cuda130.sh” <<'SH'
#!/usr/bin/env bash
export CUDA_HOME="$CONDA_PREFIX"
export CUDA_PATH="$CONDA_PREFIX"
export PATH="$CONDA_PREFIX/bin:$PATH"
export LD_LIBRARY_PATH="$CONDA_PREFIX/lib:${LD_LIBRARY_PATH:-}"
SH
chmod +x "$CONDA_PREFIX/etc/conda/activate.d/caovan-cuda130.sh"
conda deactivate
conda activate 你的虚拟环境名称
@朋远方:**在 conda 环境里装一套完整的 CUDA 13.0 toolkit**,让编译时用它而不是系统 13.3。
**预期效果**:
– ✅ 解决 GDN 编译问题(PyTorch cu130 兼容 CUDA 13.0)
– ❌ **解决不了 FA2 的 `illegal memory access`**——这是 SM75 kernel bug,与 CUDA 版本无关
**和你之前装 12.8 的区别**:
– 12.8:CUDA 版本与 PyTorch cu130 不匹配,可能导致运行时兼容问题
– 13.0:与 PyTorch cu130 完全匹配,理论上更稳定
**但核心问题不变**:Caovan 插件注入的 FA2 backend 在 SM75 上会 crash,不管 CUDA 是 12.8 还是 13.0。
这个FA2的问题怎么搞的?回退降级么
@橘子发条:SM75 不支持 FA2,这个错误不用管它,你看我录的视频里面的启动日志里面也有这个“ERROR”的——“Cannot use FA version 2 is not supported due to FA2 is only supported on devices with compute capability >= 8”,它不影响你使用插件!
@朋远方:我看到了也启动起来了,但是一对话调用就立刻崩溃。AI分析日志说是FA2的问题。对话调用出问题一般什么问题?纯vllm跑起来没啥问题速度45token/s左右。
@橘子发条:先确认没有强制指定 FA2 后端,并强制使用 FlashInfer:
export VLLM_ATTENTION_BACKEND=FLASHINFER
unset VLLM_USE_FLASH_ATTN
unset FLASH_ATTENTION_FORCE
然后清理旧缓存:
rm -rf ~/.cache/flashinfer
rm -rf ~/.cache/vllm/torch_compile_cache
rm -rf “${XDG_CACHE_HOME:-$HOME/.cache}/torchinductor”
再重新启动服务试试看。
@朋远方 我的是Ubuntu 22.04 LTS 跑起来就是45token/s 好像没有去到70-100 是不是缺了什么 还是说就是这样
@zhon1:你开启插件了吗?
@朋远方:照着你的双卡推荐命令来的 还是说需要另外如何开启呢
@zhon1:插件下载安装了是吧?
@朋远方:[Caovan] AutoSpec+DynamicTP+AutoMem+ElasticKV+CKV-PAC V-only Sidecar Alpha launcher v0.4.13; stack_soft=-1, stack_hard=-1; recursion=50000; caovan_mode=auto; compilation_config=injected PIECEWISE; speculative_config=auto MTP=4 (CAOVAN_AUTO_SPEC=4); automem=inject gpu_memory_utilization=0.868 reserve=2920MiB risk=mtp4-longctx-22g-safemtp4-hardfloor (Elastic-KV reserve=2920MiB,total=22527MiB,spec=4,ctx=262144,seqs=1,batch=8192,tp=2); safemtp4=backend-preserved:FLASHINFER; ckv_pac=vonly-sidecar-alpha; command=vllm serve 是的, 这个配置
@zhon1:你把你的完整启动参数和日志(直到启动完成之后推理阶段出现速度数据贴个四五条)贴出来看看?
@朋远方:我也是安装了插件后,看日志执行到一半执行不下去了
“21:30 第二次启动”一模一样卡死了:21:50:29 起 EngineCore 进入 shm_broadcast 60s 心跳,21:53:29 已是第 4 次心跳,主权重加载 184.86s + drafter 13.23s + torch.compile 18.91s 全跑完了,但encoder cache profile 阶段卡 IPC 通信(这条消息本身说”some processes are hanging or
doing some time-consuming work (e.g. compilation, weight/kv cache quantization)”——而我们看到的是 “Encoder cache will be initialized with a budget of 16384 tokens, and profiled with 1 image items of the maximum feature size” 之后就没下文)。
日志如下:
(Worker_TP1 pid=7355) ERROR 06-08 21:45:51 [fa_utils.py:171] Cannot use FA version 2 is not supported due to FA2 is only supported on devices with compute capability >= 8
(Worker_TP0 pid=7354) ERROR 06-08 21:45:51 [fa_utils.py:171] Cannot use FA version 2 is not supported due to FA2 is only supported on devices with compute capability >= 8
(Worker_TP0 pid=7354) INFO 06-08 21:45:52 [cuda.py:372] Using FLASHINFER attention backend out of potential backends: [‘FLASHINFER’, ‘TRITON_ATTN’].
