


Llama3是目前开源大模型中最优秀的模型之一,但是原生的Llama3模型训练的中文语料占比非常低,因此在中文的表现方便略微欠佳!
本教程就以Llama3-8B-Instruct开源模型为模型基座,通过开源程序LLaMA-Factory来进行中文的微调,提高Llama3的中文能力!
Llama3-8B-Instruct模型下载地址:
魔搭社区(境内):https://modelscope.cn/models/LLM-Research/Meta-Llama-3-8B-Instruct/files
huggingface(境外):https://huggingface.co/meta-llama/Meta-Llama-3-8B-Instruct/tree/main
LLaMA-Factory项目地址:https://github.com/hiyouga/LLaMA-Factory
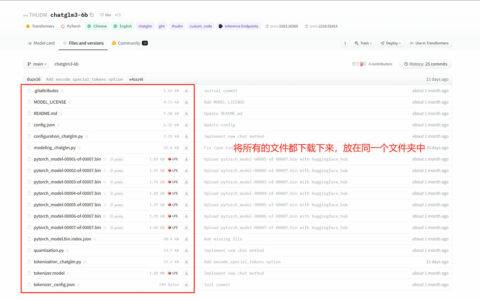
下载模型
中国大陆境内可以通过魔搭社区下载模型,境外可以在huggingface上去下载模型!
从魔搭社区下载
点击“下载模型”
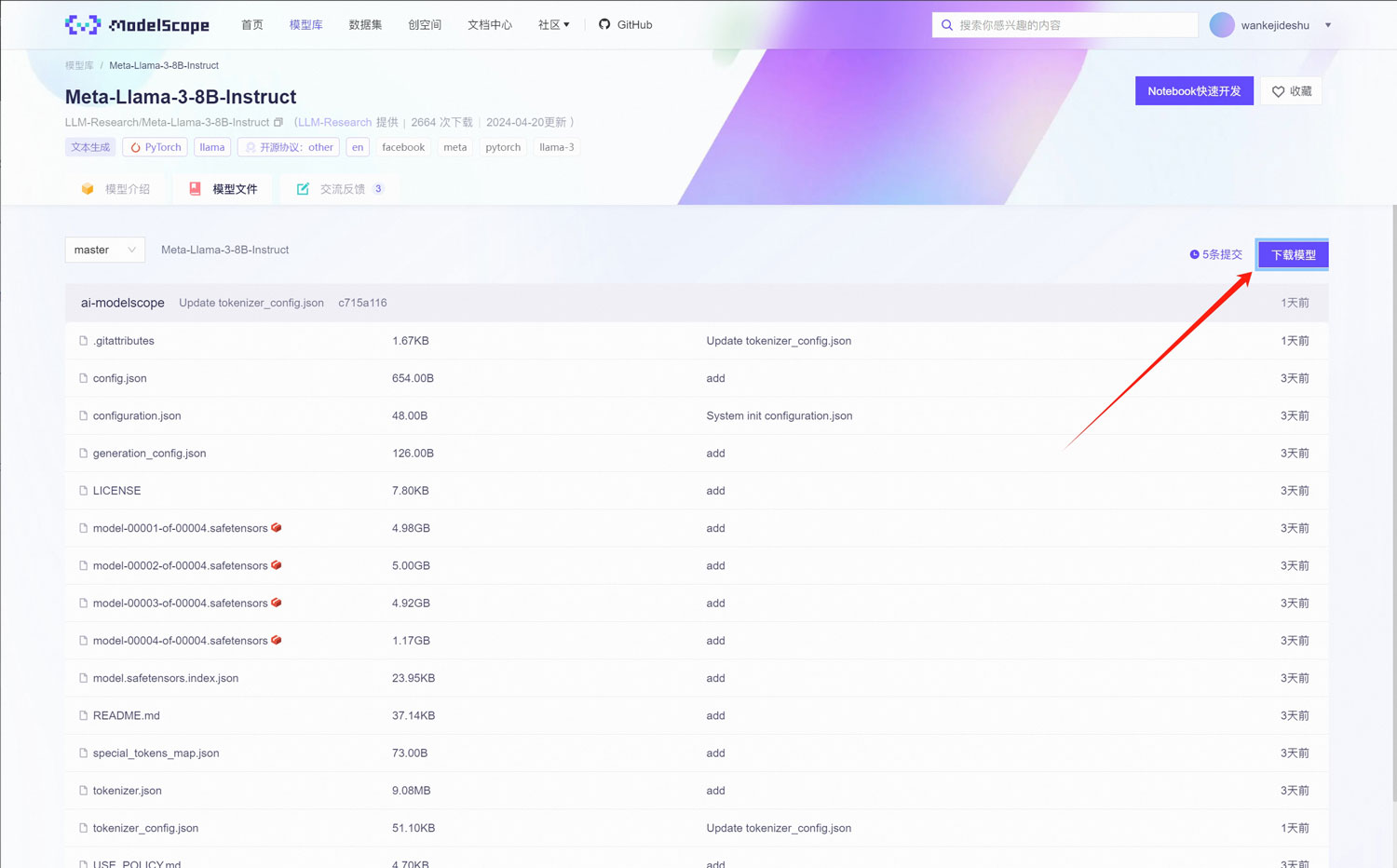
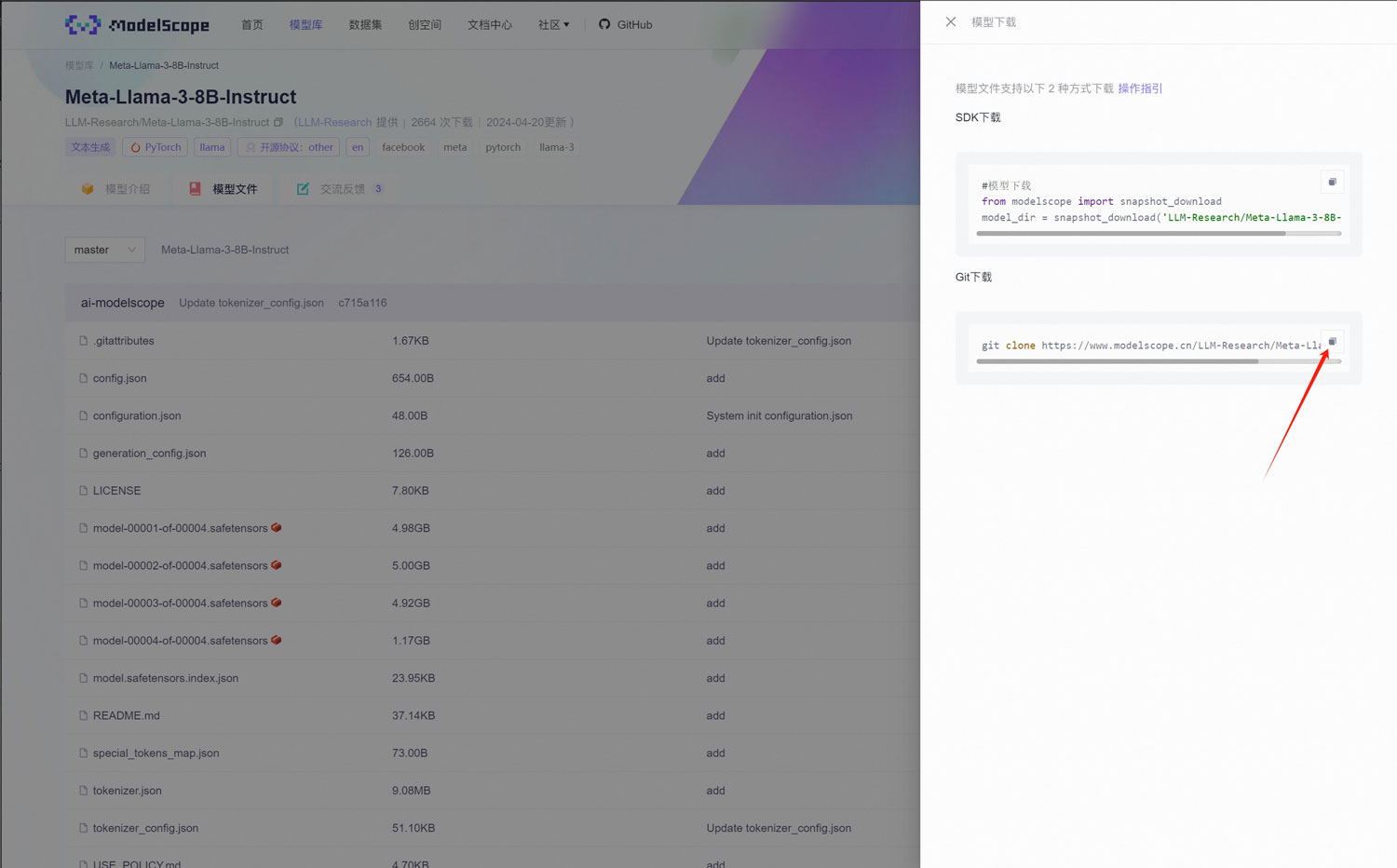
复制git链接
git clone https://www.modelscope.cn/LLM-Research/Meta-Llama-3-8B-Instruct.git
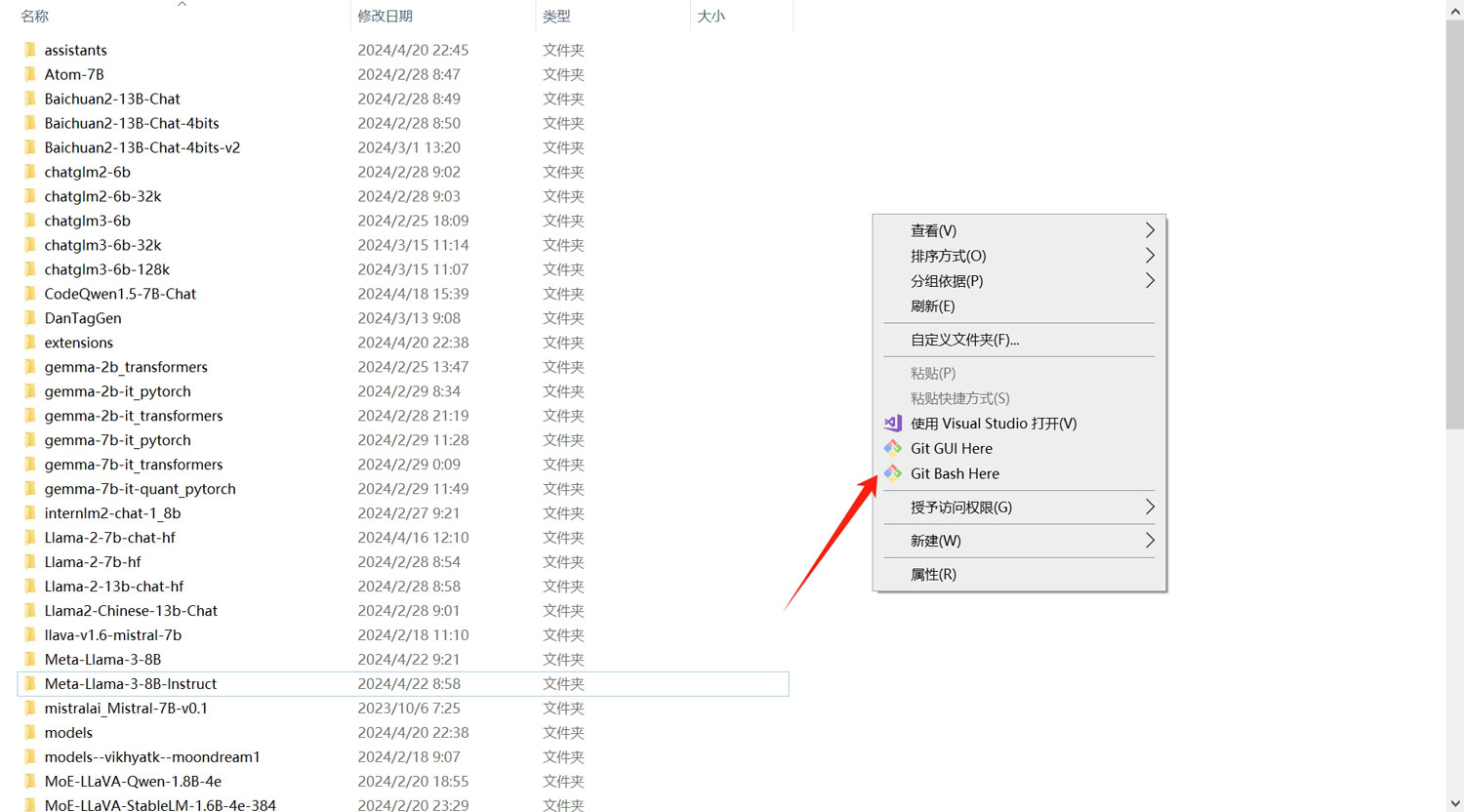
在模型存放的文件空白处点击鼠标右键,选择“Git Bash Here”,会打开一个git命令窗口
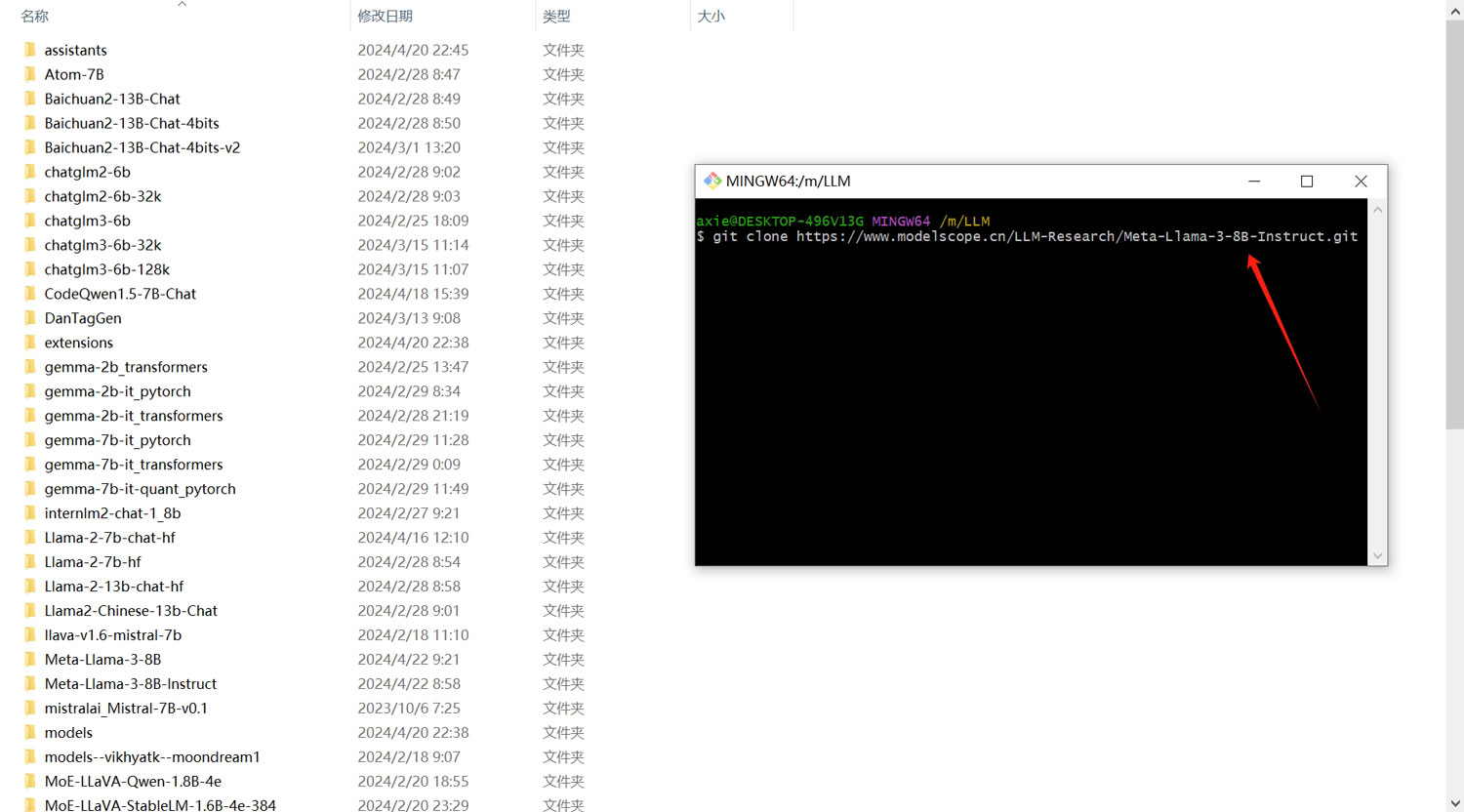
将刚刚复制的模型地址粘贴到git命令窗口,回车,即可进入到下载过程!
模型比较大,需要耐心等待模型下载完成!
从Huggingface下载
