Xorbits Inference(Xinference)是一个性能强大且功能全面的分布式推理框架。可用于大语言模型(LLM),语音识别模型,多模态模型等各种模型的推理。通过 Xorbits Inference,你可以轻松地一键部署你自己的模型或内置的前沿开源模型。无论你是研究者,开发者,或是数据科学家,都可以通过 Xorbits Inference 与最前沿的 AI 模型,发掘更多可能。
🌟 模型推理,轻而易举:大语言模型,语音识别模型,多模态模型的部署流程被大大简化。一个命令即可完成模型的部署工作。
⚡️ 前沿模型,应有尽有:框架内置众多中英文的前沿大语言模型,包括 baichuan,chatglm2 等,一键即可体验!内置模型列表还在快速更新中!
🖥 异构硬件,快如闪电:通过 ggml,同时使用你的 GPU 与 CPU 进行推理,降低延迟,提高吞吐!
⚙️ 接口调用,灵活多样:提供多种使用模型的接口,包括 OpenAI 兼容的 RESTful API(包括 Function Calling),RPC,命令行,web UI 等等。方便模型的管理与交互。
🌐 集群计算,分布协同: 支持分布式部署,通过内置的资源调度器,让不同大小的模型按需调度到不同机器,充分使用集群资源。
🔌 开放生态,无缝对接: 与流行的三方库无缝对接,包括 LangChain,LlamaIndex,Dify,以及 Chatbox。
