操作系统版本:Ubuntu 22.04
显卡类型:4 x 2080Ti 22G 魔改版
CUDA版本:12.4
模型下载地址:https://modelscope.cn/models/unsloth/DeepSeek-R1-Distill-Qwen-32B/files
☞☞☞ 定制同款Ubuntu服务器 ☜☜☜

☞☞☞ 定制同款Ubuntu服务器 ☜☜☜
环境部署
由于我们需要安装的CUDA版本是12.4,所以必须安装支持cuda12.4的显卡驱动
安装开始前请确保安装了 gcc 和 make。
sudo apt update && sudo apt upgrade && sudo apt install gcc make
安装显卡驱动
wget https://cn.download.nvidia.com/XFree86/Linux-x86_64/550.142/NVIDIA-Linux-x86_64-550.142.run sudo chmod a+x ./NVIDIA-Linux-x86_64-550.142.run sudo ./NVIDIA-Linux-x86_64-550.142.run sudo reboot
安装完显卡驱动之后,重启系统
安装CUDA Toolkit 12.4
根据下面的命令来逐步执行
wget https://developer.download.nvidia.com/compute/cuda/repos/ubuntu2204/x86_64/cuda-ubuntu2204.pin sudo mv cuda-ubuntu2204.pin /etc/apt/preferences.d/cuda-repository-pin-600 wget https://developer.download.nvidia.com/compute/cuda/12.4.1/local_installers/cuda-repo-ubuntu2204-12-4-local_12.4.1-550.54.15-1_amd64.deb sudo dpkg -i cuda-repo-ubuntu2204-12-4-local_12.4.1-550.54.15-1_amd64.deb sudo cp /var/cuda-repo-ubuntu2204-12-4-local/cuda-*-keyring.gpg /usr/share/keyrings/ sudo apt-get update sudo apt-get -y install cuda-toolkit-12-4
如果出现 Command ‘nvcc‘ not found,but can be installed with: sudo apt install nvidia-cuda-toolkit 报错,需要手动添加。
先检查 cudnn 是否安装成功,输入下面的指令查看目录,如果存在 nvcc 则证明已经安装,进行下一步。