如果是中国大陆境外的朋友,可以从huggingface进行下载!方法与魔搭社区下载方法类似!
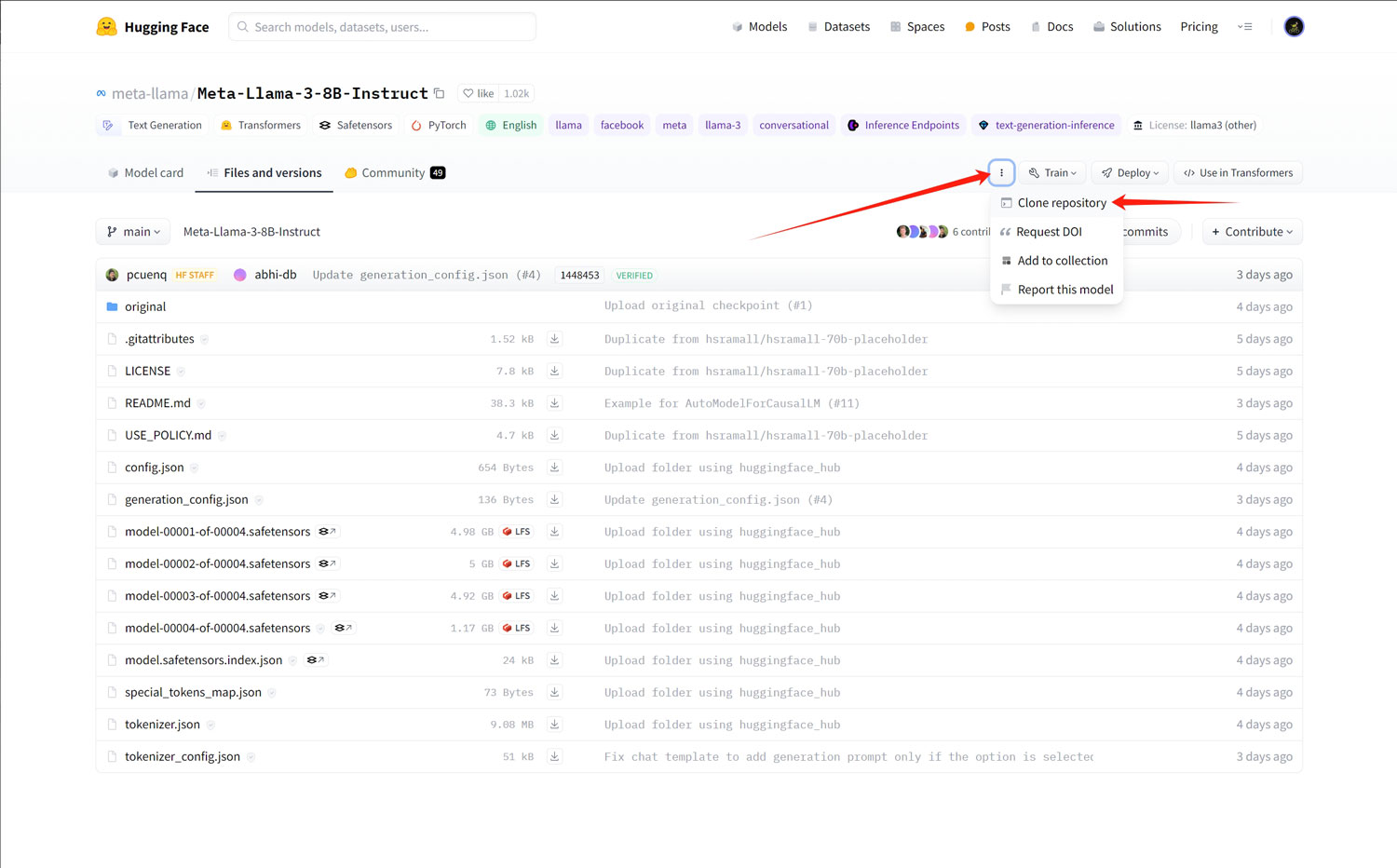
如果是第一次从huggingface通过命令下载模型,可以先运行下面的命令安装 git-lfs
git lfs install
然后再复制模型的git链接
git clone https://huggingface.co/meta-llama/Meta-Llama-3-8B-Instruct
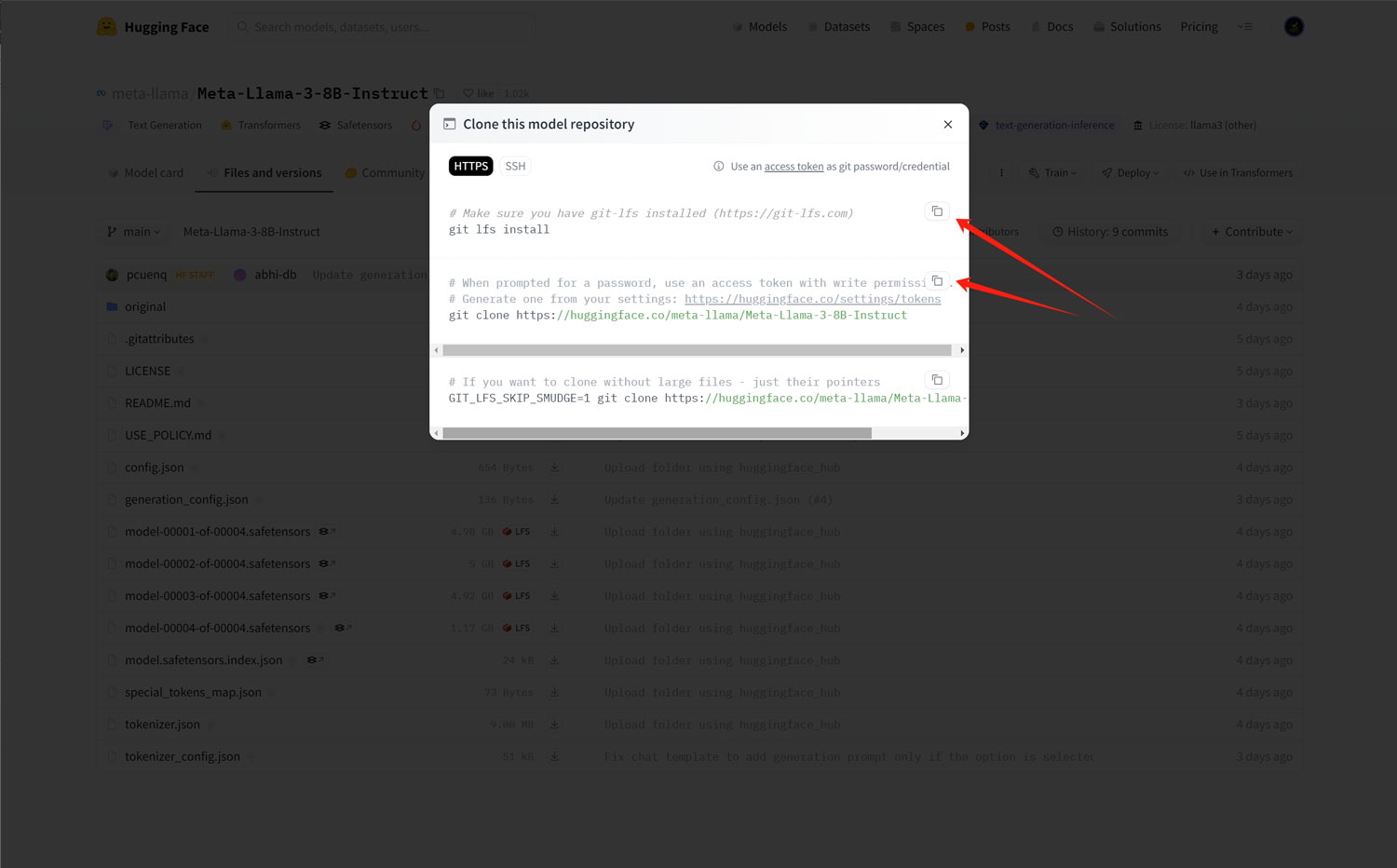
在文件夹中的下载步骤与魔搭社区的步骤一样,都是通过git命令窗口来进行下载!
安装LLaMA-Factory
克隆项目到本地
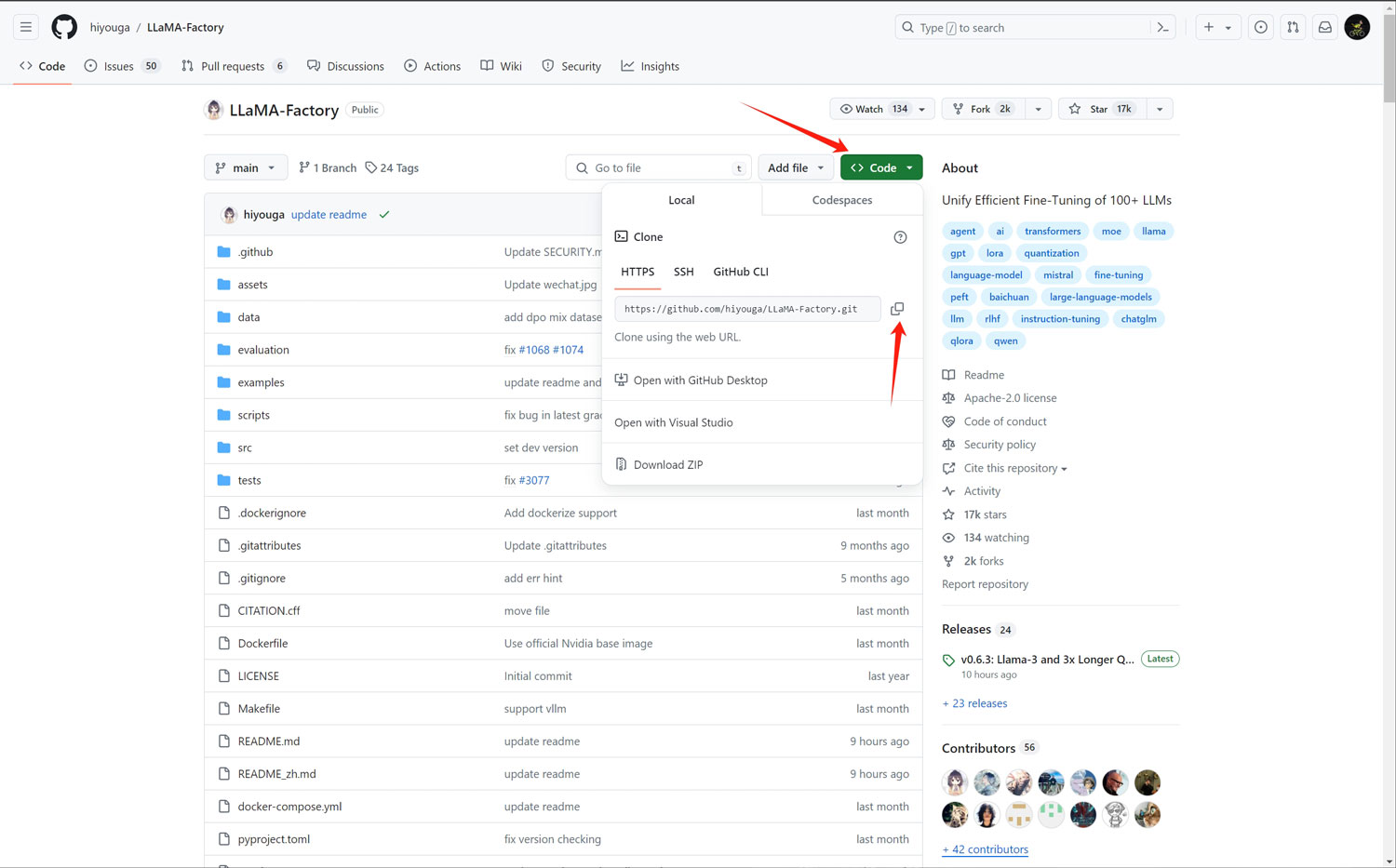
首先访问LLaMA-Factory项目的GitHub主页,点击绿色的“Code”下拉按钮,点击“复制”按钮复制项目链接!
