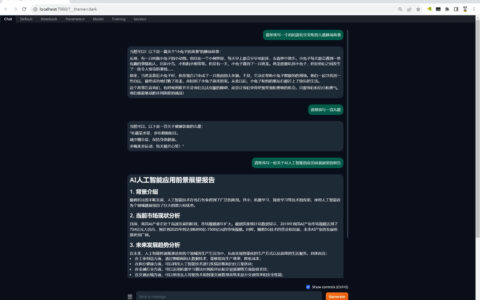
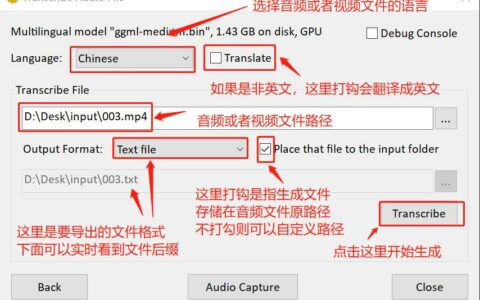
大语言模型基本信息
更新之2024年2月数据!
| 大模型 | 机构 | 类别 | 备注 |
|---|---|---|---|
| chatgpt-3.5 | openai | 商用 | 风靡世界的AI产品,API为gpt3.5-turbo |
| gpt4 | openai | 商用 | 当前世界最强AI |
| new-bing | 微软 | 商用 | bing搜索用的聊天模型,基于GPT4 |
| 文心一言 | 百度 | 商用 | 百度全新一代知识增强大语言模型,文心大模型家族的新成员,能够与人对话互动,回答问题,协助创作,高效便捷地帮助人们获取信息、知识和灵感。 |
| chatglm官方 | 智谱AI | 商用 | 一个具有问答、多轮对话和代码生成功能的中英双语模型,基于千亿基座 GLM-130B 开发,通过代码预训练、有监督微调等技术提升各项能力 |
| 讯飞星火 | 科大讯飞 | 商用 | 具有文本生成、语言理解、知识问答、逻辑推理、数学能力、代码能力、多模态能力 7 大核心能力。该大模型目前已在教育、办公、车载、数字员工等多个行业和产品中落地。 |
| 360智脑 | 奇虎360 | 商用 | – |
| 阿里通义千问 | 阿里巴巴 | 商用 | 通义千问支持多轮对话,可进行文案创作、逻辑推理,支持多种语言。 |
| senseChat | 商汤 | 商用 | 商汤推出的聊天模型 |
| minimax | minimax | 商用 | Glow app背后大模型 |
| tigerbot-7b官网 | 虎博科技 | 商用/开源 | TigerBot 是一个多语言多任务的大规模语言模型(LLM),基于bloom模型结构。该模型也有开源版本。 |
| chatglm-6b | 清华大学&智谱AI | 开源 | ChatGLM-6B 是一个开源的、支持中英双语的对话语言模型,基于 General Language Model (GLM) 架构,具有 62 亿参数。结合模型量化技术,用户可以在消费级的显卡上进行本地部署(INT4 量化级别下最低只需 6GB 显存)。 ChatGLM-6B 使用了和 ChatGPT 相似的技术,针对中文问答和对话进行了优化。经过约 1T 标识符的中英双语训练,辅以监督微调、反馈自助、人类反馈强化学习等技术的加持,62 亿参数的 ChatGLM-6B 已经能生成相当符合人类偏好的回答 |
| belle-llama-7b-2m | 链家科技 | 开源 | based on LLAMA 7B and finetuned with 2M Chinese data combined with 50,000 pieces of English data from the open source Stanford-Alpaca, resulting in good Chinese instruction understanding and response generation capabilities. |
| BELLE-on-Open-Datasets | 链家科技 | 开源 | Extending the vocabulary with additional 50K tokens specific for Chinese and further pretraining these word embeddings on Chinese corpus. Full-parameter finetuning the model with instruction-following open datasets: alpaca, sharegpt, belle-3.5m. |
| belle-llama-13b-2m | 链家科技 | 开源 | based on LLAMA 13B and finetuned with 2M Chinese data combined with 50,000 pieces of English data from the open source Stanford-Alpaca. |
| belle-llama-13b-ext | 链家科技 | 开源 | Extending the vocabulary with additional 50K tokens specific for Chinese and further pretraining these word embeddings on Chinese corpus. Full-parameter finetuning the model with 4M high-quality instruction-following examples. |
| BELLE-Llama2-13B-chat-0.4M | 链家科技 | 开源 | This model is obtained by fine-tuning the complete parameters using 0.4M Chinese instruction data on the original Llama2-13B-chat. |
| Ziya-LLaMA-13B-v1 | IDEA研究院 | 开源 | 从LLaMA-13B开始重新构建中文词表,进行千亿token量级的已知的最大规模继续预训练,使模型具备原生中文能力。再经过500万条多任务样本的有监督微调(SFT)和综合人类反馈训练(RM+PPO+HFFT+COHFT+RBRS),进一步激发和加强各种AI任务能力。 |
| Ziya-LLaMA-13B-v1.1 | IDEA研究院 | 开源 | 对Ziya-LLaMA-13B-v1模型进行继续优化,通过调整微调数据的比例和采用更优的强化学习策略,本版本在问答准确性、数学能力以及安全性等方面得到了提升 |
