客户端(Windows)
安装paddlepaddle
安装可以参考 paddlepaddle 官网,根据自己机器的情况进行选择。

python -m pip install paddlepaddle-gpu==2.6.1 -i https://pypi.tuna.tsinghua.edu.cn/simple
安装PaddleSpeech
pip install pytest-runner pip install paddlespeech
安装兼容的其他库
pip install numpy==1.23 librosa==0.8.1 matplotlib==3.3.4
客户端案例
案例一
# -*- coding = utf-8 -*-
# @Time : 2024/6/28 12:53
# @Author : Arthur
# @FileName : main.py
# @Software : Pycharm
from paddlespeech.server.bin.paddlespeech_client import TTSOnlineClientExecutor
import simpleaudio as sa
executor = TTSOnlineClientExecutor()
executor(
input="大家好!我是玩科技的舒!欢迎来到我的频道!如果对我的频道感兴趣,欢迎订阅、评论、点赞和转发!我们下期视频再见!",
server_ip="192.168.10.107",
port=8092,
protocol="http",
spk_id=0,
output="./output.wav",
play=False)
# 播放音频文件
wave_obj = sa.WaveObject.from_wave_file("./output.wav")
play_obj = wave_obj.play()
play_obj.wait_done()
要自动播放音频文件,还需要安装下面这个库
pip install simpleaudio
案例二(流式播放):
# -*- coding = utf-8 -*-
# @Time : 2024/6/28 18:21
# @Author : Arthur
# @FileName : 流式传输.py
# @Software : Pycharm
import requests
import json
import pyaudio
import base64
class TTSOnlineClientExecutor:
def __init__(self, server_ip, port, protocol):
self.server_ip = server_ip
self.port = port
self.protocol = protocol
def tts(self, input_text, spk_id=0):
url = f"http://{self.server_ip}:{self.port}/paddlespeech/tts/streaming"
headers = {"Content-Type": "application/json"}
data = {
"text": input_text,
"spk_id": spk_id
}
response = requests.post(url, headers=headers, data=json.dumps(data), stream=True)
if response.status_code == 200:
self.play_streaming_audio(response)
else:
print(f"请求失败,状态码: {response.status_code}")
print(f"错误信息: {response.json()}")
def play_streaming_audio(self, response):
p = pyaudio.PyAudio()
stream = None
try:
for chunk in response.iter_content(chunk_size=1024):
decoded_chunk = base64.b64decode(chunk)
if not stream:
# 假设PCM音频数据格式:采样率24000,单声道,16位深度
stream = p.open(format=pyaudio.paInt16,
channels=1,
rate=24000,
output=True)
stream.write(decoded_chunk)
finally:
if stream:
stream.stop_stream()
stream.close()
p.terminate()
# 使用示例
client = TTSOnlineClientExecutor(server_ip="192.168.10.107", port=8092, protocol="http")
client.tts(input_text="大家好!我是玩科技的舒!欢迎大家来到我的频道!", spk_id=0)
服务端案例(Ubuntu系统)
项目地址:https://github.com/PaddlePaddle/PaddleSpeech/tree/develop
为每个项目创建一个单独的虚拟环境是一个好的实践,可以避免依赖冲突。以下是如何在Ubuntu上使用PaddleSpeech在虚拟环境中部署中文TTS服务的详细步骤:
安装Python虚拟环境工具
确保已经安装了virtualenv,如果没有安装,可以使用以下命令安装:
sudo apt-get update sudo apt-get install python3-venv
创建虚拟环境
在一个合适的目录下创建虚拟环境
mkdir paddlespeech_tts cd paddlespeech_tts python3 -m venv venv
激活虚拟环境
激活虚拟环境:
source venv/bin/activate
如果要退出激活的话,可以运行如下的命令:
deactivate
下面的步骤都是在该虚拟环境中进行!