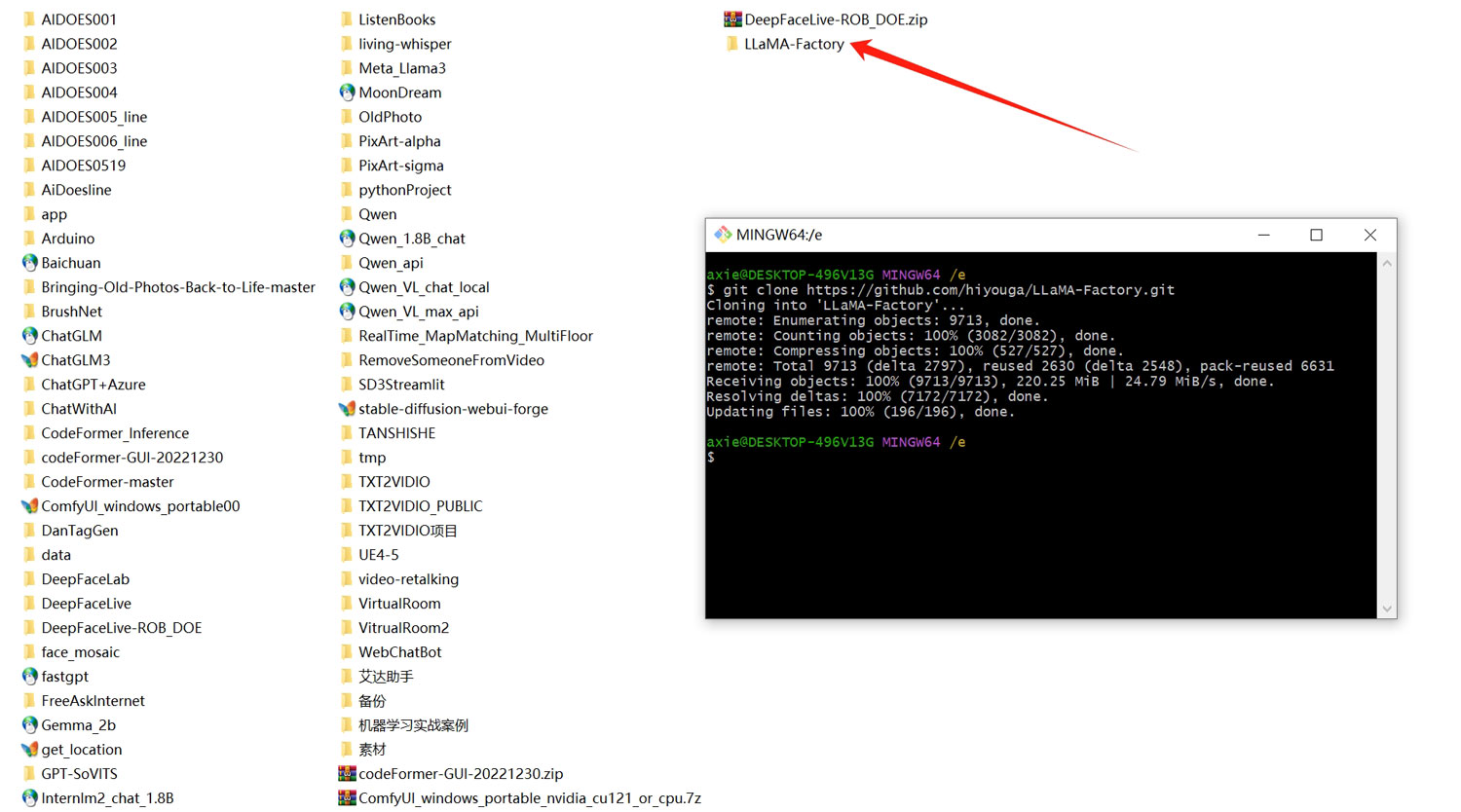
git clone https://github.com/hiyouga/LLaMA-Factory.git
在文件夹空白处点击鼠标右键,选择“Git Bash Here”,打开一个git窗口
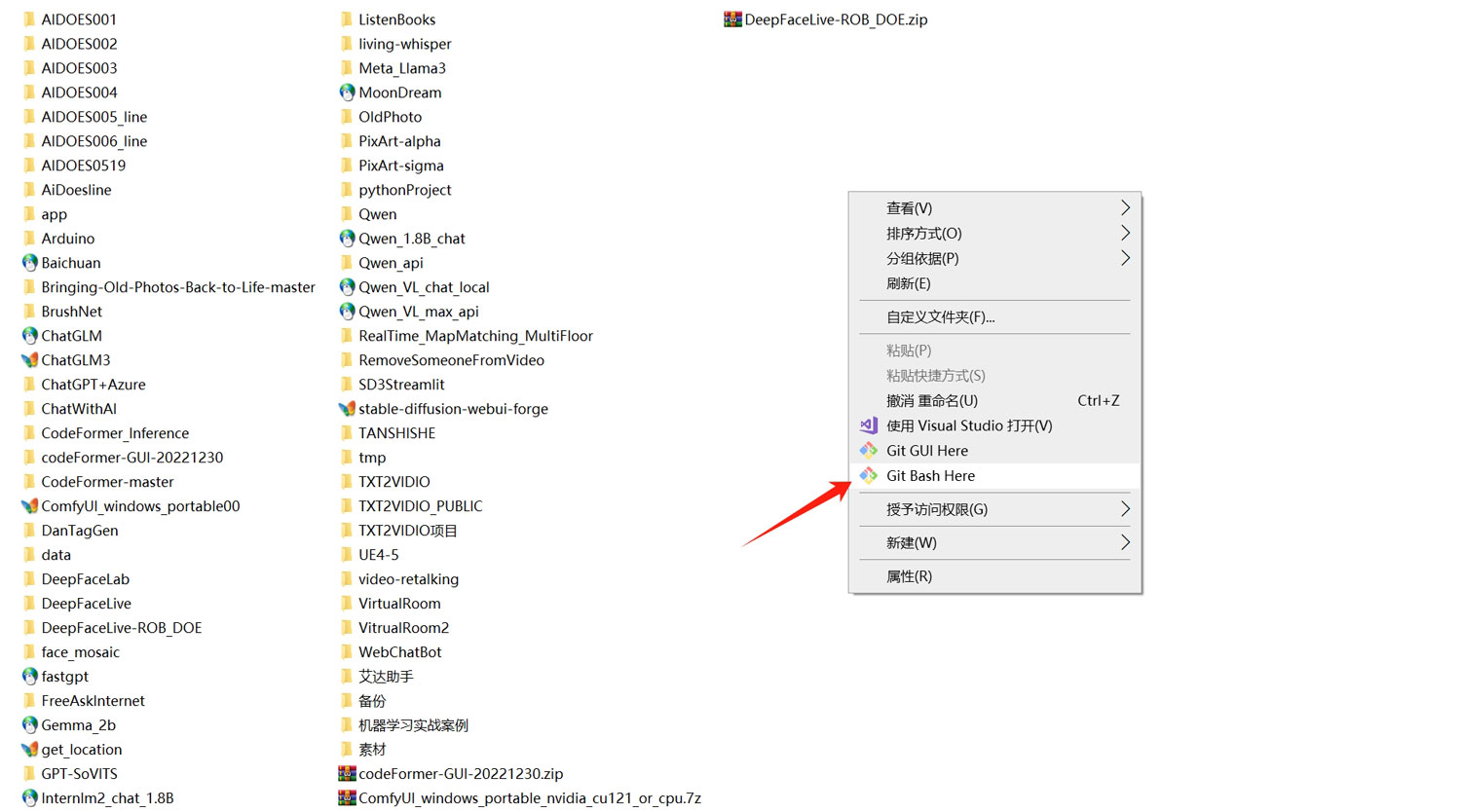
输入刚刚复制的git链接,回车,将项目克隆到本地文件夹
新建虚拟环境
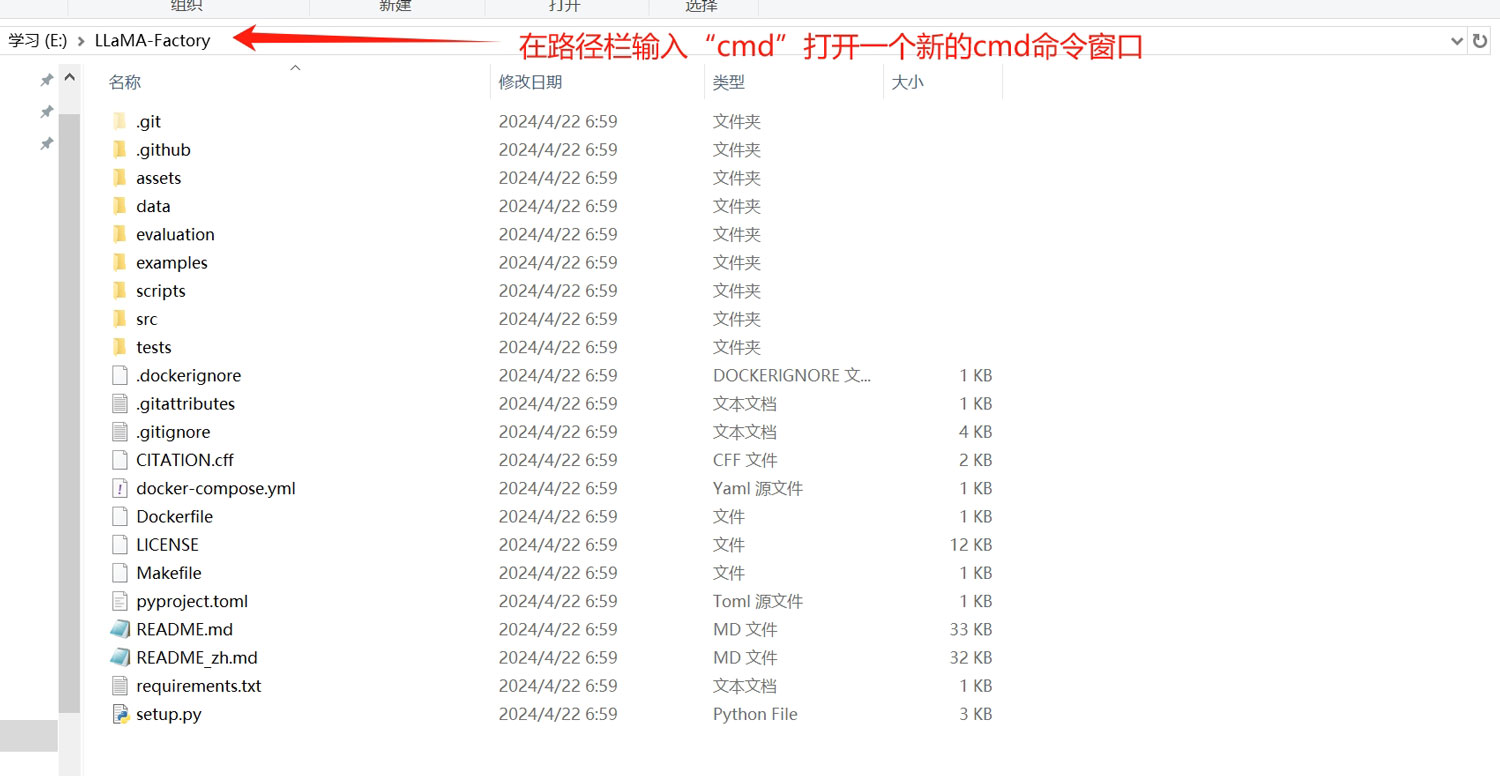
进入到刚刚下载的项目文件夹中,在路径栏输入“cmd”,打开一个新的cmd命令窗口
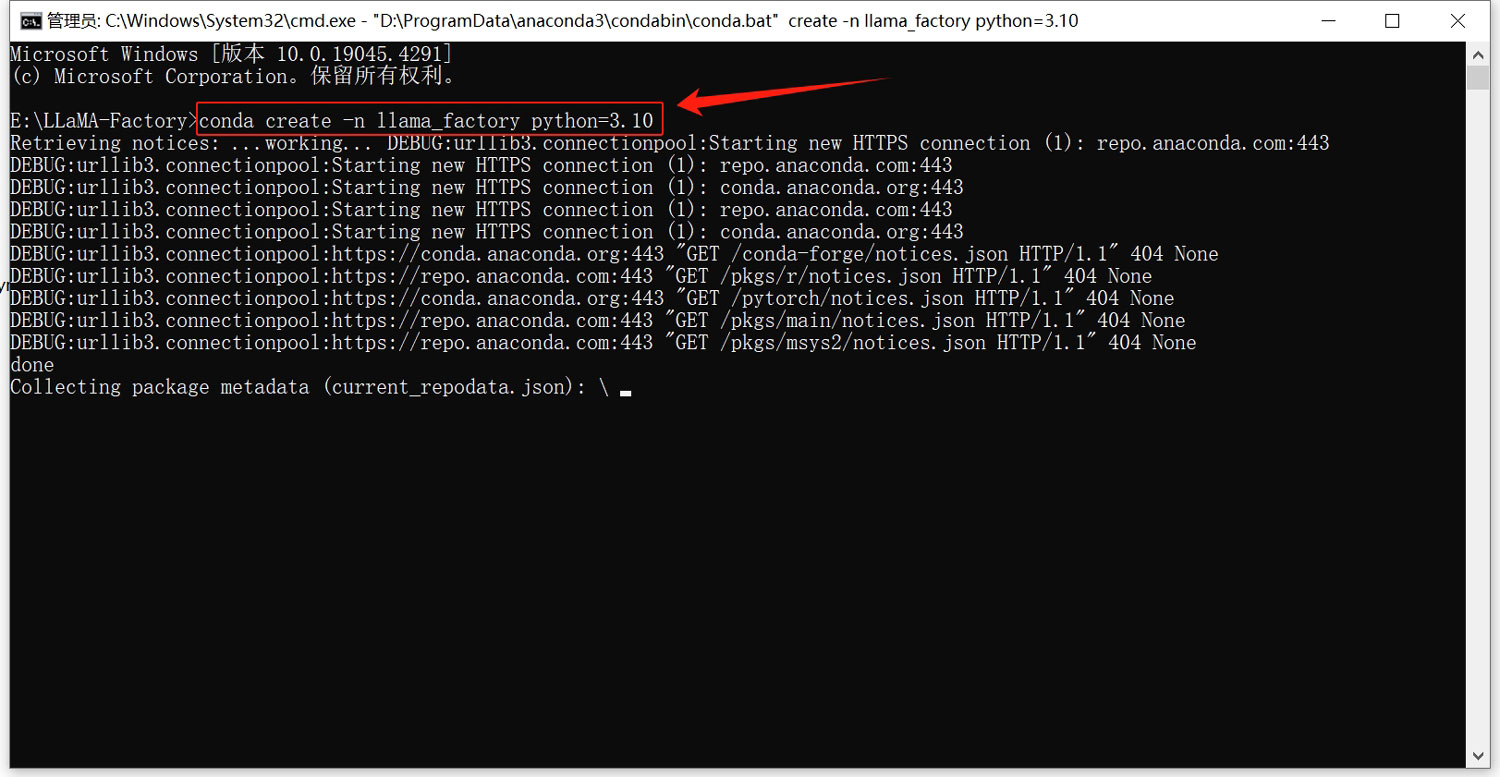
在cmd命令窗口输入下面的命令,新建一个虚拟环境
conda create -n llama_factory python=3.10 -y
输入如下命令,激活该虚拟环境!