新建一个虚拟环境
conda create --name xinference python=3.11 -c conda-forge -y && conda activate xinference
安装xinference库
pip install "xinference[all]" -i https://pypi.tuna.tsinghua.edu.cn/simple
由于国内的网络环境无法连接到huggingface,所以我们需要用一个国内的镜像源来替代huggingface
如果是临时生效,运行如下的命令
export HF_ENDPOINT="https://hf-mirror.com"
临时生效(仅在当前终端窗口)
建议采用下面这种永久生效的方案
echo 'export HF_ENDPOINT="https://hf-mirror.com"' >> ~/.bashrc source ~/.bashrc
启动xinference
XINFERENCE_HOME=/mnt/disk1/llm/xinference XINFERENCE_MODEL_SRC=modelscope xinference-local --host 0.0.0.0 --port 9997
命令说明:
XINFERENCE_HOME=/mnt/disk1/llm/xinference 是指定模型的缓存路径,这个路径是一个自定义的路径;
注册模型
纯属个人爱好,相比较于从启动模型去下载模型,我跟喜欢先把模型现在到本地,在从注册模型入口进去将模型导入到Xinference来使用!
注册语言模型案例
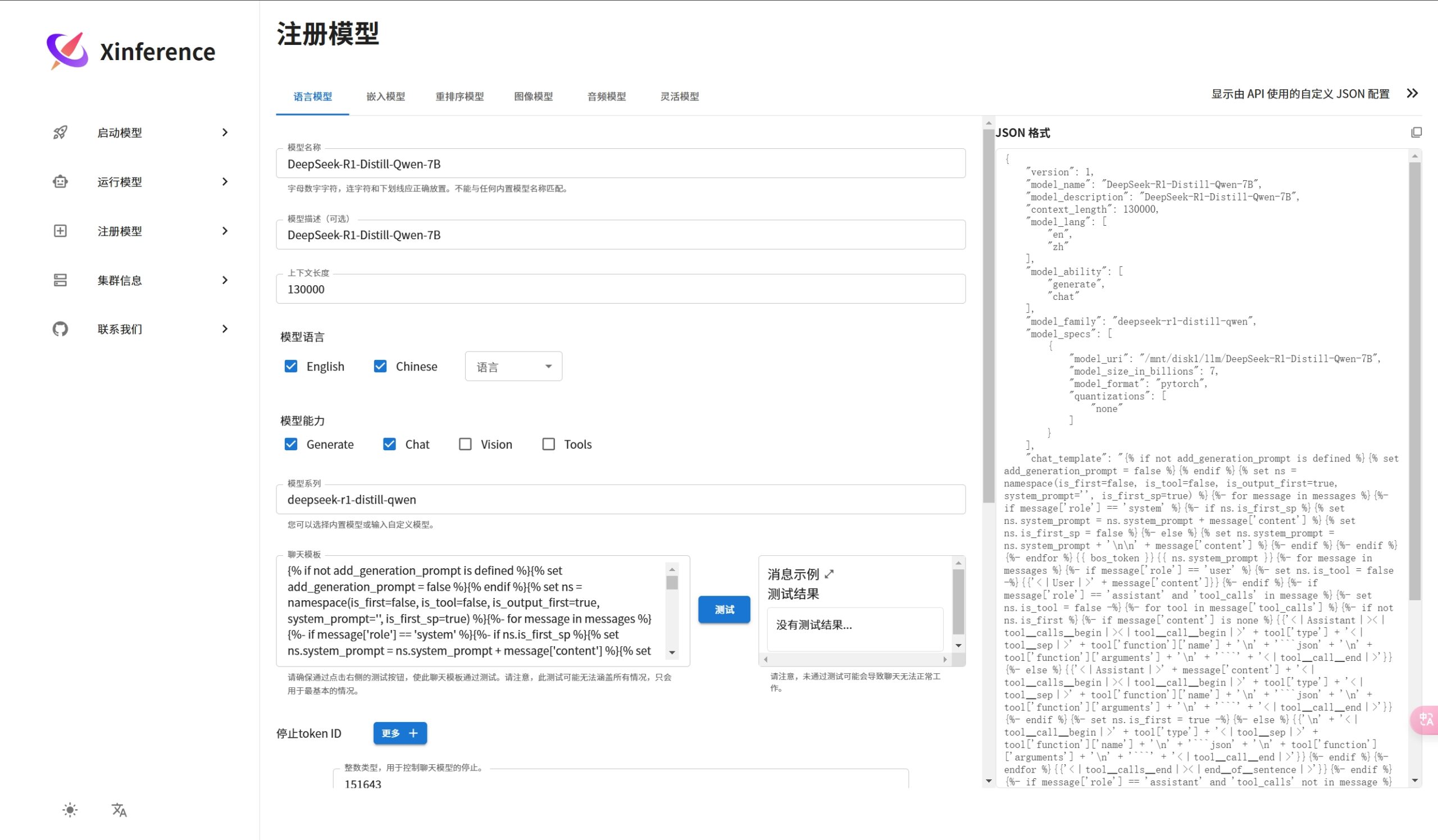
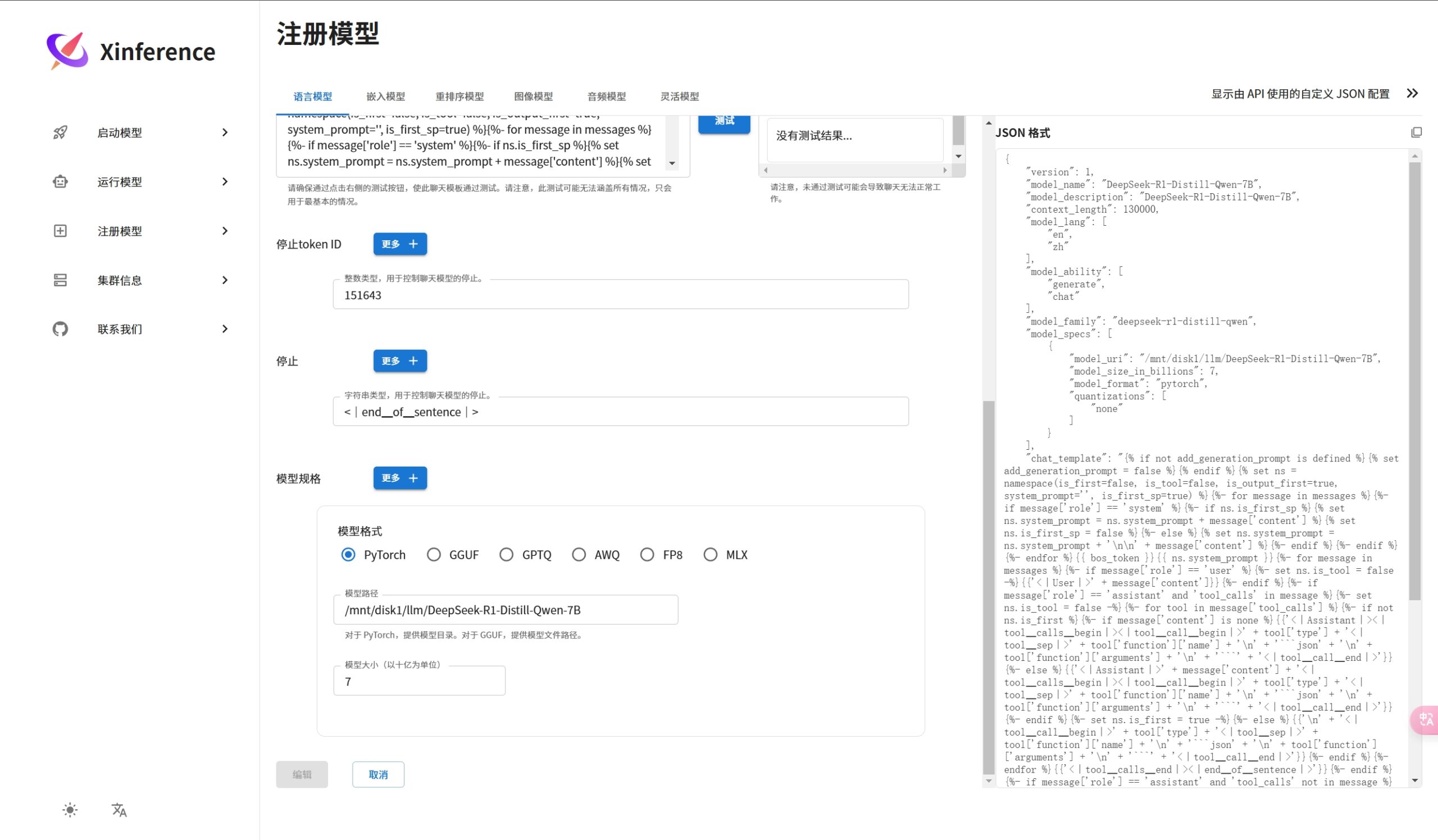
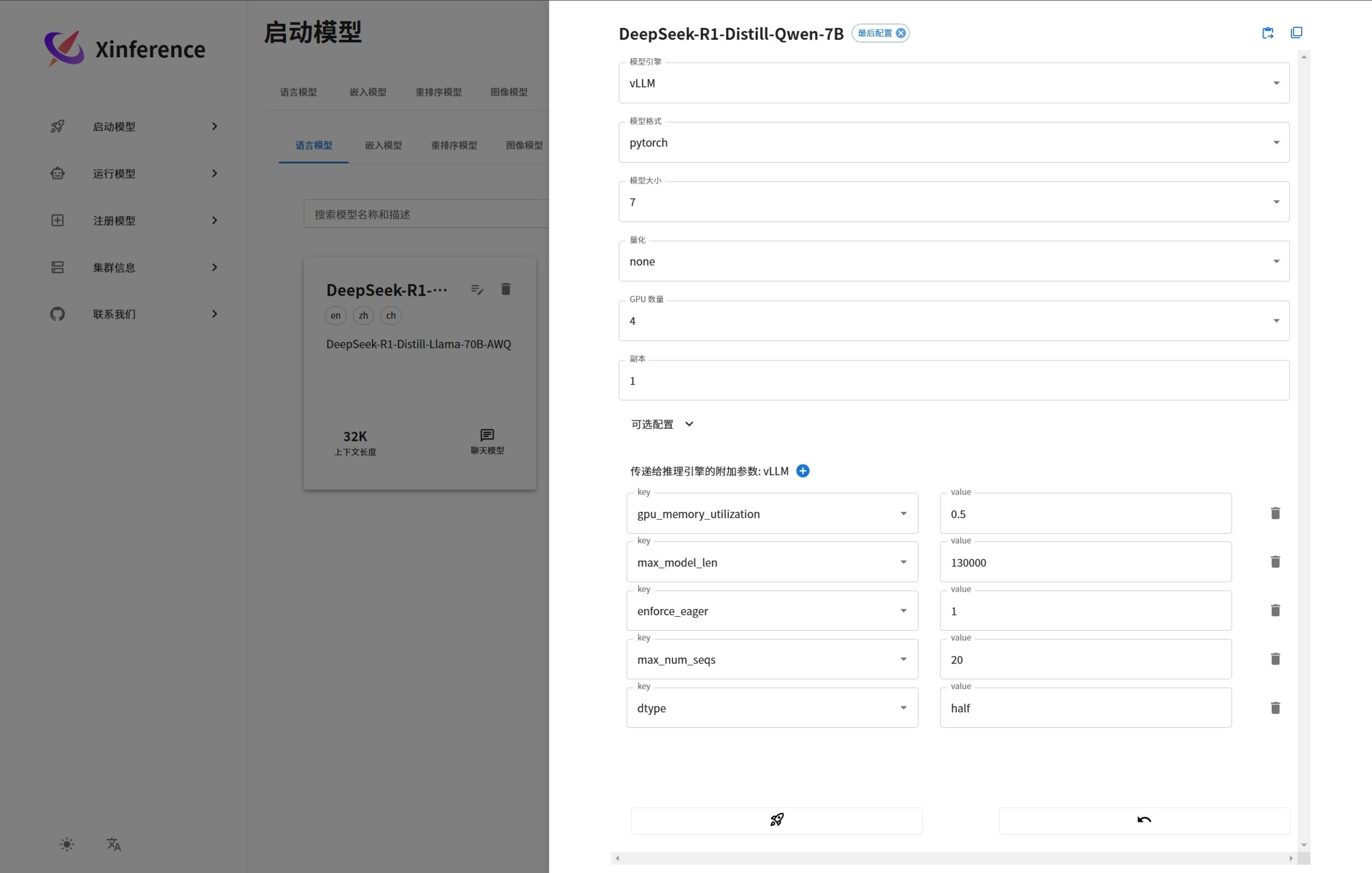
运行语言模型的案例
注册向量模型案例