cd /usr/local/cuda/bin && ls

之后进入配置文件
vim ~/.bashrc
在文档的最后面添加下面的这两行代码,之后保存
export LD_LIBRARY_PATH=/usr/local/cuda/lib export PATH=$PATH:/usr/local/cuda/bin
更新配置
source ~/.bashrc
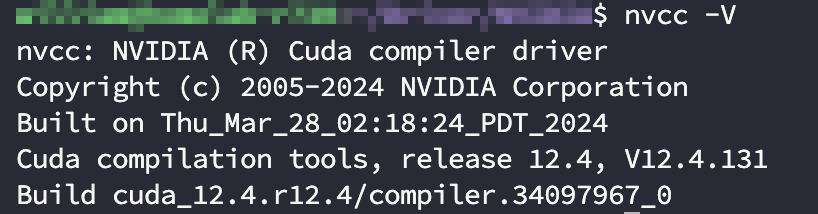
再次查看 nvcc 版本,出现如下图的 nvcc 版本
nvcc -V
安装cuDNN 9.0.0 for CUDA 12.x
根据下面的命令按步骤执行
wget https://developer.download.nvidia.com/compute/cudnn/9.0.0/local_installers/cudnn-local-repo-ubuntu2204-9.0.0_1.0-1_amd64.deb sudo dpkg -i cudnn-local-repo-ubuntu2204-9.0.0_1.0-1_amd64.deb sudo cp /var/cudnn-local-repo-ubuntu2204-9.0.0/cudnn-*-keyring.gpg /usr/share/keyrings/ sudo apt-get update sudo apt-get -y install cudnn