(Worker_TP0 pid=7354) INFO 06-08 21:45:52 [weight_utils.py:938] Filesystem type for checkpoints: EXT4. Checkpoint size: 25.03 GiB. Available RAM: 8.90 GiB.
(Worker_TP0 pid=7354) INFO 06-08 21:45:52 [weight_utils.py:968] Auto-prefetch is disabled because the filesystem (EXT4) is not a recognized network FS (NFS/Lustre) and the checkpoint size (25.03 GiB) exceeds 90% of available RAM (8.90 GiB).
Loading safetensors checkpoint shards: 0% Completed | 0/14 [00:00<?, ?it/s]
Loading safetensors checkpoint shards: 7% Completed | 1/14 [00:15<03:15, 15.01s/it]
Loading safetensors checkpoint shards: 14% Completed | 2/14 [00:30<03:03, 15.32s/it]
Loading safetensors checkpoint shards: 21% Completed | 3/14 [00:46<02:51, 15.63s/it]
Loading safetensors checkpoint shards: 29% Completed | 4/14 [01:02<02:37, 15.73s/it]
Loading safetensors checkpoint shards: 36% Completed | 5/14 [01:18<02:23, 15.97s/it]
Loading safetensors checkpoint shards: 43% Completed | 6/14 [01:35<02:08, 16.07s/it]
Loading safetensors checkpoint shards: 50% Completed | 7/14 [01:50<01:51, 15.93s/it]
Loading safetensors checkpoint shards: 57% Completed | 8/14 [02:05<01:34, 15.68s/it]
Loading safetensors checkpoint shards: 64% Completed | 9/14 [02:21<01:17, 15.56s/it]
Loading safetensors checkpoint shards: 71% Completed | 10/14 [02:36<01:01, 15.48s/it]
Loading safetensors checkpoint shards: 79% Completed | 11/14 [02:50<00:45, 15.06s/it]
Loading safetensors checkpoint shards: 93% Completed | 13/14 [03:04<00:11, 11.32s/it]
Loading safetensors checkpoint shards: 100% Completed | 14/14 [03:04<00:00, 8.52s/it]
Loading safetensors checkpoint shards: 100% Completed | 14/14 [03:04<00:00, 13.20s/it]
(Worker_TP0 pid=7354)
(Worker_TP0 pid=7354) INFO 06-08 21:48:57 [default_loader.py:397] Loading weights took 184.86 seconds
(Worker_TP0 pid=7354) INFO 06-08 21:49:00 [gpu_model_runner.py:4881] Loading drafter model…
(Worker_TP0 pid=7354) INFO 06-08 21:49:00 [vllm.py:886] Asynchronous scheduling is enabled.
(Worker_TP0 pid=7354) INFO 06-08 21:49:00 [kernel.py:212] Final IR op priority after setting platform defaults: IrOpPriorityConfig(rms_norm=['native'], fused_add_rms_norm=['native'])
(Worker_TP1 pid=7355) INFO 06-08 21:49:00 [kernel.py:212] Final IR op priority after setting platform defaults: IrOpPriorityConfig(rms_norm=['native'], fused_add_rms_norm=['native'])
(Worker_TP0 pid=7354) INFO 06-08 21:49:00 [weight_utils.py:938] Filesystem type for checkpoints: EXT4. Checkpoint size: 25.03 GiB. Available RAM: 12.49 GiB.
(Worker_TP0 pid=7354) INFO 06-08 21:49:00 [weight_utils.py:968] Auto-prefetch is disabled because the filesystem (EXT4) is not a recognized network FS (NFS/Lustre) and the checkpoint size (25.03 GiB) exceeds 90% of available RAM (12.49 GiB).