安装PaddlePaddle
首先,安装PaddlePaddle。根据你的硬件环境选择适当的安装命令。这里假设你使用的是CPU:
pip install paddlepaddle
如果使用GPU,可以安装带GPU支持的PaddlePaddle(本文以GPU为例):
pip install paddlepaddle-gpu
安装PaddleSpeech
接下来,安装PaddleSpeech:
pip install paddlespeech
下载模型
模型的下载地址:
https://github.com/PaddlePaddle/PaddleSpeech/blob/develop/docs/source/released_model.md
在项目根目录新建一个子文件夹“models”
将下面的模型下载到文件中解压
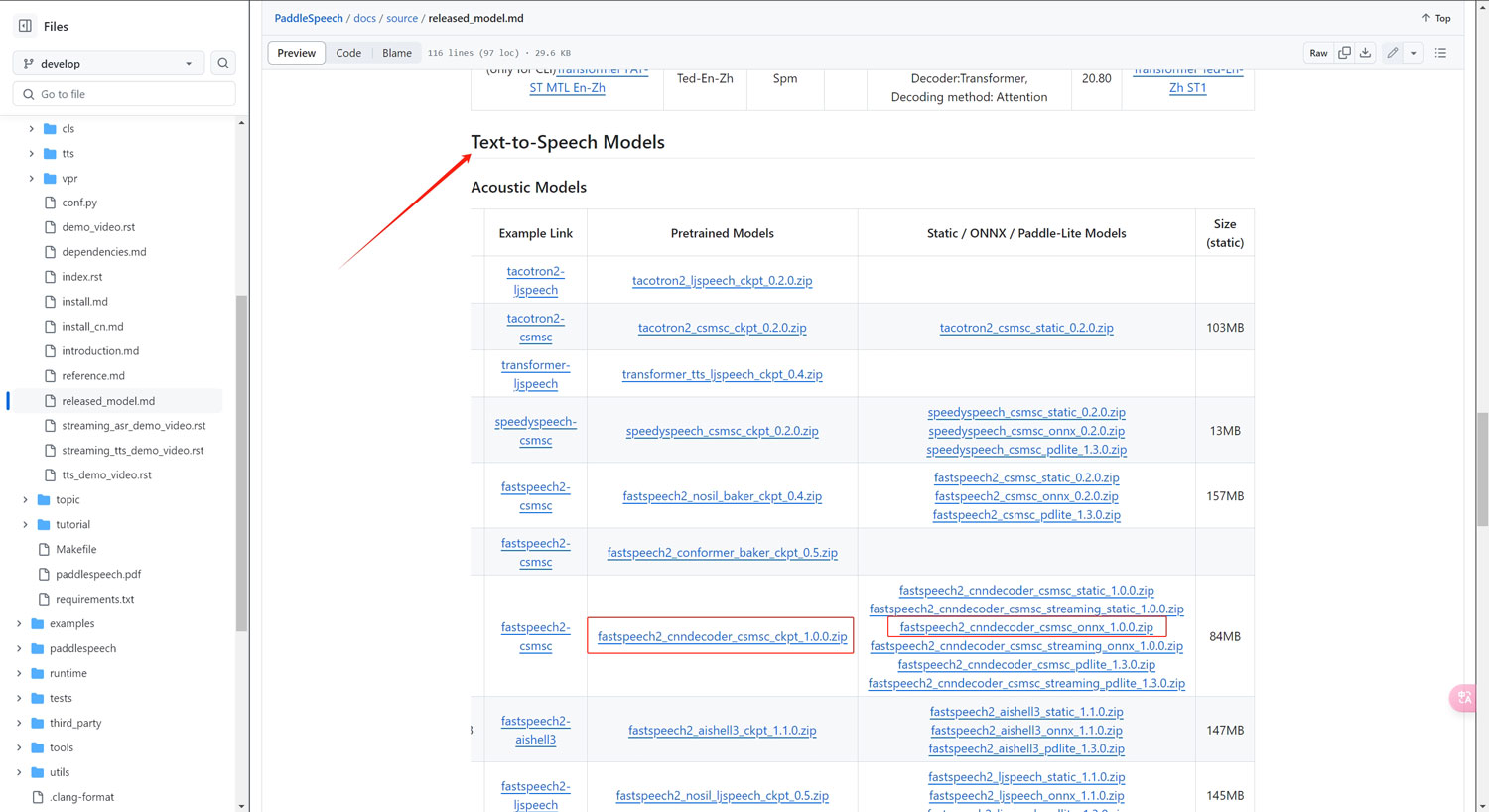