输入下面的指令查看 cudnn 版本,出现如下图的提示
cat /usr/include/x86_64-linux-gnu/cudnn_version_v9.h | grep CUDNN_MAJOR -A 2

安装vllm
具体方法参考往期文章《vllm让LLM的本地推理速度坐上火箭!| 以Qwen1.5-14B为例》
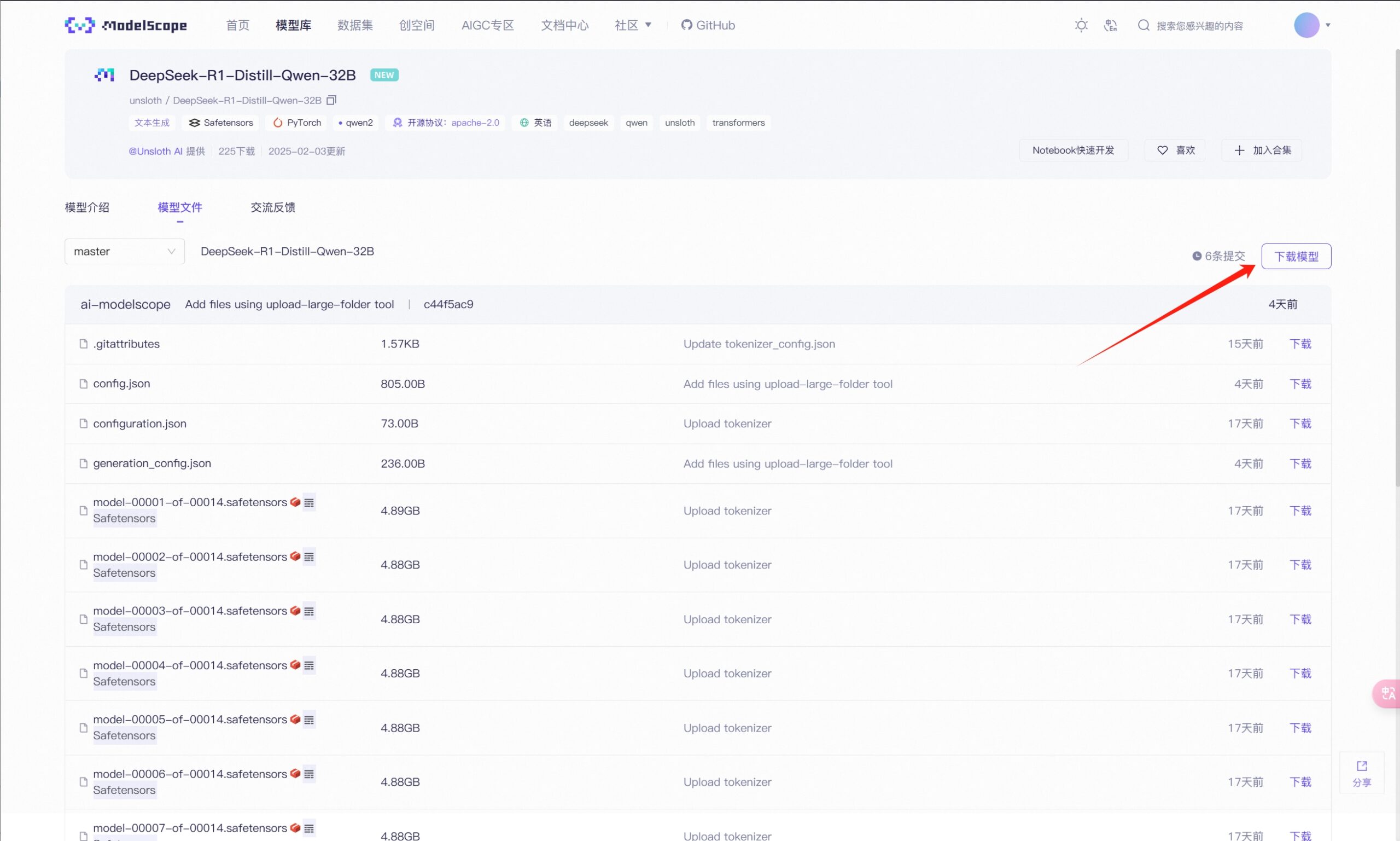
下载模型
可以从魔搭社区直接通过命令下载模型,点击模型文件页面的“下载模型”链接
选择一种你习惯的方式来下载,我这里选择的是git命令
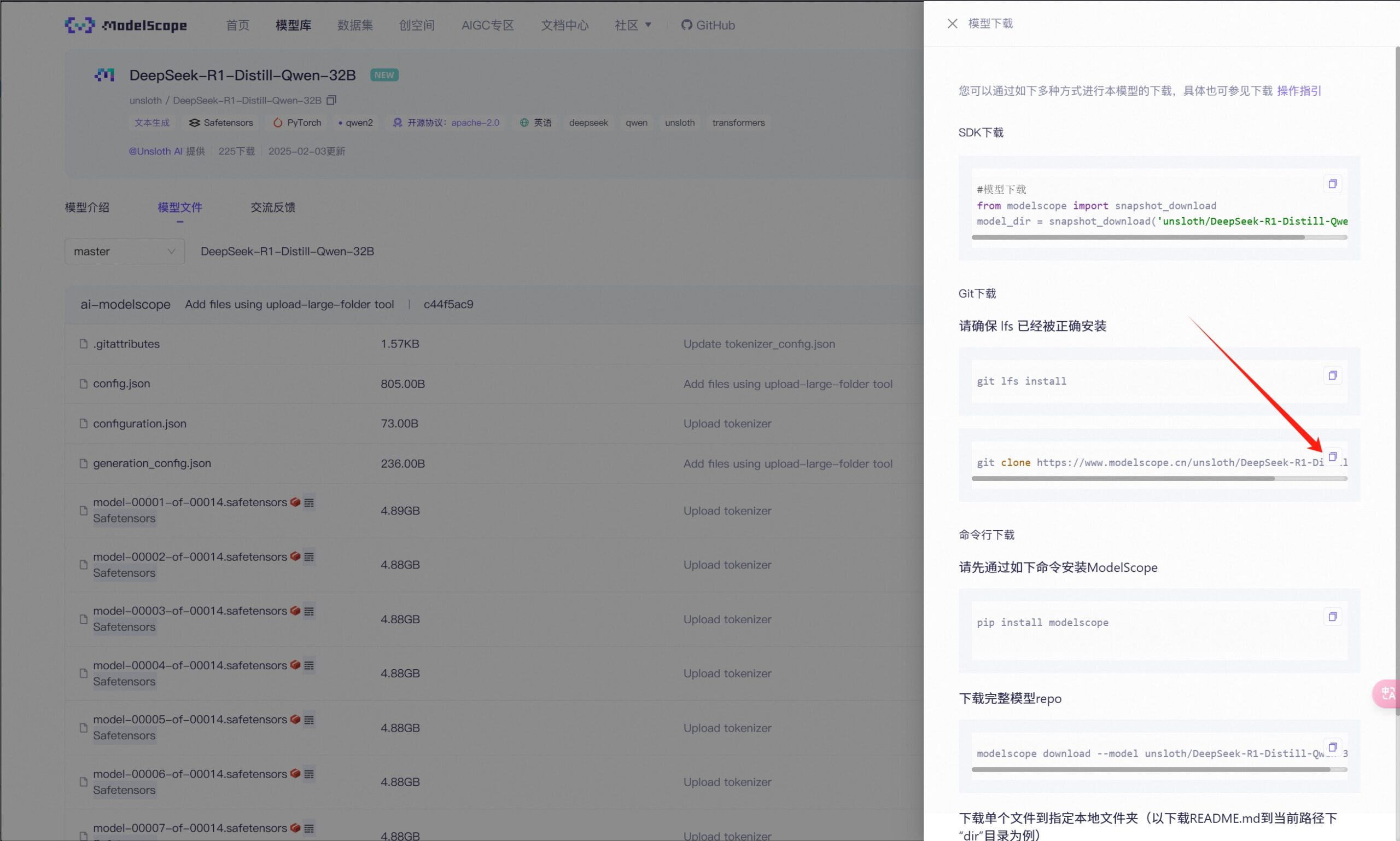
通过任意一种ssh连接服务器的方式连接到ubuntu服务器,并且cd到想要存放模型文件的路径,直接将上面复制的git命令输入回车(提前安装好git)
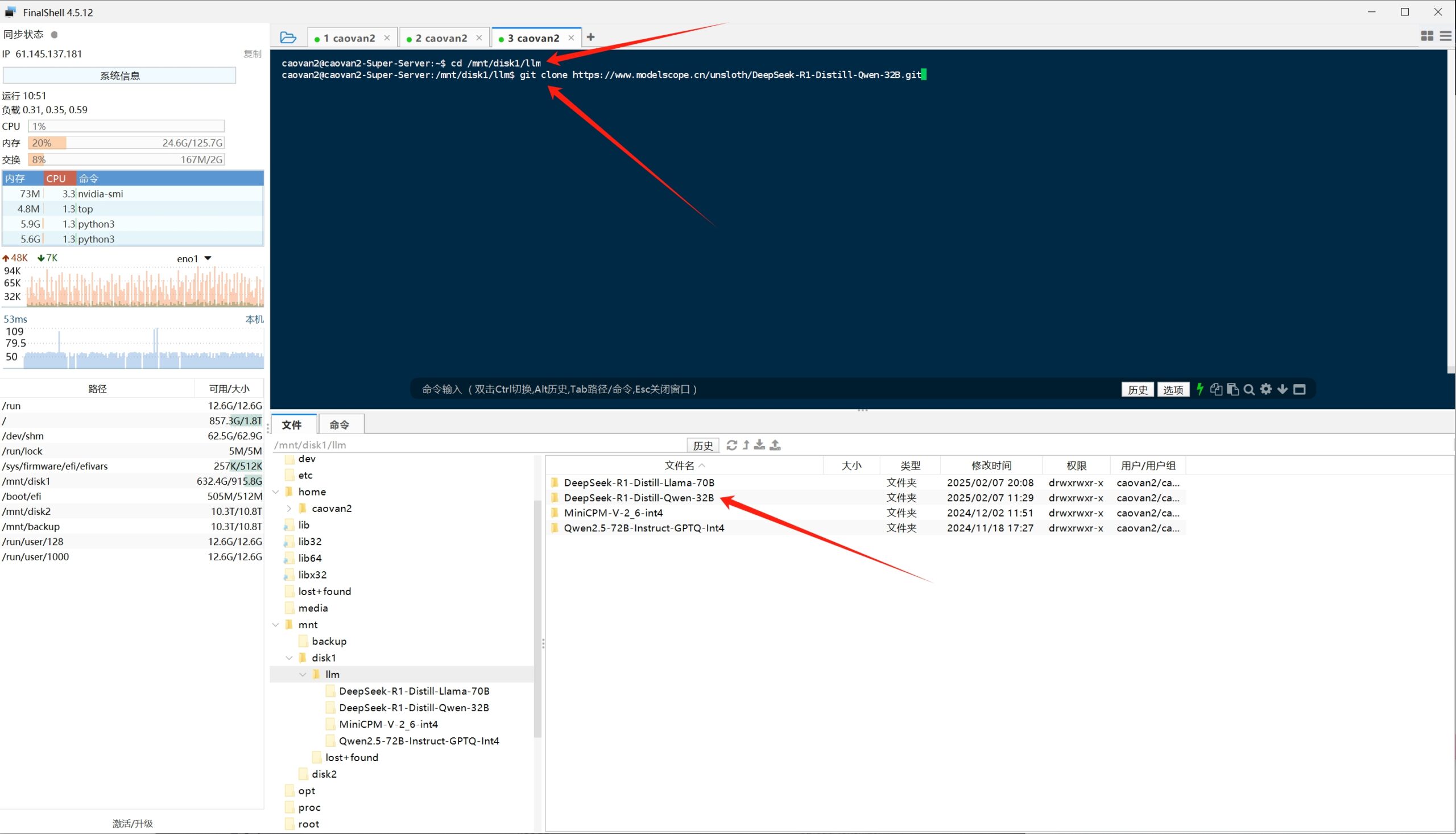
模型很大,大概有五六十G,具体的下载时间长短取决于你自己的网络情况,快的可能几十分钟,慢的可能数个小时。
运行vllm
运行如下的命令,模型的路径根据您的具体情况修改,在4x2080ti22G的服务器上,我们可以跑到上下文30000,并发可以跑到10以上,不过个人使用的话,你可以将并发数调低一点,避免内存溢出!
