GPT-SoVITS是目前为止我亲测过的效果最好的AI声音克隆程序,我甚至已经用这个程序克隆的声音做了一期完整的视频!相比较于《VALL-E X多语言文本到语音合成与语音克隆windows10本地部署教程》,GPT-SoVITS克隆的声音更加稳定,连贯性更好,下面我就来具体讲解下GPT-SoVITS在本地部署和运行的详细步骤!
GPT-SoVITS功能
-
零样本文本到语音(TTS): 输入 5 秒的声音样本,即刻体验文本到语音转换。
-
少样本 TTS: 仅需 1 分钟的训练数据即可微调模型,提升声音相似度和真实感。
-
跨语言支持: 支持与训练数据集不同语言的推理,目前支持英语、日语和中文。
-
WebUI 工具: 集成工具包括声音伴奏分离、自动训练集分割、中文自动语音识别(ASR)和文本标注,协助初学者创建训练数据集和 GPT/SoVITS 模型。
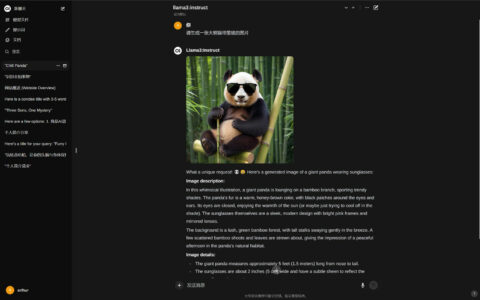
效果展示
安装方法
GPT-SoVITS的github主页:https://github.com/RVC-Boss/GPT-SoVITS
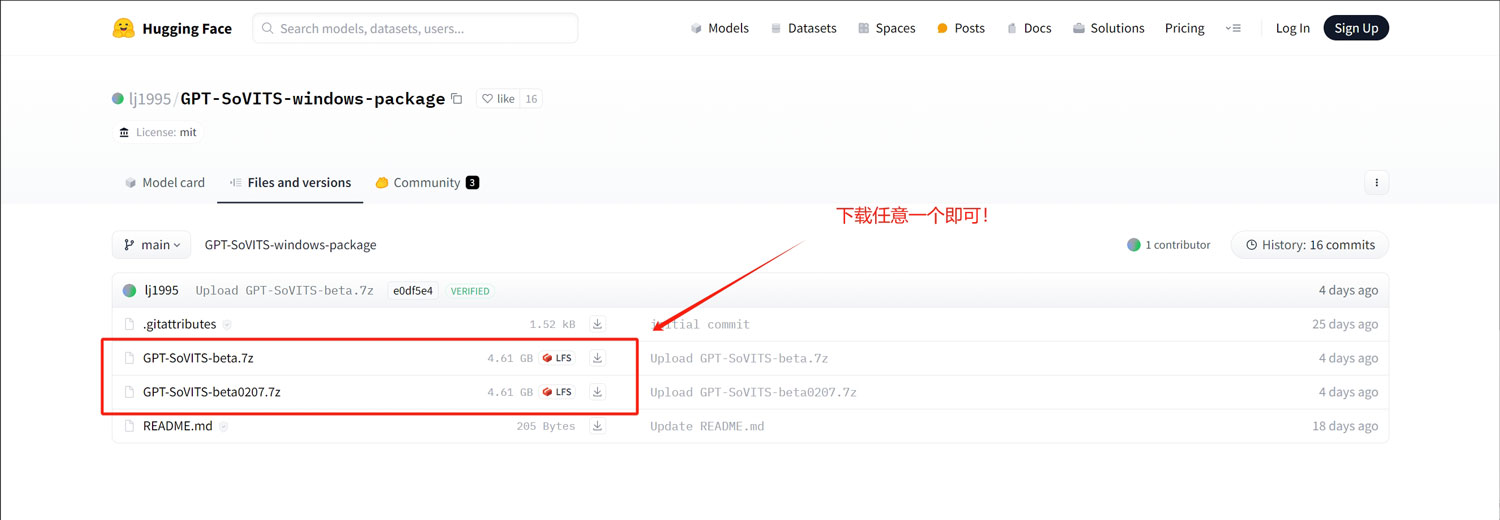
GPT-SoVITS的huggingface下载地址:https://huggingface.co/lj1995/GPT-SoVITS-windows-package/tree/main
如果你无法访问huggingface,可以点击下面的代理链接下载:
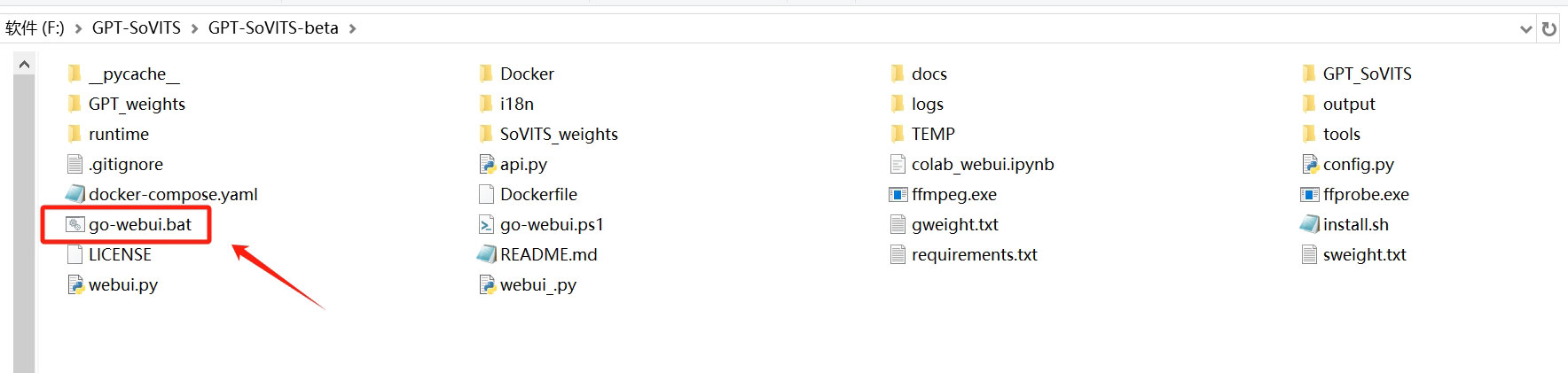