conda activate llama_factory
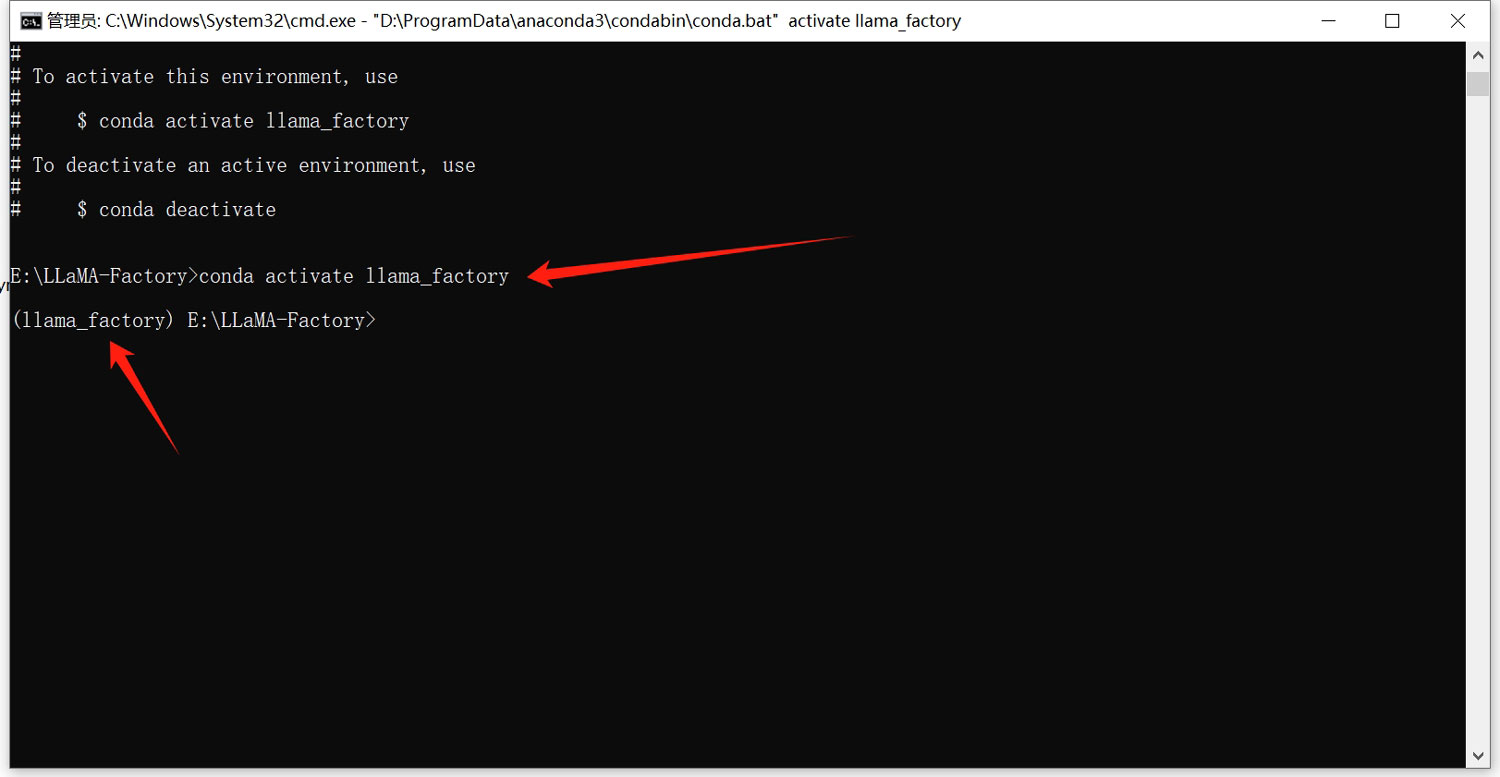
当命令输入行前面是一个括号包括的虚拟环境名称的时候,就表示已经进入到了该新建的虚拟环境中了!
安装项目依赖
继续在虚拟环境中运行下面的命令,安装各种项目依赖!
pip install -e .[metrics,modelscope,qwen]
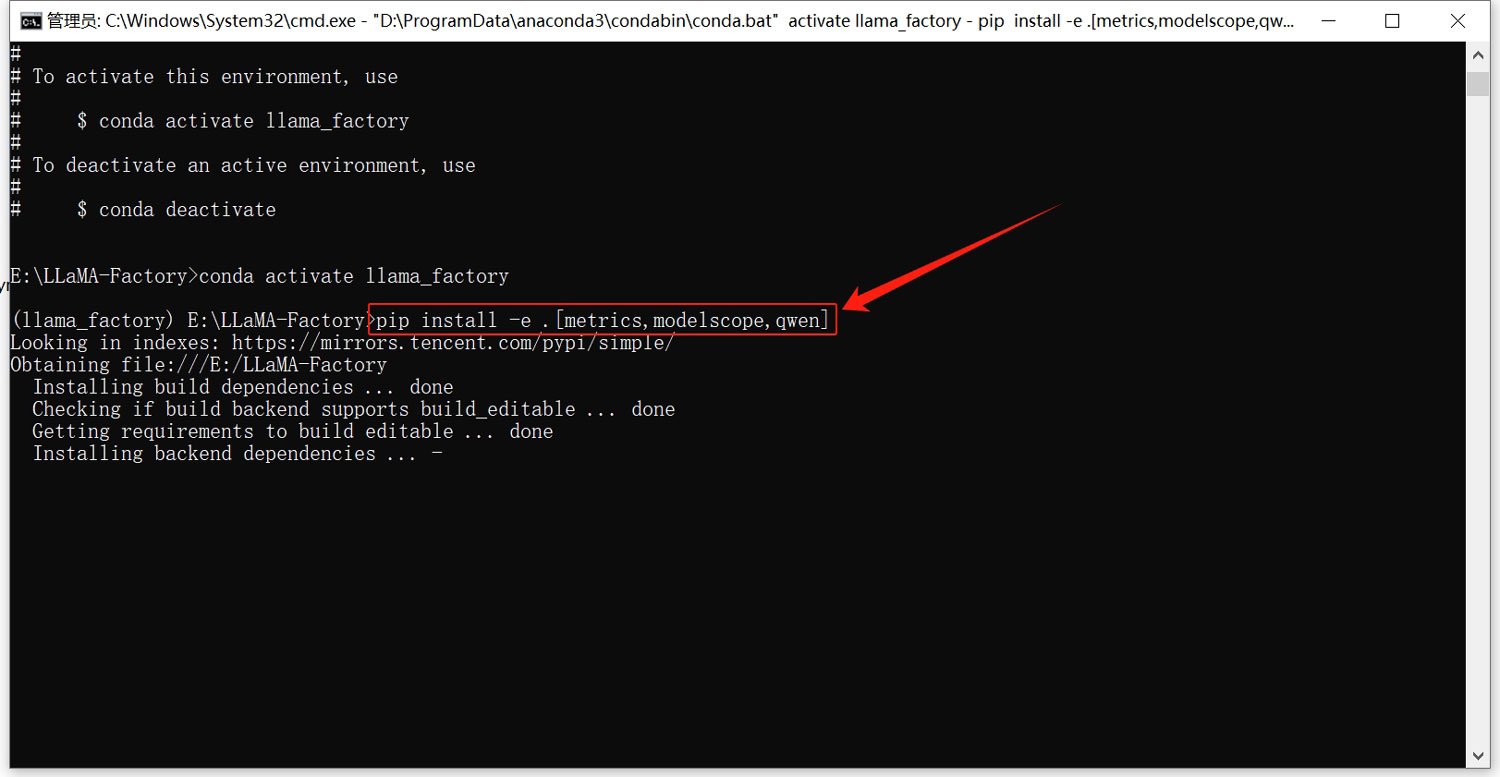
pip3 install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu121
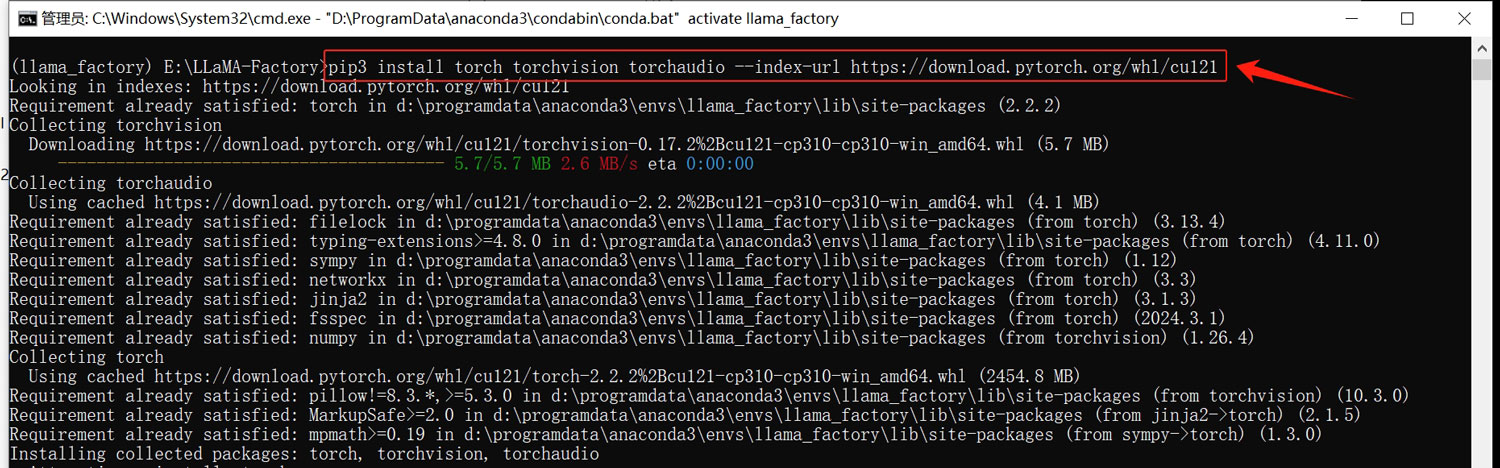
pip install https://github.com/jllllll/bitsandbytes-windows-webui/releases/download/wheels/bitsandbytes-0.41.2.post2-py3-none-win_amd64.whl