python3 -m vllm.entrypoints.openai.api_server \ --model /mnt/disk1/llm/DeepSeek-R1-Distill-Qwen-32B \ --served-model DeepSeek-R1-Distill-Qwen-32B \ --tensor-parallel-size 4 \ --trust-remote-code \ --dtype=half \ --gpu-memory-utilization 0.95 \ --host=0.0.0.0 --port=8001 \ --max-model-len 32768 \ --enforce-eager \ --max-num-seqs 10
实际的测试中,可以跑到17.5 tokens/s,个人使用可以说是非常足够了!
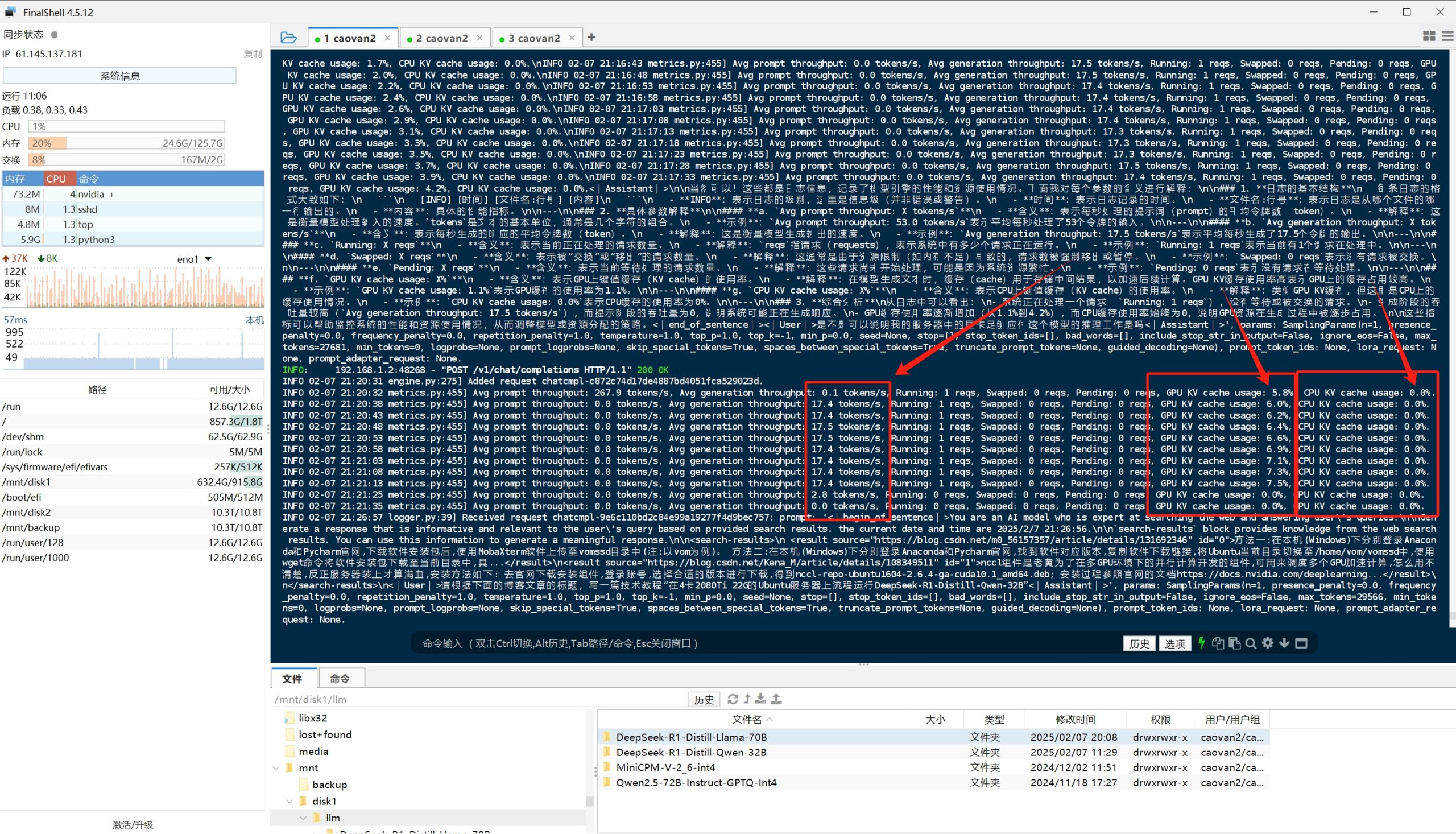
配置OneAPI
服务端运行起来了,我们还需要将服务端接入到oneapi的渠道中,才可以提供给webui或者fastGPT等客户端去调用
oneapi的开源库:https://github.com/songquanpeng/one-api