压缩包下载到本地后,解压到你自己选择的位置即可!双击“go-webui.bat”即可用运行“GPT-SoVITS”程序!
使用方法
训练模型
程序的使用分为几个步骤,当然根据自己的实际情况,其中有些步骤并非必须的!
人声伴奏分离&去混响(可选)
这个步骤并非是必须的步骤,如果你的音频文件中没有背景音乐或者其他伴奏,你可以跳过该步骤!该步骤可以将你的音频文件中的纯人声单独分离出来,以便于后面的使用!
人声分离步骤
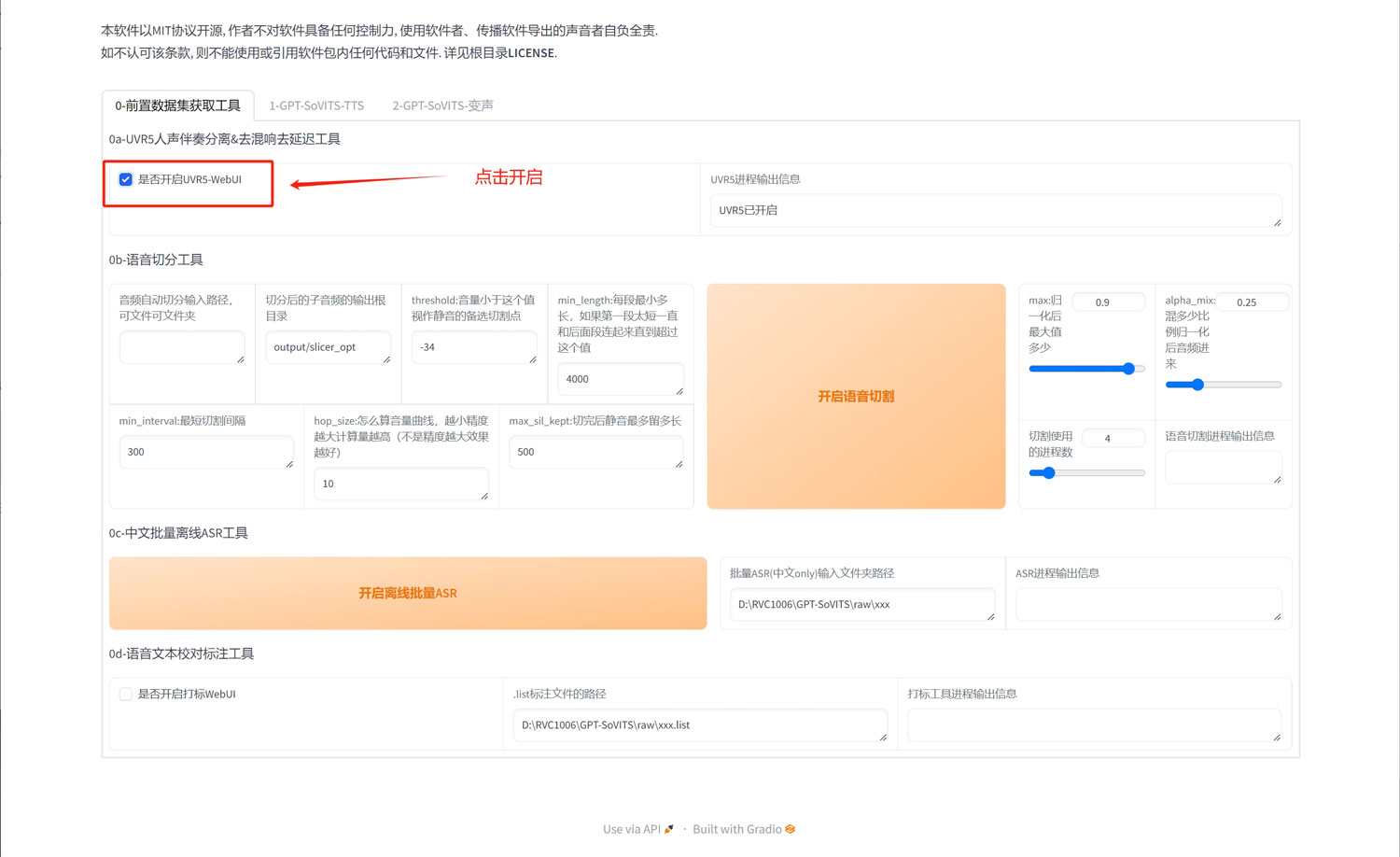
一、点选“是否开启UVR5-WebUI”,会自动弹出一个新的页面;
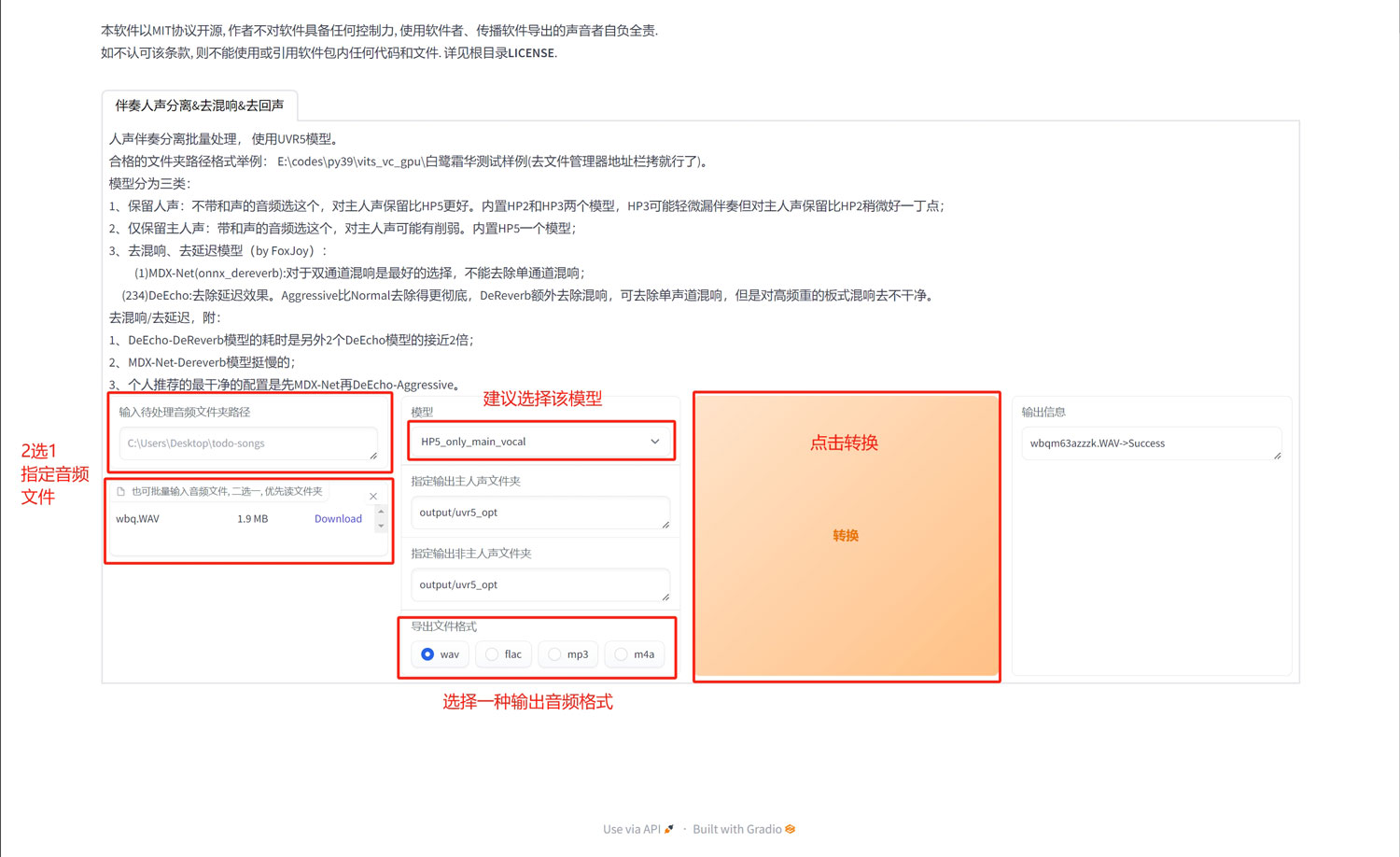