Loading safetensors checkpoint shards: 0% Completed | 0/14 [00:00<?, ?it/s]
Loading safetensors checkpoint shards: 7% Completed | 1/14 [00:00<00:10, 1.24it/s]
Loading safetensors checkpoint shards: 14% Completed | 2/14 [00:01<00:09, 1.29it/s]
Loading safetensors checkpoint shards: 21% Completed | 3/14 [00:02<00:08, 1.22it/s]
Loading safetensors checkpoint shards: 29% Completed | 4/14 [00:03<00:08, 1.24it/s]
Loading safetensors checkpoint shards: 36% Completed | 5/14 [00:03<00:07, 1.27it/s]
Loading safetensors checkpoint shards: 43% Completed | 6/14 [00:04<00:05, 1.38it/s]
Loading safetensors checkpoint shards: 50% Completed | 7/14 [00:05<00:04, 1.46it/s]
Loading safetensors checkpoint shards: 79% Completed | 11/14 [00:06<00:01, 2.57it/s]
Loading safetensors checkpoint shards: 93% Completed | 13/14 [00:06<00:00, 2.76it/s]
Loading safetensors checkpoint shards: 100% Completed | 14/14 [00:13<00:00, 1.48s/it]
Loading safetensors checkpoint shards: 100% Completed | 14/14 [00:13= mamba page size.
(Worker_TP1 pid=7355) INFO 06-08 21:49:28 [interface.py:669] Padding mamba page size by 0.25% to ensure that mamba page size and attention page size are exactly equal.
(Worker_TP0 pid=7354) INFO 06-08 21:49:28 [gpu_model_runner.py:4959] Model loading took 12.65 GiB memory and 212.687311 seconds
(Worker_TP0 pid=7354) INFO 06-08 21:49:28 [interface.py:645] Setting attention block size to 1600 tokens to ensure that attention page size is >= mamba page size.
(Worker_TP0 pid=7354) INFO 06-08 21:49:28 [interface.py:669] Padding mamba page size by 0.25% to ensure that mamba page size and attention page size are exactly equal.
(Worker_TP0 pid=7354) INFO 06-08 21:49:28 [gpu_model_runner.py:5920] Encoder cache will be initialized with a budget of 16384 tokens, and profiled with 1 image items of the maximum feature size.
(Worker_TP0 pid=7354) INFO 06-08 21:49:51 [backends.py:1089] Using cache directory: /home/zhoudewei/.cache/vllm/torch_compile_cache/5e217c2ddd/rank_0_0/backbone for vLLM’s torch.compile
(Worker_TP0 pid=7354) INFO 06-08 21:49:51 [backends.py:1148] Dynamo bytecode transform time: 5.07 s
(Worker_TP0 pid=7354) INFO 06-08 21:50:05 [backends.py:292] Directly load the compiled graph(s) for compile range (1, 8192) from the cache, took 12.751 s
(Worker_TP1 pid=7355) INFO 06-08 21:50:05 [decorators.py:311] Directly load AOT compilation from path /home/zhoudewei/.cache/vllm/torch_compile_cache/torch_aot_compile/af288baa217de137f787fb751471450d0d93316ae06455930e22a4a535c18771/rank_1_0/model
(Worker_TP0 pid=7354) INFO 06-08 21:50:05 [decorators.py:311] Directly load AOT compilation from path /home/zhoudewei/.cache/vllm/torch_compile_cache/torch_aot_compile/af288baa217de137f787fb751471450d0d93316ae06455930e22a4a535c18771/rank_0_0/model
(Worker_TP0 pid=7354) INFO 06-08 21:50:05 [monitor.py:53] torch.compile took 18.91 s in total
(EngineCore pid=7332) INFO 06-08 21:50:29 [shm_broadcast.py:681] No available shared memory broadcast block found in 60 seconds. This typically happens when some processes are hanging or doing some time-consuming work (e.g. compilation, weight/kv cache quantization).
(EngineCore pid=7332) INFO 06-08 21:51:29 [shm_broadcast.py:681] No available shared memory broadcast block found in 60 seconds. This typically happens when some processes are hanging or doing some time-consuming work (e.g. compilation, weight/kv cache quantization).
(EngineCore pid=7332) INFO 06-08 21:52:29 [shm_broadcast.py:681] No available shared memory broadcast block found in 60 seconds. This typically happens when some processes are hanging or doing some time-consuming work (e.g. compilation, weight/kv cache quantization).
(EngineCore pid=7332) INFO 06-08 21:53:29 [shm_broadcast.py:681] No available shared memory broadcast block found in 60 seconds. This typically happens when some processes are hanging or doing some time-consuming work (e.g. compilation, weight/kv cache quantization).