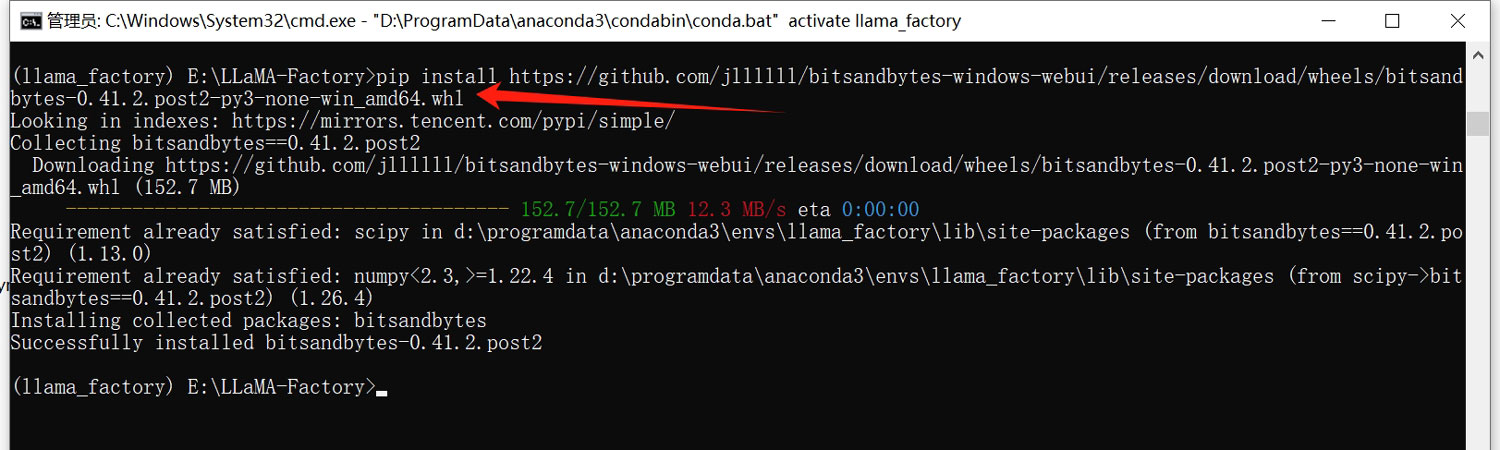
安装tensorboard
pip install tensorboard
设置环境变量
Set USE MODELSCOPE HUB=1
到这一步,LLaMA-Factory项目的安装就基本上完成了!
运行LLaMA-Factory
输入下面的命令,会自动打开一个web页面
python src/train_web.py

下面就是web页面初始的样子
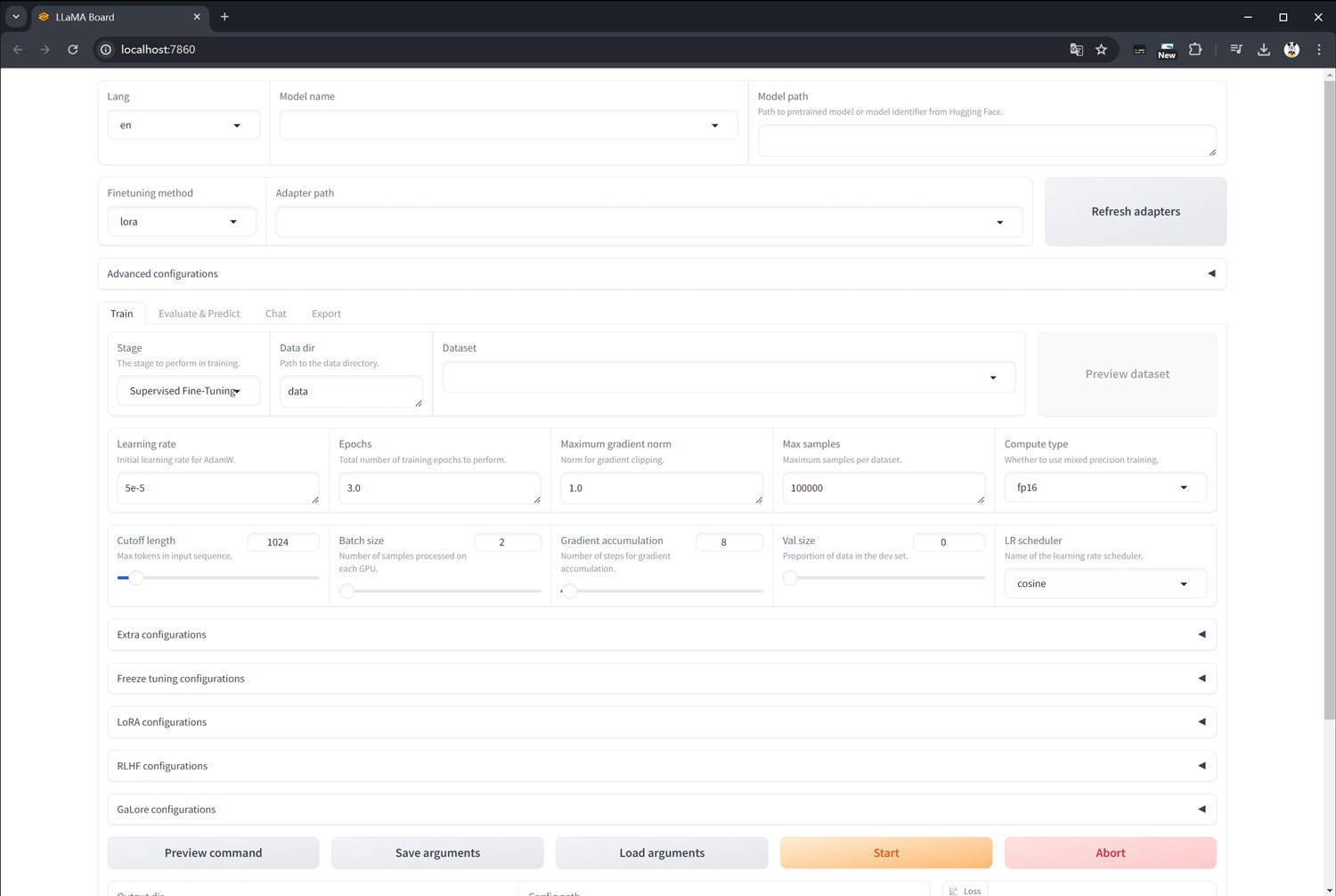
微调Meta-Llama-3-8B-Instruct模型
微调模型
在“Model name”中选择“LLaMA3-8B”,将“Model path”中的路径修改为你本地存放Meta-Llama-3-8B-Instruct文件夹的路径!
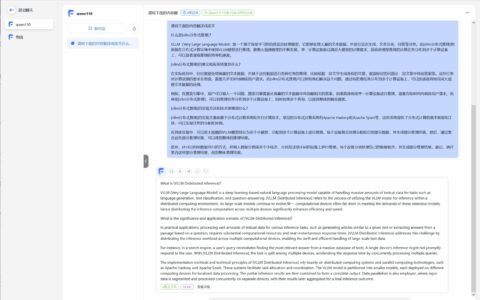
切换到“Chat”选项卡,点击“Load model”,稍等片刻,系统就会提示“Model loaded,now you can chat with your model!”!