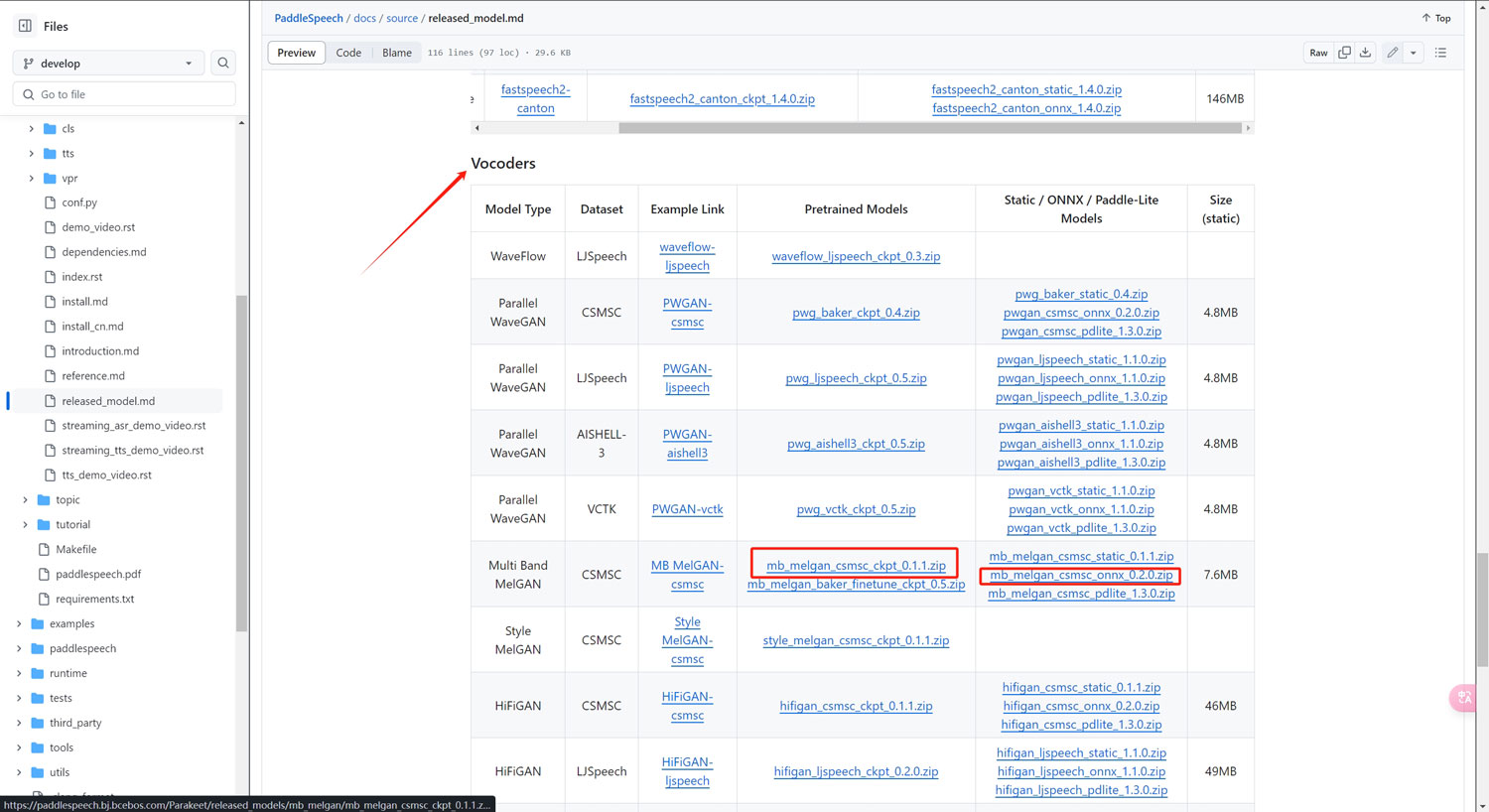
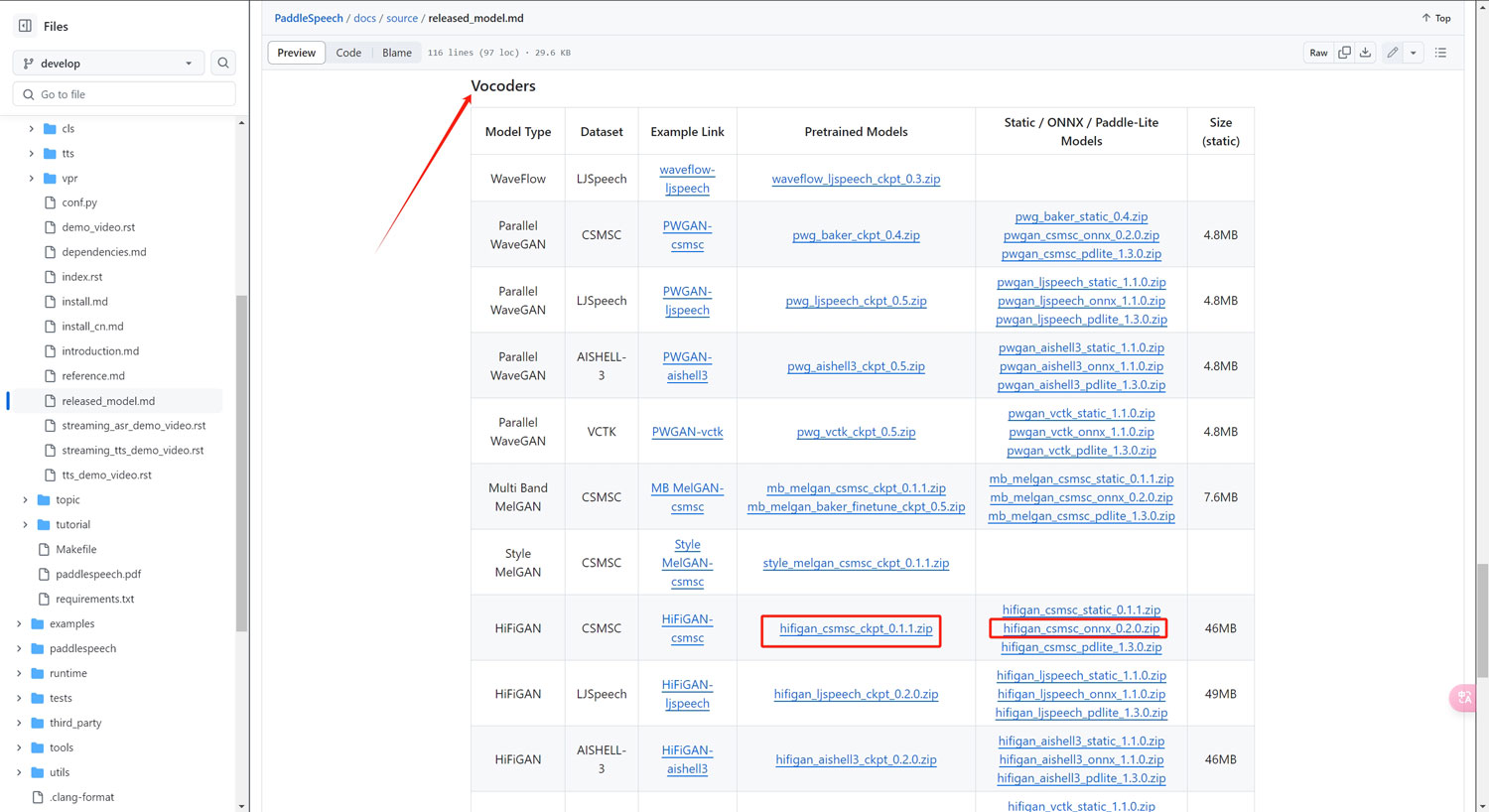
其中hifigan模型的音质更好,而mb_melgan模型的解码速度更快!这两个模型我们根据需要选择其中一个即可!
同一个模型中的ckpt版一般用在普通模式,onnx版一般用在流式传输模式!我们也根据需要选择其中一个下载即可!
下载之后进行解压!