/home/zhoudewei/ai/scripts/start-qwen36-27b-awq-caovan.sh: 第 70 行: 7196 已杀死 caovan-vllm-serve “$MODEL_DIR” –host “$HOST” –port “$PORT” –served-model-name “$SERVED_NAME” –tensor-parallel-size “$TP” –dtype half –max-model-len “$MAX_MODEL_LEN” –max-num-seqs “$MAX_NUM_SEQS” –max-num-batched-tokens “$MAX_NUM_BATCHED_TOKENS” –kv-cache-dtype fp8 –disable-custom-all-reduce –enable-prefix-caching –mamba-cache-mode align –enable-flashinfer-autotune –additional-config “{\”caovan\”:true,\”caovan_mode\”:\”$CAOVAN_MODE\”}” –reasoning-parser qwen3 –enable-auto-tool-choice –tool-call-parser qwen3_coder
@朋远方:我的启动命令是
/home/zhoudewei/miniconda3/envs/caovan-vllm/bin/python
/home/zhoudewei/miniconda3/envs/caovan-vllm/bin/caovan-vllm-serve
/home/zhoudewei/ai/models/qwen3.6/Qwopus3.6-27B-v2-AWQ-4bit
–host 0.0.0.0
–port 8003 ← 我用 PORT=8003 覆盖了脚本默认 8000
–served-model-name Qwen3.6-27B-AWQ-INT4
–tensor-parallel-size 2
–dtype half
–max-model-len 262144
–max-num-seqs 1
–max-num-batched-tokens 8192
–kv-cache-dtype fp8
–disable-custom-all-reduce
–enable-prefix-caching
–mamba-cache-mode align
–enable-flashinfer-autotune
–additional-config {“caovan”:true,”caovan_mode”:”auto”}
–reasoning-parser qwen3
–enable-auto-tool-choice
–tool-call-parser qwen3_coder
和”教程原版”两点差异
┌──────────┬─────────────────────────────────┬─────────────────────────────────────────────────────────────┬─────────────────────────────────────────────────┐
│ 项 │ 教程原版 │ 我实际跑 │ 原因 │
├──────────┼─────────────────────────────────┼─────────────────────────────────────────────────────────────┼─────────────────────────────────────────────────┤
│ 模型路径 │ /data/qwen/Qwen3.6-27B-AWQ-INT4 │ /home/zhoudewei/ai/models/qwen3.6/Qwopus3.6-27B-v2-AWQ-4bit │ 远端真实存在的 mconcat AWQ-4bit 模型目录 │
├──────────┼─────────────────────────────────┼─────────────────────────────────────────────────────────────┼─────────────────────────────────────────────────┤
│ 端口 │ 8000 │ 8003 │ memory 里 llama.cpp 27B 路线历史占过 8000,避开 │
@9123:你用的是哪个模型?你这个模型有25.03GB,我文章里列出来的我测试过的3个模型都没有超过20G,显存不够
@9123:你这个模型太大了,我查了下huggingface上模型有26.9GB,两张2080TI 44G的显存显存不够,你可以试试用4张卡来跑
@朋远方:我更换了Qwen3.6-27B-AWQ-INT4的模型,模型大小不到20G了。但是启动上还有一点点小问题。
(Worker_TP0 pid=9497) INFO 06-08 22:12:34 [mm_encoder_attention.py:372] Using AttentionBackendEnum.TORCH_SDPA for MMEncoderAttention.
(Worker_TP1 pid=9498) INFO 06-08 22:12:34 [compressed_tensors_wNa16.py:112] Using MarlinLinearKernel for CompressedTensorsWNA16
(Worker_TP0 pid=9497) INFO 06-08 22:12:34 [compressed_tensors_wNa16.py:112] Using MarlinLinearKernel for CompressedTensorsWNA16
(Worker_TP0 pid=9497) INFO 06-08 22:12:34 [gdn_linear_attn.py:169] Using Triton/FLA GDN prefill kernel
(Worker_TP1 pid=9498) ERROR 06-08 22:12:34 [fa_utils.py:171] Cannot use FA version 2 is not supported due to FA2 is only supported on devices with compute capability >= 8
(Worker_TP0 pid=9497) ERROR 06-08 22:12:34 [fa_utils.py:171] Cannot use FA version 2 is not supported due to FA2 is only supported on devices with compute capability >= 8
(Worker_TP0 pid=9497) INFO 06-08 22:12:34 [cuda.py:372] Using FLASHINFER attention backend out of potential backends: [‘FLASHINFER’, ‘TRITON_ATTN’].