此时,当我们用中文询问大模型问题的时候,出现英文回复的几率会比较高!(但不是绝对,毕竟Meta-Llama-3-8B-Instruct模型训练的时候也有部分中文语料)
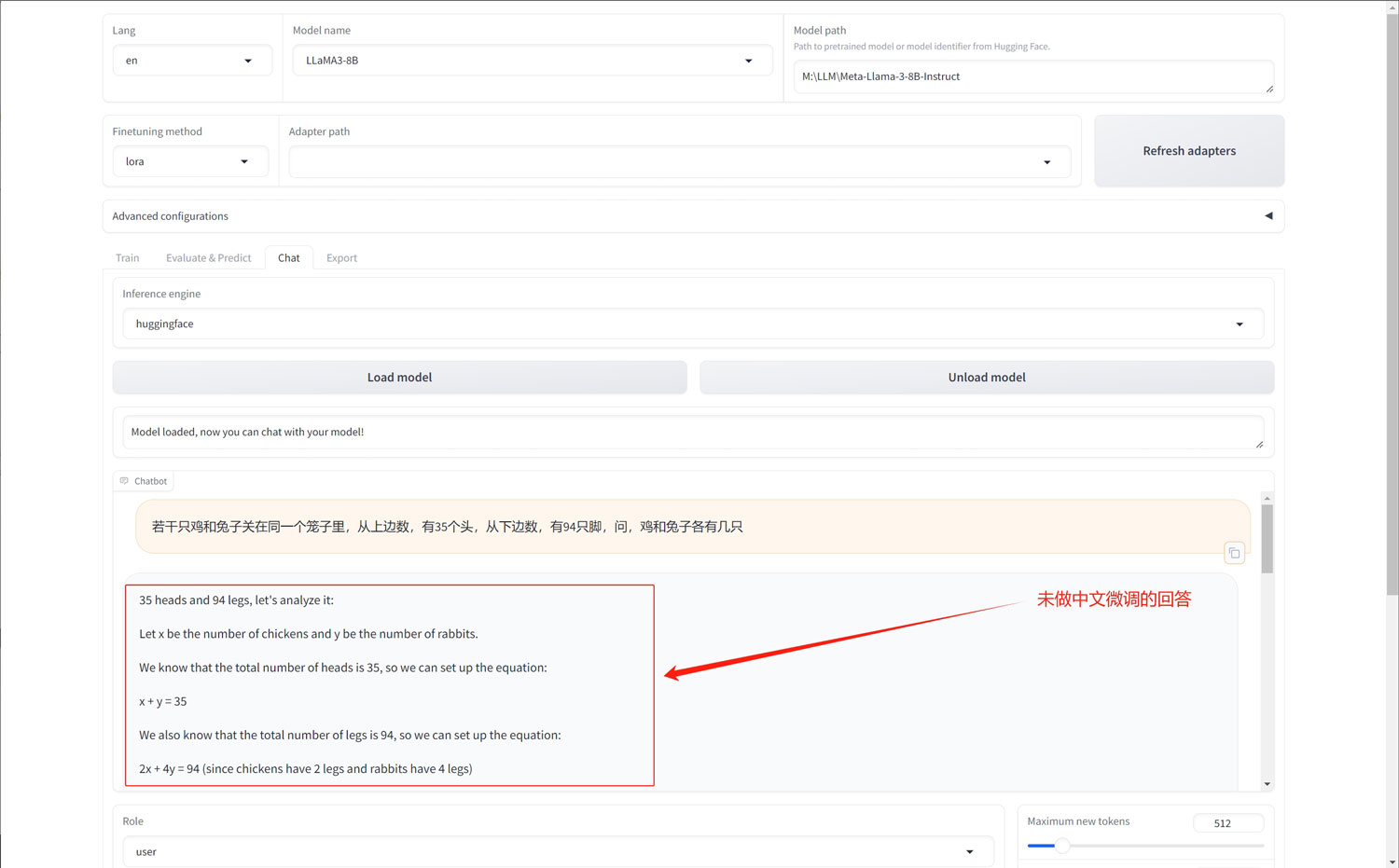
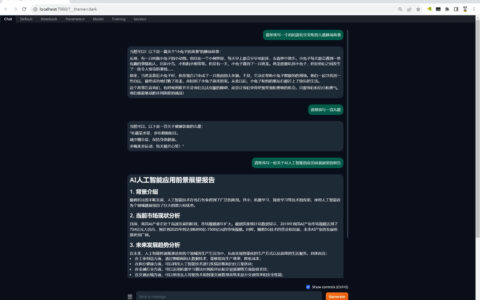
下面,我们将开始进行模型的微调,将选项卡从“Chat”,切换回“Train”
在“Dataset”中,选择若干个“_zh”结尾的数据集,为了节约显存“Cutoff length”可以修改为“512”,其他参数可以参照如下的截图!
点击“Start”将进入到模型微调的进程中!
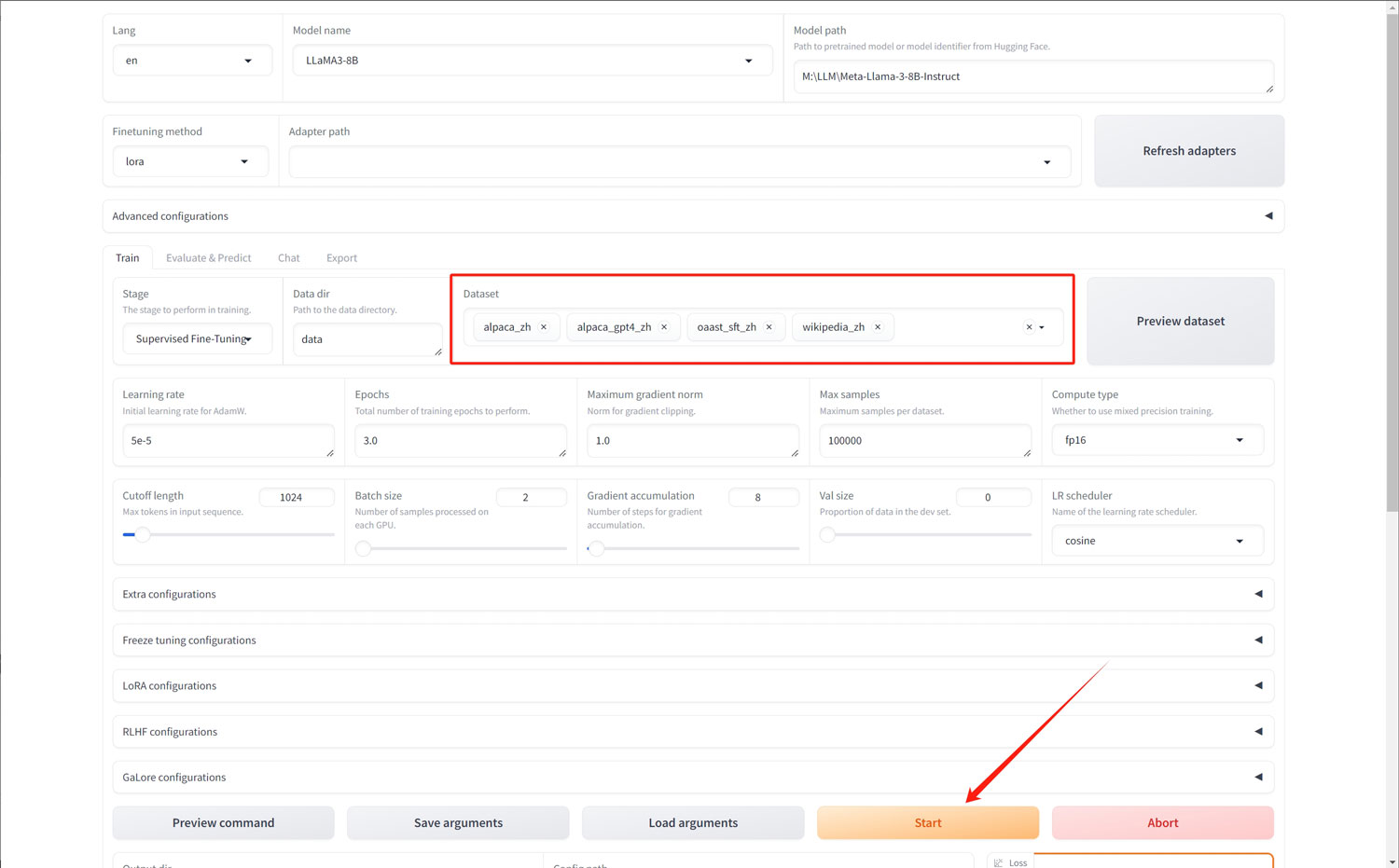
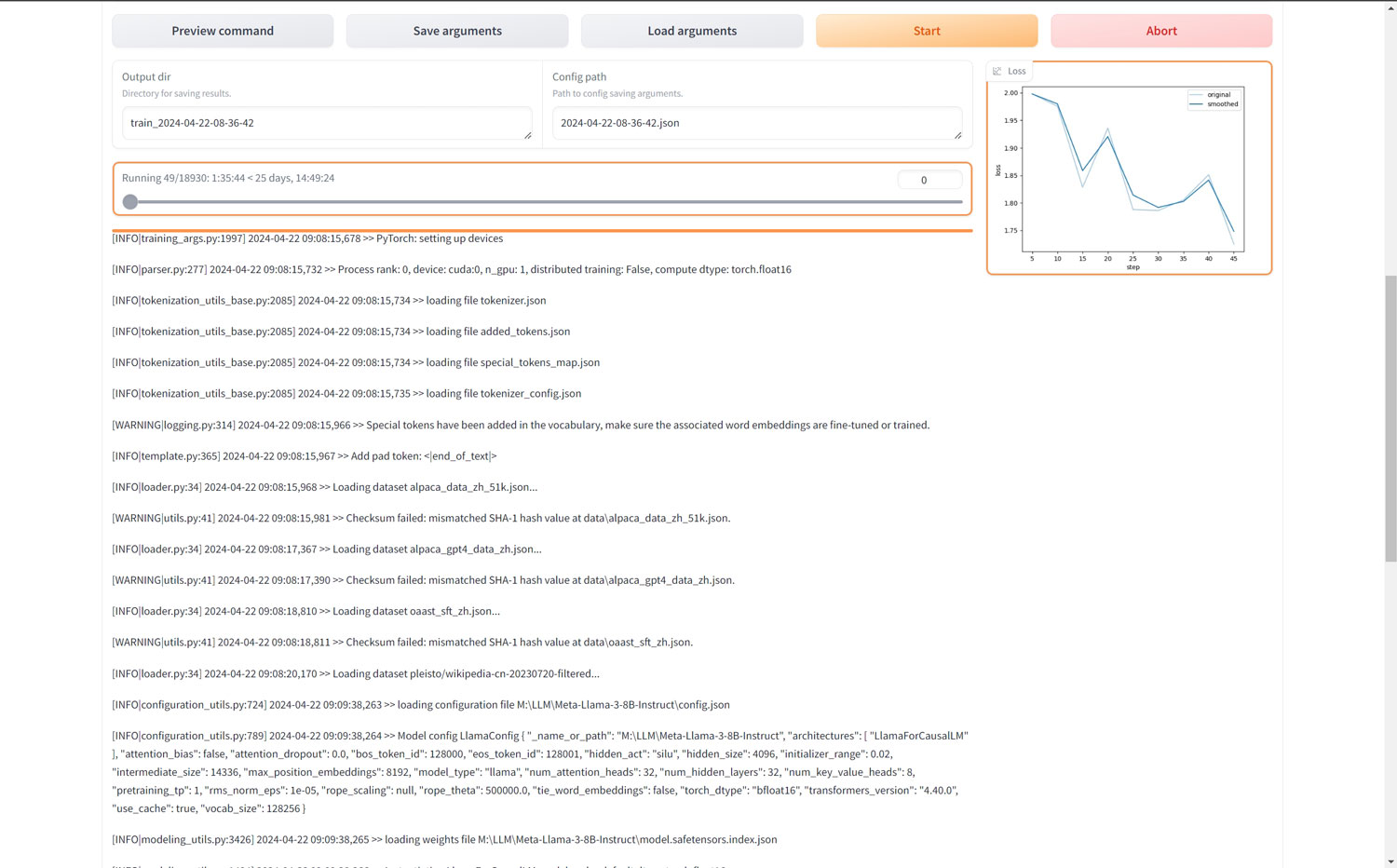
训练的时间会比较长,像本人的3090 24G显卡,下面显示的时间是14个多小时!
