


预测从瞎猜开始
机器学习是应用数学方法在数据中发现规律的过程。既然数学是对现实世界的解释,那么我们回归现实世界,做一些对照的想象。
想象我们面前有一块塑料泡沫做的白板,白板上分布排列着数枚蓝色的图钉,隐约地它们似乎存在着某种规律,我们试着找出规律。

白板上的图钉(数据)如上图所示,我们有没有一种方法(数学算法)来寻找规律(模型解释)呢? 既然不知道怎么做,那我们瞎猜吧!
我拿起两根木棒在白板前比划,试着用木棒表示数据的规律。我随便放了放,如下图所示:

它们似乎都在一定程度上能表示蓝色图钉的规律,那么问题来了,绿色(虚线)和红色(实线)哪一个表示更好呢?
损失函数(成本函数)
好与坏是很主观的表达,主观的感受是不可靠的,我们必须找到一种客观的度量方式。我们想当然的认为误差最小的表示,是最好的。那么,我们引出一种量化误差的方法—最小二乘法。
最小二乘法:使误差的平方和最小的办法,是一种误差统计方法,二乘就是平方的意思。
SE=∑(ypred−ytrue)2
最小二乘法的解释是这样的,我们用预测值-实际值表示单点的误差,再把它们的平方和加到一起来表示整体误差。(平方的好处可以处理掉负数值,用绝对值的和也不是不可以。)我们用这个最终值来表示损失(成本),而可以表示损失(成本)的函数就叫做损失函数(成本函数)。
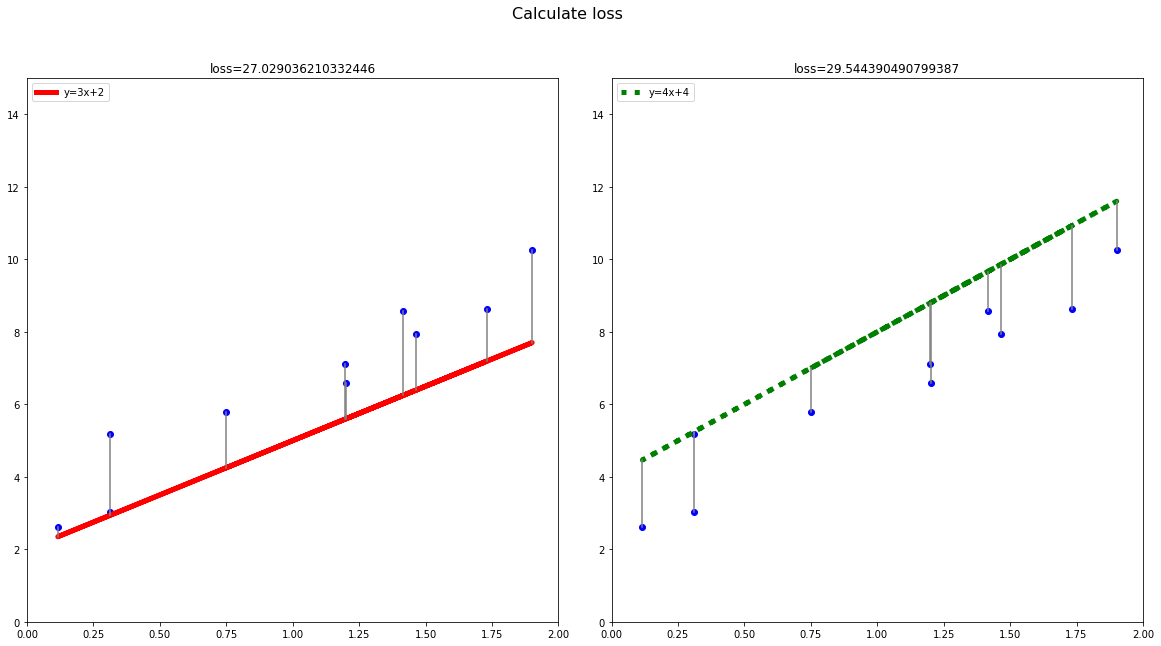
如上图我们可以看到,蓝色点到实线的距离就是我们要带入公式的误差。虽然它们看上去相近,但经过计算的结果是红色实线(y=3x+2)的损失为27.03,而绿色实线(y=4x+4)的损失为29.54,显然红色模型优于绿色模型。
那么,还有没有比红色实线更好的模型来表示数据呢?有没有一种方式来找到它呢?
原创文章,作者:朋远方,如若转载,请注明出处:https://caovan.com/07-lijiexianxinghuiguiyutiduxiajiangbingzuojiandanyuce/.html
 微信扫一扫
微信扫一扫 






![[图文对照]stable diffusion人物表情提示词大全](https://caovan.com/./uploads/2023/08/face-promptcaovan-480x300.jpg "[图文对照]stable diffusion人物表情提示词大全")