(Worker_TP0 pid=9497) INFO 06-08 22:12:35 [weight_utils.py:938] Filesystem type for checkpoints: EXT4. Checkpoint size: 19.04 GiB. Available RAM: 9.13 GiB.
(Worker_TP0 pid=9497) INFO 06-08 22:12:35 [weight_utils.py:968] Auto-prefetch is disabled because the filesystem (EXT4) is not a recognized network FS (NFS/Lustre) and the checkpoint size (19.04 GiB) exceeds 90% of available RAM (9.13 GiB).
Loading safetensors checkpoint shards: 0% Completed | 0/4 [00:00<?, ?it/s]
Loading safetensors checkpoint shards: 25% Completed | 1/4 [00:51<02:35, 51.78s/it]
Loading safetensors checkpoint shards: 50% Completed | 2/4 [01:44<01:44, 52.48s/it]
Loading safetensors checkpoint shards: 75% Completed | 3/4 [02:30<00:49, 49.37s/it]
Loading safetensors checkpoint shards: 100% Completed | 4/4 [03:20<00:00, 49.61s/it]
Loading safetensors checkpoint shards: 100% Completed | 4/4 [03:20<00:00, 50.11s/it]
(Worker_TP0 pid=9497)
(Worker_TP0 pid=9497) INFO 06-08 22:15:55 [default_loader.py:397] Loading weights took 200.59 seconds
(Worker_TP0 pid=9497) INFO 06-08 22:16:02 [gpu_model_runner.py:4881] Loading drafter model…
(Worker_TP0 pid=9497) INFO 06-08 22:16:02 [vllm.py:886] Asynchronous scheduling is enabled.
(Worker_TP0 pid=9497) INFO 06-08 22:16:02 [kernel.py:212] Final IR op priority after setting platform defaults: IrOpPriorityConfig(rms_norm=['native'], fused_add_rms_norm=['native'])
(Worker_TP1 pid=9498) INFO 06-08 22:16:02 [kernel.py:212] Final IR op priority after setting platform defaults: IrOpPriorityConfig(rms_norm=['native'], fused_add_rms_norm=['native'])
(Worker_TP0 pid=9497) INFO 06-08 22:16:02 [weight_utils.py:938] Filesystem type for checkpoints: EXT4. Checkpoint size: 19.04 GiB. Available RAM: 11.54 GiB.
(Worker_TP0 pid=9497) INFO 06-08 22:16:02 [weight_utils.py:968] Auto-prefetch is disabled because the filesystem (EXT4) is not a recognized network FS (NFS/Lustre) and the checkpoint size (19.04 GiB) exceeds 90% of available RAM (11.54 GiB).
Loading safetensors checkpoint shards: 0% Completed | 0/4 [00:00<?, ?it/s]
Loading safetensors checkpoint shards: 25% Completed | 1/4 [00:02<00:08, 2.90s/it]
Loading safetensors checkpoint shards: 50% Completed | 2/4 [00:04<00:04, 2.01s/it]
Loading safetensors checkpoint shards: 75% Completed | 3/4 [00:04<00:01, 1.19s/it]
Loading safetensors checkpoint shards: 100% Completed | 4/4 [00:07<00:00, 2.08s/it]
Loading safetensors checkpoint shards: 100% Completed | 4/4 [00:07= mamba page size.
(Worker_TP1 pid=9498) INFO 06-08 22:16:24 [interface.py:645] Setting attention block size to 1600 tokens to ensure that attention page size is >= mamba page size.
(Worker_TP0 pid=9497) INFO 06-08 22:16:24 [interface.py:669] Padding mamba page size by 0.25% to ensure that mamba page size and attention page size are exactly equal.
(Worker_TP1 pid=9498) INFO 06-08 22:16:24 [interface.py:669] Padding mamba page size by 0.25% to ensure that mamba page size and attention page size are exactly equal.
(Worker_TP0 pid=9497) INFO 06-08 22:16:25 [gpu_model_runner.py:5920] Encoder cache will be initialized with a budget of 16384 tokens, and profiled with 1 image items of the maximum feature size.