| guanaco-7b | JosephusCheung | 开源 | Guanaco is an advanced instruction-following language model built on Meta’s LLaMA 7B model. Expanding upon the initial 52K dataset from the Alpaca model, an additional 534K+ entries have been incorporated, covering English, Simplified Chinese, Traditional Chinese (Taiwan), Traditional Chinese (Hong Kong), Japanese, Deutsch, and various linguistic and grammatical tasks. This wealth of data enables Guanaco to perform exceptionally well in multilingual environments. |
| phoenix-inst-chat-7b | 香港中文大学 | 开源 | 基于BLOOMZ-7b1-mt,用Instruction + Conversation数据微调,具体数据见phoenix-sft-data-v1 |
| linly-chatflow-13b | 深圳大学 | 开源 | 基于llama-13b,用5M 指令数据微调 |
| Linly-Chinese-LLaMA2-13B | 深圳大学 | 开源 | Linly-Chinese-LLaMA2 基于 LLaMA2进行中文化训练,使用课程学习方法跨语言迁移,词表针对中文重新设计,数据分布更均衡,收敛更稳定。 |
| MOSS-003-SFT | 复旦大学 | 开源 | MOSS是一个支持中英双语和多种插件的开源对话语言模型,moss-moon系列模型具有160亿参数,在FP16精度下可在单张A100/A800或两张3090显卡运行,在INT4/8精度下可在单张3090显卡运行。MOSS基座语言模型在约七千亿中英文以及代码单词上预训练得到,后续经过对话指令微调、插件增强学习和人类偏好训练具备多轮对话能力及使用多种插件的能力。 |
| AquilaChat-7B | 智源研究院 | 开源 | 悟道·天鹰(Aquila) 语言大模型是首个具备中英双语知识、支持商用许可协议、国内数据合规需求的开源语言大模型。AquilaChat 对话模型支持流畅的文本对话及多种语言类生成任务,通过定义可扩展的特殊指令规范,实现 AquilaChat对其它模型和工具的调用,且易于扩展。 |
| tulu-30b | allenai | 开源 | We explore instruction-tuning popular base models on publicly available datasets. As part of this work we introduce Tülu, a suite of LLaMa models fully-finetuned on a strong mix of datasets! |
| chatglm2-6b | 清华大学&智谱AI | 开源 | ChatGLM2-6B 是ChatGLM-6B 的第二代版本,更强大的性能,上下文长度从2K 扩展到了 32K,推理速度相比初代提升了 42%,允许商业使用。 |
| Baichuan-13B-Chat | 百川智能 | 开源 | Baichuan-13B 是由百川智能继 Baichuan-7B 之后开发的包含 130 亿参数的开源可商用的大规模语言模型,在权威的中文和英文 benchmark 上均取得同尺寸最好的效果。 |
| vicuna-33b | UC伯克利 | 开源 | Vicuna is a chat assistant trained by fine-tuning LLaMA on user-shared conversations collected from ShareGPT. |
| wizardlm-13b | 微软 | 开源 | WizardLM: An Instruction-following LLM Using Evol-Instruct |
| InternLM-Chat-7B | 上海人工智能实验室 | 开源 | 使用上万亿高质量语料,建立模型超强知识体系;支持8k语境窗口长度,实现更长输入与更强推理体验;通用工具调用能力,支持用户灵活自助搭建流程。 |
| Llama-2-70b-chat | meta | 开源 | Meta developed and publicly released the Llama 2 family of large language models (LLMs), a collection of pretrained and fine-tuned generative text models ranging in scale from 7 billion to 70 billion parameters. Our fine-tuned LLMs, called Llama-2-Chat, are optimized for dialogue use cases. Llama-2-Chat models outperform open-source chat models on most benchmarks we tested, and in our human evaluations for helpfulness and safety, are on par with some popular closed-source models like ChatGPT and PaLM. |
原创文章,作者:朋远方,如若转载,请注明出处:https://caovan.com/zhongwendayuyinmoxingllmhuizong/.html
 微信扫一扫
微信扫一扫