数据类型
Pandas的基本数据类型是dataframe和series两种,也就是行和列的形式,dataframe是多行多列,series是单列多行。
如果在jupyter notebook里面使用pandas,那么数据展示的形式像excel表一样,有行字段和列字段,还有值。
简单来说,Pandas是编程界的Excel。
Pandas简介
Pandas诞生于2008年,它的开发者是Wes McKinney,一个量化金融分析工程师。因为疲于应付繁杂的财务数据,Wes McKinney便自学Python,并开发了Pandas。
为什么叫作Pandas,其实这是“Python data analysis”的简写,同时也衍生自计量经济学术语“panel data”(面板数据)。所以说Pandas的诞生是为了分析金融财务数据,当然现在它已经应用在各个领域了。
Pandas能做什么呢?
它可以帮助你任意探索数据,对数据进行读取、导入、导出、连接、合并、分组、插入、拆分、透视、索引、切分、转换等,以及可视化展示、复杂统计、数据库交互、web爬取等。
同时Pandas还可以使用复杂的自定义函数处理数据,并与numpy、matplotlib、sklearn、pyspark、sklearn等众多科学计算库交互。
Pandas有一个伟大的目标,即成为任何语言中可用的最强大、最灵活的开源数据分析工具。
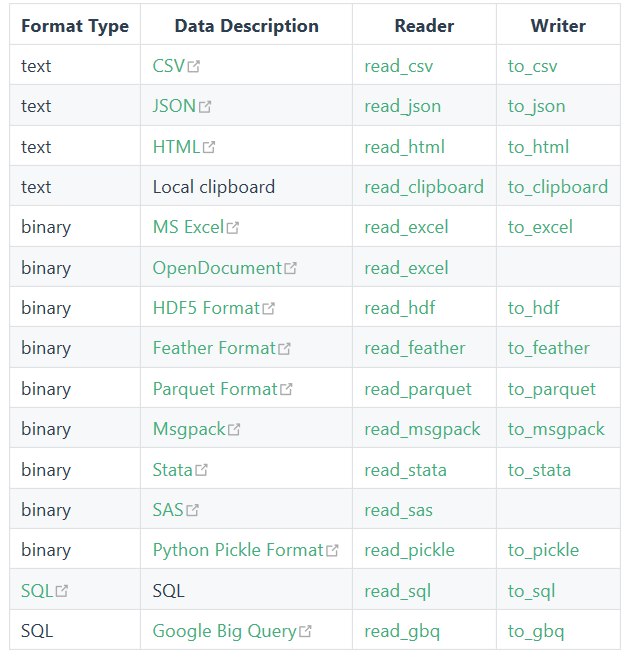
读取数据
pandas支持读取和输出多种数据类型,包括但不限于csv、txt、xlsx、json、html、sql、parquet、sas、spss、stata、hdf5,读取一般通过read_*函数实现,输出通过to_*函数实现。

数据类型
Pandas的基本数据类型是dataframe和series两种,也就是行和列的形式,dataframe是多行多列,series是单列多行。
如果在jupyter notebook里面使用pandas,那么数据展示的形式像excel表一样,有行字段和列字段,还有值。
原创文章,作者:朋远方,如若转载,请注明出处:https://caovan.com/02-yongyushujukexuede-python-jichuzhishizhipandas/.html
 微信扫一扫
微信扫一扫