(Worker_TP0 pid=9497) INFO 06-08 22:16:59 [backends.py:1089] Using cache directory: /home/zhoudewei/.cache/vllm/torch_compile_cache/b640711b1e/rank_0_0/backbone for vLLM’s torch.compile
(Worker_TP0 pid=9497) INFO 06-08 22:16:59 [backends.py:1148] Dynamo bytecode transform time: 16.95 s
(Worker_TP0 pid=9497) INFO 06-08 22:17:04 [backends.py:378] Cache the graph of compile range (1, 8192) for later use
(EngineCore pid=9475) INFO 06-08 22:17:26 [shm_broadcast.py:681] No available shared memory broadcast block found in 60 seconds. This typically happens when some processes are hanging or doing some time-consuming work (e.g. compilation, weight/kv cache quantization).
(Worker_TP0 pid=9497) INFO 06-08 22:17:38 [backends.py:393] Compiling a graph for compile range (1, 8192) takes 37.53 s
(Worker_TP0 pid=9497) INFO 06-08 22:17:49 [decorators.py:708] saved AOT compiled function to /home/zhoudewei/.cache/vllm/torch_compile_cache/torch_aot_compile/cc4544b2ac0dfcfd4aa123fa134c40c9289a2d03694aa2e364a488574e34854a/rank_0_0/model
(Worker_TP0 pid=9497) INFO 06-08 22:17:49 [monitor.py:53] torch.compile took 66.61 s in total
(EngineCore pid=9475) INFO 06-08 22:18:26 [shm_broadcast.py:681] No available shared memory broadcast block found in 60 seconds. This typically happens when some processes are hanging or doing some time-consuming work (e.g. compilation, weight/kv cache quantization).
(EngineCore pid=9475) INFO 06-08 22:19:26 [shm_broadcast.py:681] No available shared memory broadcast block found in 60 seconds. This typically happens when some processes are hanging or doing some time-consuming work (e.g. compilation, weight/kv cache quantization).
(EngineCore pid=9475) INFO 06-08 22:20:26 [shm_broadcast.py:681] No available shared memory broadcast block found in 60 seconds. This typically happens when some processes are hanging or doing some time-consuming work (e.g. compilation, weight/kv cache quantization).
(EngineCore pid=9475) INFO 06-08 22:21:26 [shm_broadcast.py:681] No available shared memory broadcast block found in 60 seconds. This typically happens when some processes are hanging or doing some time-consuming work (e.g. compilation, weight/kv cache quantization).
(EngineCore pid=9475) INFO 06-08 22:22:26 [shm_broadcast.py:681] No available shared memory broadcast block found in 60 seconds. This typically happens when some processes are hanging or doing some time-consuming work (e.g. compilation, weight/kv cache quantization).
(EngineCore pid=9475) INFO 06-08 22:23:26 [shm_broadcast.py:681] No available shared memory broadcast block found in 60 seconds. This typically happens when some processes are hanging or doing some time-consuming work (e.g. compilation, weight/kv cache quantization).
(EngineCore pid=9475) INFO 06-08 22:24:26 [shm_broadcast.py:681] No available shared memory broadcast block found in 60 seconds. This typically happens when some processes are hanging or doing some time-consuming work (e.g. compilation, weight/kv cache quantization).
(EngineCore pid=9475) INFO 06-08 22:25:26 [shm_broadcast.py:681] No available shared memory broadcast block found in 60 seconds. This typically happens when some processes are hanging or doing some time-consuming work (e.g. compilation, weight/kv cache quantization).
(EngineCore pid=9475) INFO 06-08 22:26:26 [shm_broadcast.py:681] No available shared memory broadcast block found in 60 seconds. This typically happens when some processes are hanging or doing some time-consuming work (e.g. compilation, weight/kv cache quantization).
(EngineCore pid=9475) INFO 06-08 22:27:26 [shm_broadcast.py:681] No available shared memory broadcast block found in 60 seconds. This typically happens when some processes are hanging or doing some time-consuming work (e.g. compilation, weight/kv cache quantization).
(EngineCore pid=9475) INFO 06-08 22:28:26 [shm_broadcast.py:681] No available shared memory broadcast block found in 60 seconds. This typically happens when some processes are hanging or doing some time-consuming work (e.g. compilation, weight/kv cache quantization).
(EngineCore pid=9475) INFO 06-08 22:29:26 [shm_broadcast.py:681] No available shared memory broadcast block found in 60 seconds. This typically happens when some processes are hanging or doing some time-consuming work (e.g. compilation, weight/kv cache quantization).