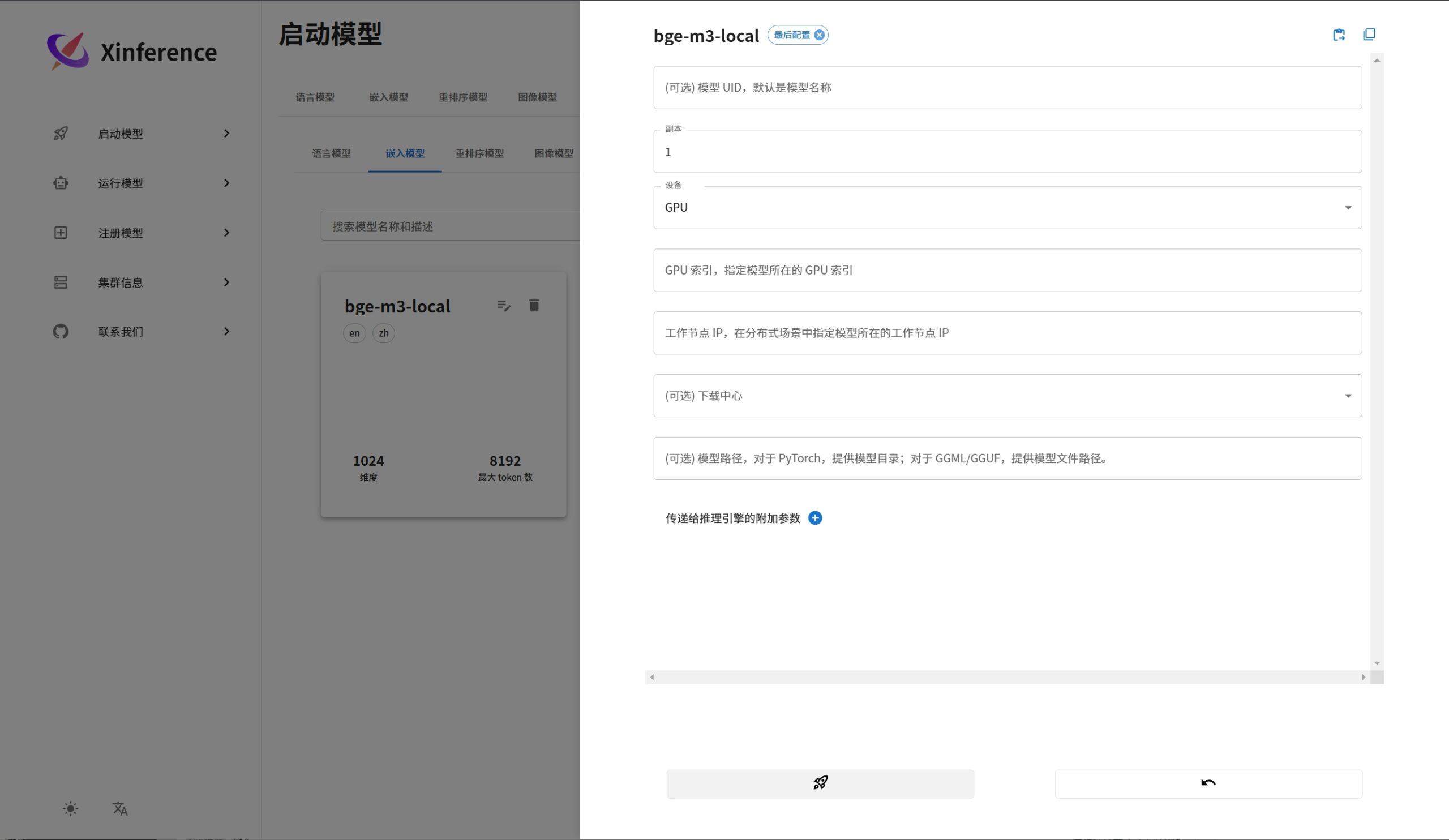
运行向量模型案例
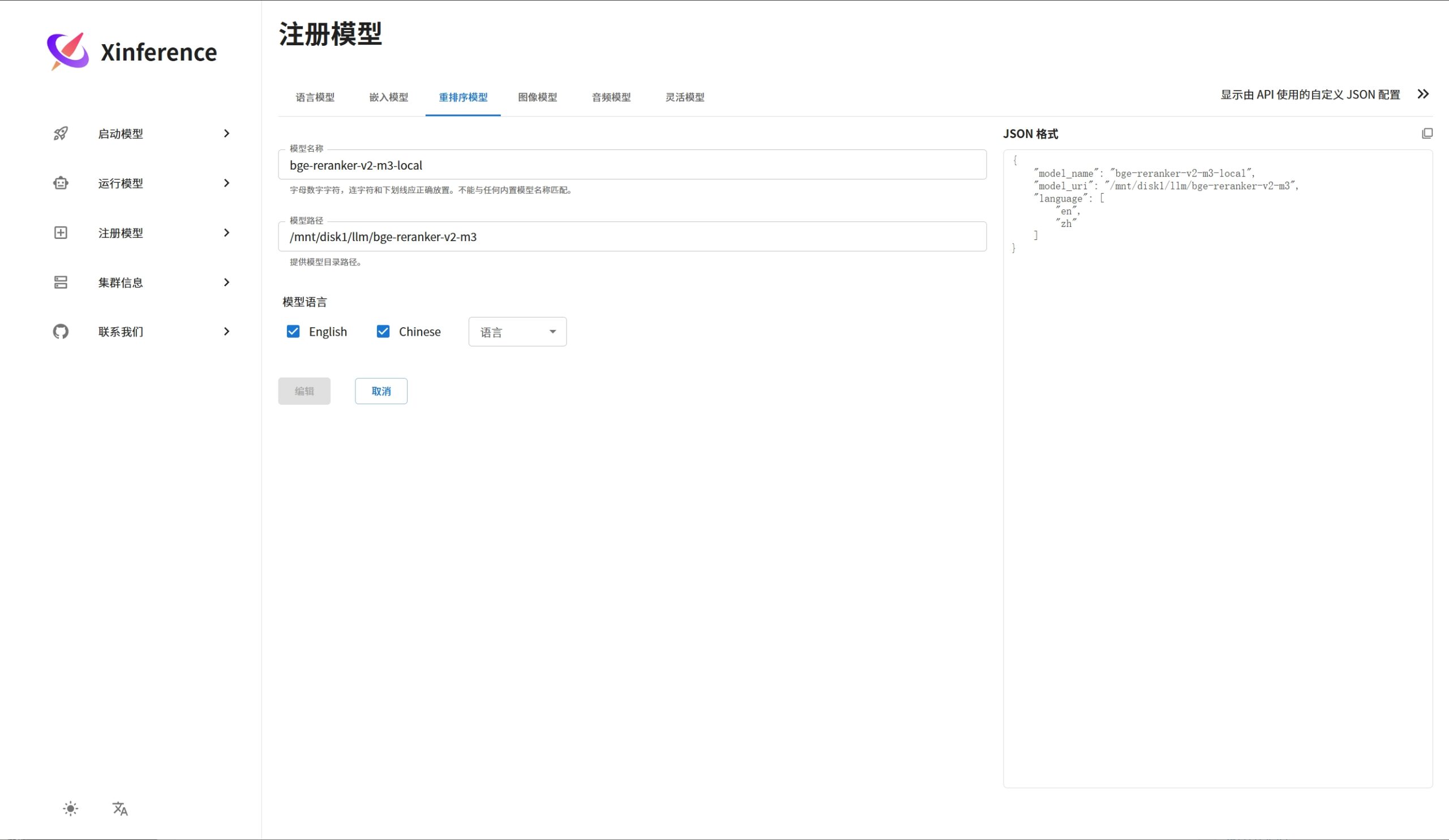
注册重排序模型案例
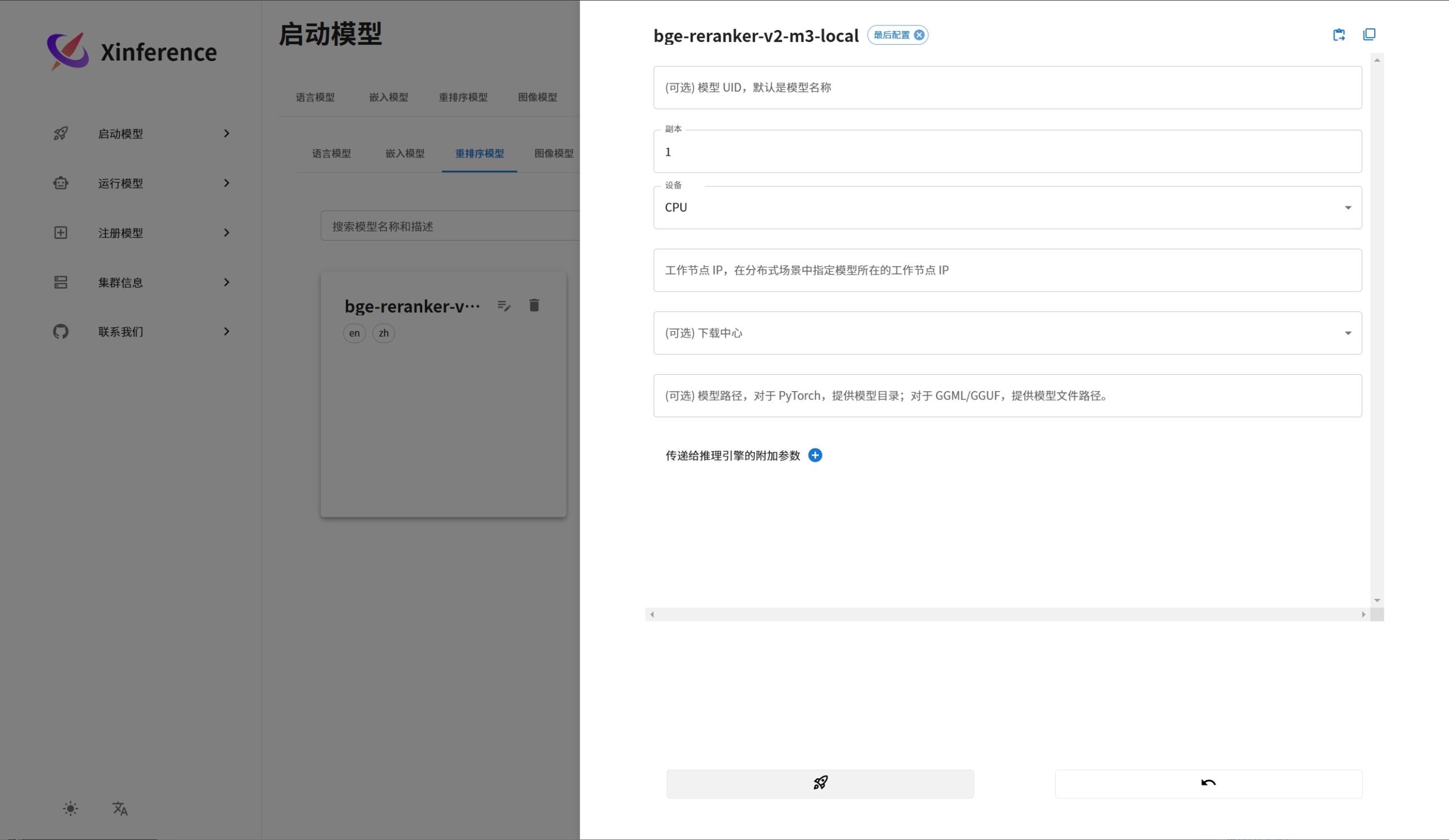
运行重排序模型案例
相关命令
停止模型并释放资源
xinference terminate --model-uid "qwen2-instruct"
原创文章,作者:朋远方,如若转载,请注明出处:https://caovan.com/ubuntufuwuqixinferencedebushuliucheng/.html
 微信扫一扫
微信扫一扫