如果中途像终止退出的话,点击“Abort”
导出模型
1.微调训练结束之后,点击“Export”选项卡,切换到导出功能区!
2.点击“Refresh adapters”按钮,刷新lora模型,在左侧的下拉列表中选择刚刚训练好的模型!
3.在“Max shard size(GB)”中设置好每个拆分模型的最大size,案例中我设置为5;
4.在“Export dir”中设置模型保存的路径;
5.点击“Export”按钮,开始导出模型(需要点时间等待);
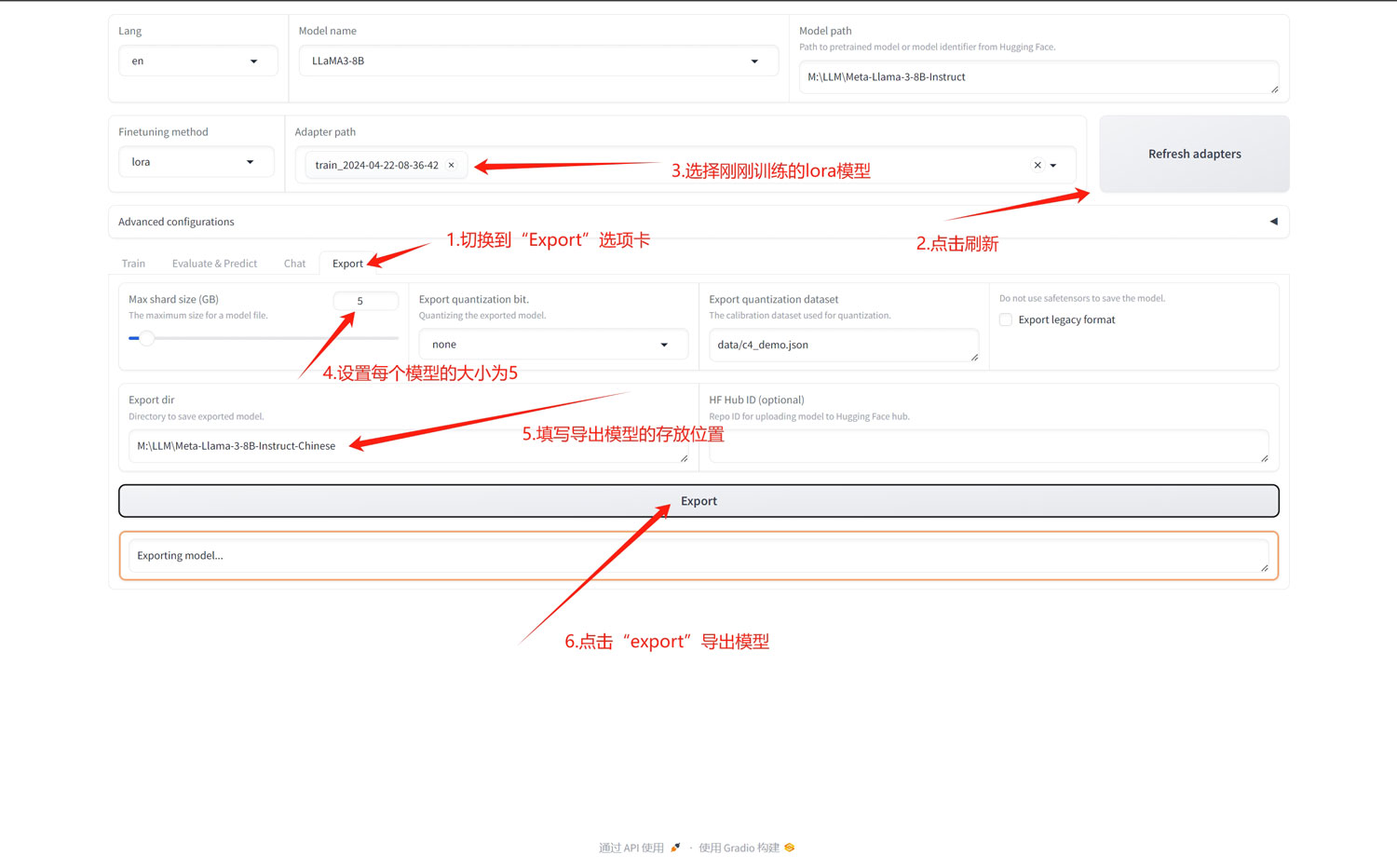
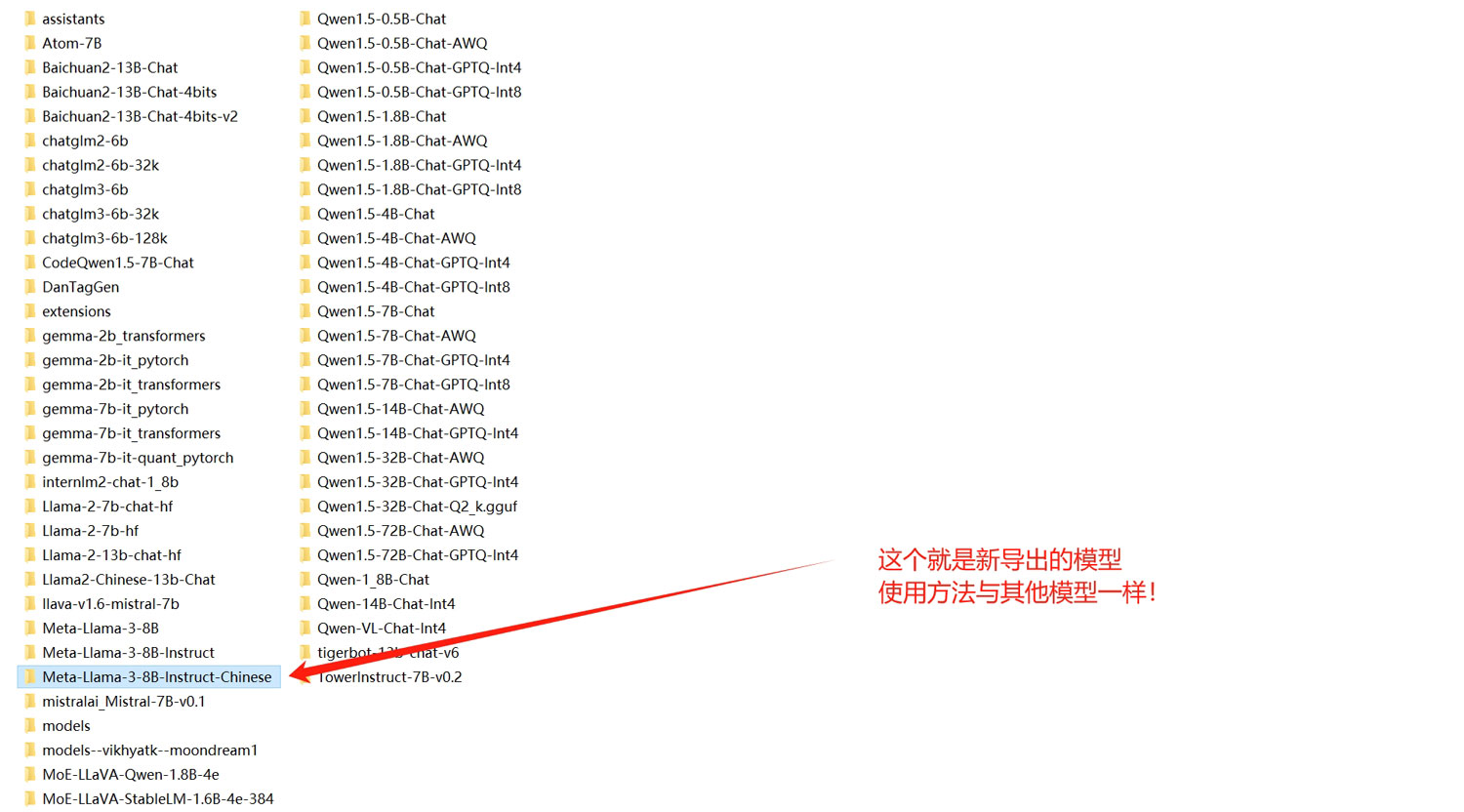
模型导出完成之后,你就可以在前面指定的路径中看到微调后的新模型了!使用方法与其他模型一样!
原创文章,作者:朋远方,如若转载,请注明出处:https://caovan.com/llama3-8b-instruct-llama-factory-zhongwenweidiao-bendebushujiaocheng/.html
 微信扫一扫
微信扫一扫 

评论列表(1条)
I don’t have this file python src/train_web.py