(EngineCore pid=9475) INFO 06-08 22:30:26 [shm_broadcast.py:681] No available shared memory broadcast block found in 60 seconds. This typically happens when some processes are hanging or doing some time-consuming work (e.g. compilation, weight/kv cache quantization).
(EngineCore pid=9475) INFO 06-08 22:31:26 [shm_broadcast.py:681] No available shared memory broadcast block found in 60 seconds. This typically happens when some processes are hanging or doing some time-consuming work (e.g. compilation, weight/kv cache quantization).
@9123:你的机器内存是多大的?初步看起来是内存不够,你可以把下面的信息发我下
free -h、swapon –show、df -h /dev/shm、dmesg
@朋远方:更换了小于20G的模型后,卡的时候,nvidia-smi显示
Mon Jun 8 22:32:17 2026
+—————————————————————————————–+
| NVIDIA-SMI 595.71.05 Driver Version: 595.71.05 CUDA Version: 13.2 |
+—————————————–+————————+———————-+
| GPU Name Persistence-M | Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap | Memory-Usage | GPU-Util Compute M. |
| | | MIG M. |
|=========================================+========================+======================|
| 0 NVIDIA GeForce RTX 2080 Ti Off | 00000000:01:00.0 Off | N/A |
| 30% 38C P8 31W / 250W | 12396MiB / 22528MiB | 0% Default |
| | | N/A |
+—————————————–+————————+———————-+
| 1 NVIDIA GeForce RTX 2080 Ti Off | 00000000:05:00.0 Off | N/A |
| 30% 38C P8 18W / 250W | 12396MiB / 22528MiB | 0% Default |
| | | N/A |
+—————————————–+————————+———————-+
+—————————————————————————————–+
| Processes: |
| GPU GI CI PID Type Process name GPU Memory |
| ID ID Usage |
|=========================================================================================|
| 0 N/A N/A 9497 C VLLM::Worker_TP0 12392MiB |
| 1 N/A N/A 9498 C VLLM::Worker_TP1 12392MiB |
+—————————————————————————————–+
@9123:你加我微信 arthur77058 截图我看下
@朋远方:caovan-vllm-serve /home/indoors/models/heretic27-gptq-mm-tq4nc-mtp3 –host 0.0.0.0 –port 8000 –served-model-name Qwen3.6-27B –tensor-parallel-size 2 –dtype half –max-model-len 262144 –max-num-seqs 2 –max-num-batched-tokens 8192 –kv-cache-dtype fp8 –disable-custom-all-reduce –enable-prefix-caching –mamba-cache-mode align –enable-flashinfer-autotune –additional-config ‘{“caovan”:true,”caovan_mode”:”auto”}’ –reasoning-parser qwen3 –enable-auto-tool-choice –tool-call-parser qwen3_coder
================================================================
[Caovan] AutoSpec+DynamicTP+AutoMem+ElasticKV+CKV-PAC V-only Sidecar Alpha launcher v0.4.13; stack_soft=-1, stack_hard=-1; recursion=50000; caovan_mode=auto; compilation_config=injected PIECEWISE; speculative_config=auto MTP=4 (CAOVAN_AUTO_SPEC=4); automem=inject gpu_memory_utilization=0.868 reserve=2920MiB risk=mtp4-longctx-22g-safemtp4-hardfloor (Elastic-KV reserve=2920MiB,total=22527MiB,spec=4,ctx=262144,seqs=2,batch=8192,tp=2); safemtp4=backend-preserved:FLASHINFER; ckv_pac=vonly-sidecar-alpha; command=vllm serve
WARNING 06-08 22:22:31 [interface.py:725] Using ‘pin_memory=False’ as WSL is detected. This may slow down the performance.