二、在新的页面中指定音频文件(可以指定包含1个或者多个音频文件的文件夹,也可以直接将音频文件拖入,2种方式二选一);
三、建议选择“HP5_only_main_vocal”模型,输出的路径可以修改为你自己指定的路径,也可以保持默认的路径,导出文件格式建议选择wav;
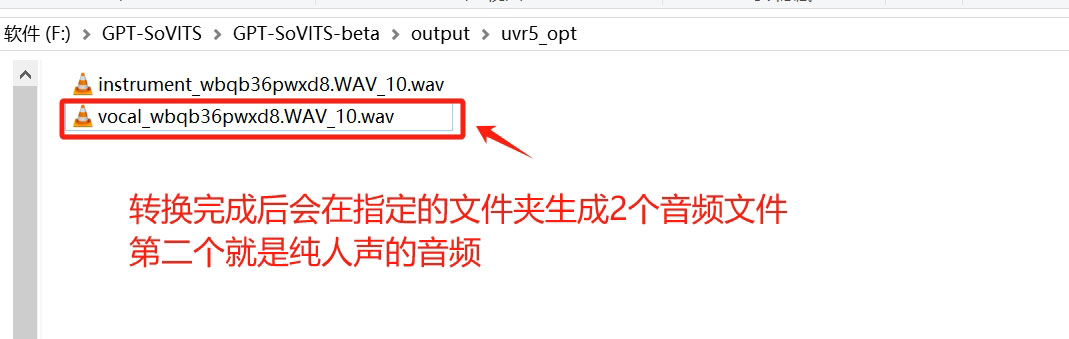
四、点击转换之后,会在设置的文件夹中生成2个音频文件,名称较短的那个就是纯人声的音频;
效果展示
原创文章,作者:朋远方,如若转载,请注明出处:https://caovan.com/kaiyuanaishengyinkelongchengxugpt-sovitsbendeyunxingjiaocheng-aishengyinkelongjiaocheng/.html
 微信扫一扫
微信扫一扫