关于模型的相关问答
一、LJSpeech 和 CSMSC 是两个不同的语音数据集,它们主要的区别在于语言、内容、发音者和用途。以下是它们的详细区别:
LJSpeech
- 语言:英语
- 内容:该数据集包含一位女性朗读的短篇小说和其他文学作品。
- 发音者:单一发音者,女性。
- 用途:主要用于英文语音合成任务,尤其适用于需要高质量语音生成的应用,如文本朗读和虚拟助手。
- 样本数量:LJSpeech 数据集包含大约 13,100 个音频片段,总时长约 24 小时。
- 下载地址:通常可以在 LJSpeech官网 下载。
CSMSC (Chinese Standard Mandarin Speech Corpus)
- 语言:中文(普通话)
- 内容:该数据集包含一位女性朗读者朗读的新闻、书籍等内容,涵盖了大量的汉字和词汇。
- 发音者:单一发音者,女性。
- 用途:主要用于中文语音合成任务,适用于各种中文语音应用,如智能音箱、导航系统等。
- 样本数量:CSMSC 数据集包含 10 小时左右的高质量普通话语音。
- 下载地址:通常可以在 PaddleSpeech 官方资源中找到。
下载配置文件
在项目根目录再新建一个“conf”的文件
分别下载如下的几个yaml文件
普通传输模式:https://github.com/PaddlePaddle/PaddleSpeech/blob/develop/demos/speech_server/conf/application.yaml
普通传输模式yaml文件案例:
host: 0.0.0.0 port: 8090 protocol: 'http' engine_list: ['tts_python'] tts_python: am: 'fastspeech2_csmsc' am_config: /home/arthur/paddlespeech_tts/models/fastspeech2_csmsc/cnndecoder.yaml am_ckpt: /home/arthur/paddlespeech_tts/models/fastspeech2_csmsc/snapshot_iter_153000.pdz am_stat: /home/arthur/paddlespeech_tts/models/fastspeech2_csmsc/speech_stats.npy phones_dict: /home/arthur/paddlespeech_tts/models/fastspeech2_csmsc/phone_id_map.txt tones_dict: '' speaker_dict: '' voc: 'mb_melgan_csmsc' voc_config: /home/arthur/paddlespeech_tts/models/mb_melgan_csmsc/default.yaml voc_ckpt: /home/arthur/paddlespeech_tts/models/mb_melgan_csmsc/snapshot_iter_1000000.pdz voc_stat: /home/arthur/paddlespeech_tts/models/mb_melgan_csmsc/feats_stats.npy lang: 'zh' device: 'gpu:3' # set 'gpu:id' or 'cpu'
上面的路径分别是我们前面下载的模型的路径!
流式传输模式yaml文件案例:
host: 0.0.0.0 port: 8092 protocol: 'http' engine_list: ['tts_online-onnx'] tts_online-onnx: am: 'fastspeech2_cnndecoder_csmsc_onnx' am_ckpt: /home/arthur/paddlespeech_tts/models/fastspeech2_cnndecoder_csmsc_onnx/fastspeech2_csmsc.onnx am_stat: phones_dict: /home/arthur/paddlespeech_tts/models/fastspeech2_cnndecoder_csmsc_onnx/phone_id_map.txt tones_dict: speaker_dict: am_sample_rate: 24000 am_sess_conf: device: "gpu:3" # set 'gpu:id' or 'cpu' use_trt: False cpu_threads: 4 voc: 'mb_melgan_csmsc_onnx' voc_ckpt: /home/arthur/paddlespeech_tts/models/mb_melgan_csmsc_onnx/mb_melgan_csmsc.onnx voc_sample_rate: 24000 voc_sess_conf: device: "gpu:3" # set 'gpu:id' or 'cpu' use_trt: False cpu_threads: 4 lang: 'zh' am_block: 72 am_pad: 12 voc_block: 36 voc_pad: 14 voc_upsample: 300
同样注意模型的路径替换为你自己的实际路径!
创建启动文件
在主文件夹中根据需要创建启动sh文件,下面是普通模式的启动文件和流式传输模式的启动文件的案例
普通模式
新建一个“start_paddlespeech_with_gpu.sh”文件
vim start_paddlespeech_with_gpu.sh
内容如下(路径要替换为你自己实际的路径):
#!/bin/bash # 进入项目目录 cd /home/arthur/paddlespeech_tts # 激活虚拟环境 source venv/bin/activate # 设置CUDA_VISIBLE_DEVICES环境变量(指定所有GPU) export CUDA_VISIBLE_DEVICES=0,1,2,3 # 启动PaddleSpeech TTS服务 paddlespeech_server start --config_file ./conf/application.yaml
然后给这个文件赋予可执行权限
chmod +x start_paddlespeech_with_gpu.sh
流式传输模式
新建一个“start_streaming_tts_server.sh”文件
vim start_streaming_tts_server.sh
内容如下(路径替换为你自己实际的路径)
#!/bin/bash # 进入项目目录 cd /home/arthur/paddlespeech_tts # 激活虚拟环境 source venv/bin/activate # 设置CUDA_VISIBLE_DEVICES环境变量(指定GPU 3) export CUDA_VISIBLE_DEVICES=0,1,2,3 # 启动PaddleSpeech流式TTS服务 paddlespeech_server start --config_file ./conf/tts_online_application.yaml
同样给这个文件赋予可执行权限
chmod +x start_streaming_tts_server.sh
启动服务端
直接按需要执行如下两条命令中的任意一条即可!
./start_paddlespeech_with_gpu.sh
./start_streaming_tts_server.sh

原创文章,作者:朋远方,如若转载,请注明出处:https://caovan.com/paddlepaddlettsbendebushuliucheng/.html
 微信扫一扫
微信扫一扫