ERROR 06-08 22:22:33 [fa_utils.py:171] Cannot use FA version 2 is not supported due to FA2 is only supported on devices with compute capability >= 8
(APIServer pid=5769) INFO 06-08 21:49:21 [loggers.py:271] Engine 000: Avg prompt throughput: 0.0 tokens/s, Avg generation throughput: 61.1 tokens/s, Running: 1 reqs, Waiting: 0 reqs, GPU KV cache usage: 13.6%, Prefix cache hit rate: 0.0%
(APIServer pid=5769) INFO 06-08 21:49:21 [metrics.py:101] SpecDecoding metrics: Mean acceptance length: 3.92, Accepted throughput: 45.48 tokens/s, Drafted throughput: 62.38 tokens/s, Accepted: 455 tokens, Drafted: 624 tokens, Per-position acceptance rate: 0.865, 0.795, 0.673, 0.583, Avg Draft acceptance rate: 72.9%
(APIServer pid=5769) INFO 06-08 21:49:31 [loggers.py:271] Engine 000: Avg prompt throughput: 0.0 tokens/s, Avg generation throughput: 62.4 tokens/s, Running: 1 reqs, Waiting: 0 reqs, GPU KV cache usage: 13.6%, Prefix cache hit rate: 0.0%
(APIServer pid=5769) INFO 06-08 21:49:31 [metrics.py:101] SpecDecoding metrics: Mean acceptance length: 4.03, Accepted throughput: 46.88 tokens/s, Drafted throughput: 61.98 tokens/s, Accepted: 469 tokens, Drafted: 620 tokens, Per-position acceptance rate: 0.890, 0.800, 0.723, 0.613, Avg Draft acceptance rate: 75.6%
(APIServer pid=5769) INFO 06-08 21:49:41 [loggers.py:271] Engine 000: Avg prompt throughput: 0.0 tokens/s, Avg generation throughput: 59.6 tokens/s, Running: 1 reqs, Waiting: 0 reqs, GPU KV cache usage: 13.9%, Prefix cache hit rate: 0.0%
(APIServer pid=5769) INFO 06-08 21:49:41 [metrics.py:101] SpecDecoding metrics: Mean acceptance length: 3.87, Accepted throughput: 44.18 tokens/s, Drafted throughput: 61.58 tokens/s, Accepted: 442 tokens, Drafted: 616 tokens, Per-position acceptance rate: 0.883, 0.773, 0.649, 0.565, Avg Draft acceptance rate: 71.8%
(APIServer pid=5769) INFO 06-08 21:49:51 [loggers.py:271] Engine 000: Avg prompt throughput: 0.0 tokens/s, Avg generation throughput: 64.2 tokens/s, Running: 1 reqs, Waiting: 0 reqs, GPU KV cache usage: 13.9%, Prefix cache hit rate: 0.0%
(APIServer pid=5769) INFO 06-08 21:49:51 [metrics.py:101] SpecDecoding metrics: Mean acceptance length: 4.20, Accepted throughput: 48.89 tokens/s, Drafted throughput: 61.18 tokens/s, Accepted: 489 tokens, Drafted: 612 tokens, Per-position acceptance rate: 0.895, 0.810, 0.778, 0.712, Avg Draft acceptance rate: 79.9%
(APIServer pid=5769) INFO 06-08 21:50:01 [loggers.py:271] Engine 000: Avg prompt throughput: 0.0 tokens/s, Avg generation throughput: 55.5 tokens/s, Running: 0 reqs, Waiting: 0 reqs, GPU KV cache usage: 0.0%, Prefix cache hit rate: 0.0%
(APIServer pid=5769) INFO 06-08 21:50:01 [metrics.py:101] SpecDecoding metrics: Mean acceptance length: 4.05, Accepted throughput: 41.80 tokens/s, Drafted throughput: 54.80 tokens/s, Accepted: 418 tokens, Drafted: 548 tokens, Per-position acceptance rate: 0.898, 0.810, 0.723, 0.620, Avg Draft acceptance rate: 76.3%
(APIServer pid=5769) INFO 06-08 21:50:12 [loggers.py:271] Engine 000: Avg prompt throughput: 0.0 tokens/s, Avg generation throughput: 0.0 tokens/s, Running: 0 reqs, Waiting: 0 reqs, GPU KV cache usage: 0.0%
@zhon1:1、在wsl下跑肯定比原生Ubuntu环境下跑性能会打折扣;
2、目前插件只对AWQ量化格式的模型做了性能优化,对GPTQ的模型并没有做专门优化,你可以测试下跑我文章中测试过的3个模型试试,插件的下个版本可能会专门针对GPTQ和其他量化格式的模型来进行优化一次;
4張 2080Ti 22GB:
能用 fast mode 嗎?
MTP可以同時高併發 –max-num-seqs 4 嗎? (或3)
@fewa:我测试4卡的时候跑fast 没有问题,四卡并发可以到5-6左右
博主确实nb,折腾hermes最重要的输入token可以达到2k5,这速度确实可以了