根据系统下载相应的版本,我们是Ubuntu系统,可以下载第一个文件
下载one-api这个文件,具体方法可以右键复制链接,然后在终端通过wget命令来下载
这个文件下载到Ubuntu系统后是可以直接执行的,不过在执行之前要修改权限
chmod +x one-api
然后可以直接运行下面的命令来执行这个文件
./one-api
当然也可以写一个sh文件来指定相关的端口、日志文件保存路径等
#!/bin/bash # 后台运行 one-api,并将输出日志写入当前目录的 output.log 文件 nohup ./one-api --port 3000 --log-dir ./logs > ./logs/output.log 2>&1 & echo "one-api 3000 has been started in the background."
将这个文件保存为start_one_api.sh,以后要运行one-api的时候,只需要执行这个start_one_api.sh文件即可!
one-api运行成功之后,就可以在浏览器通过3000端口来访问oneapi的页面了!
初次访问的时候会提示你修改密码
然后我们在“渠道”中新增一个渠道,将deepseek的服务端参数填入如下:
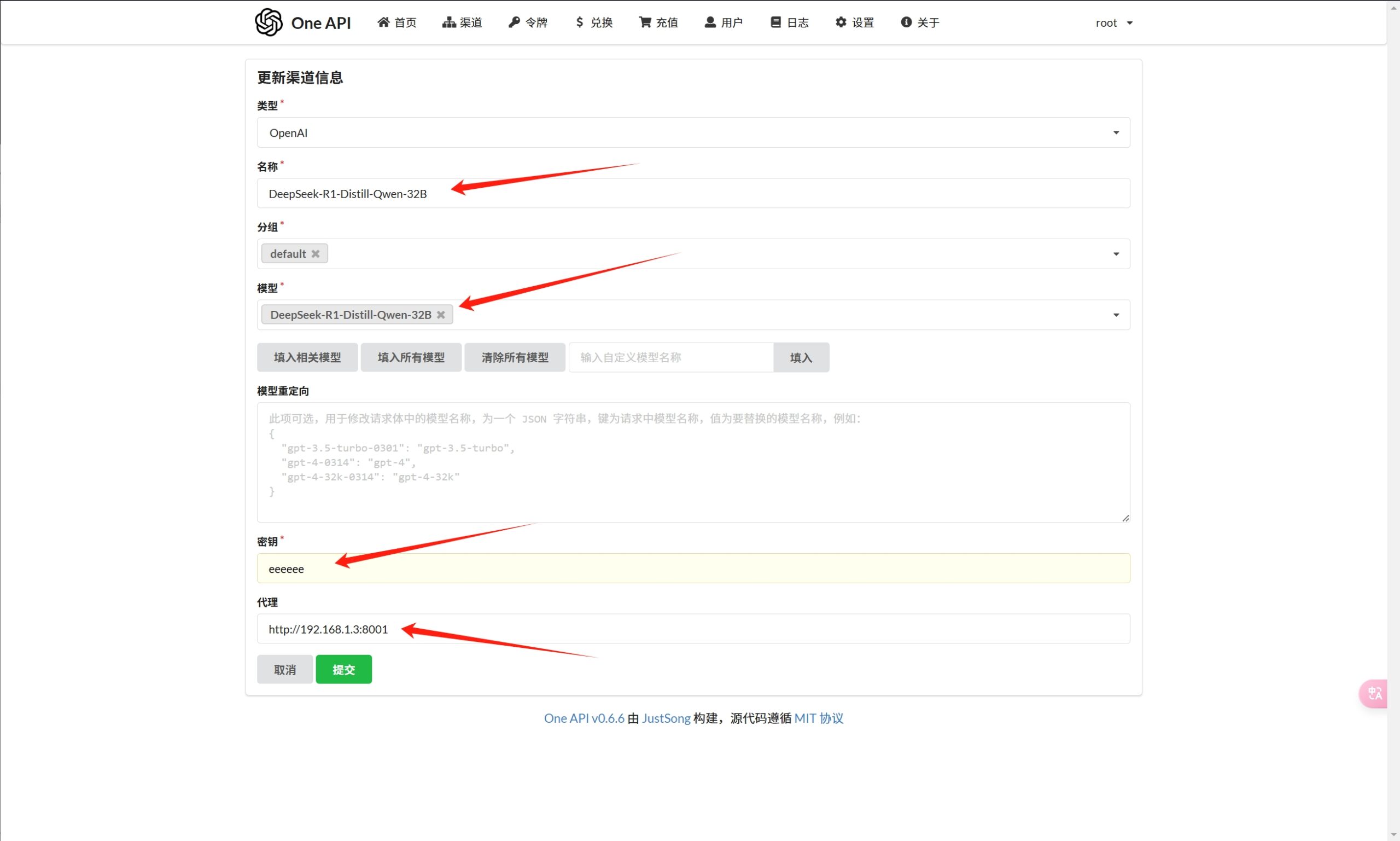
其中的模型名称不要弄错,秘钥可以随便填写,代理地址就是你在运行vllm之后得到的那个地址;
如果vllm和oneapi在同一台电脑,则地址是 http://0.0.0.0:具体端口;
如果vllm和oneapi在同一个局域网中的不同电脑,则地址是 http://192.168.x.x:具体端口,这里的ip为vllm所在的设备的IP地址;
如果vllm和oneapi不在同一个局域网中,则代理地址是vllm所在设备的外网地址;
然后在“令牌”中新建一个令牌!复制令牌(其实就是api key)
在终端应用中调用api key
fastgpt
如果要通过fastGPT来运行本地大模型,可以参考往期文章《Windows+WSL+Docker Desktop+FastGPT+m3e+oneapi+ChatGLM3部署本地AI知识库》
这里不再赘述!
Page Assist
这里我介绍另外一种更加简单的方案,可以通过Chrome浏览器的一个插件来实现!
安装Page Assist扩展
在谷歌浏览器中安装“Page Assist”扩展,可以从“Chrome 应用商店”中去搜索关键词“Page Assist”来进行安装!
设置Page Assist
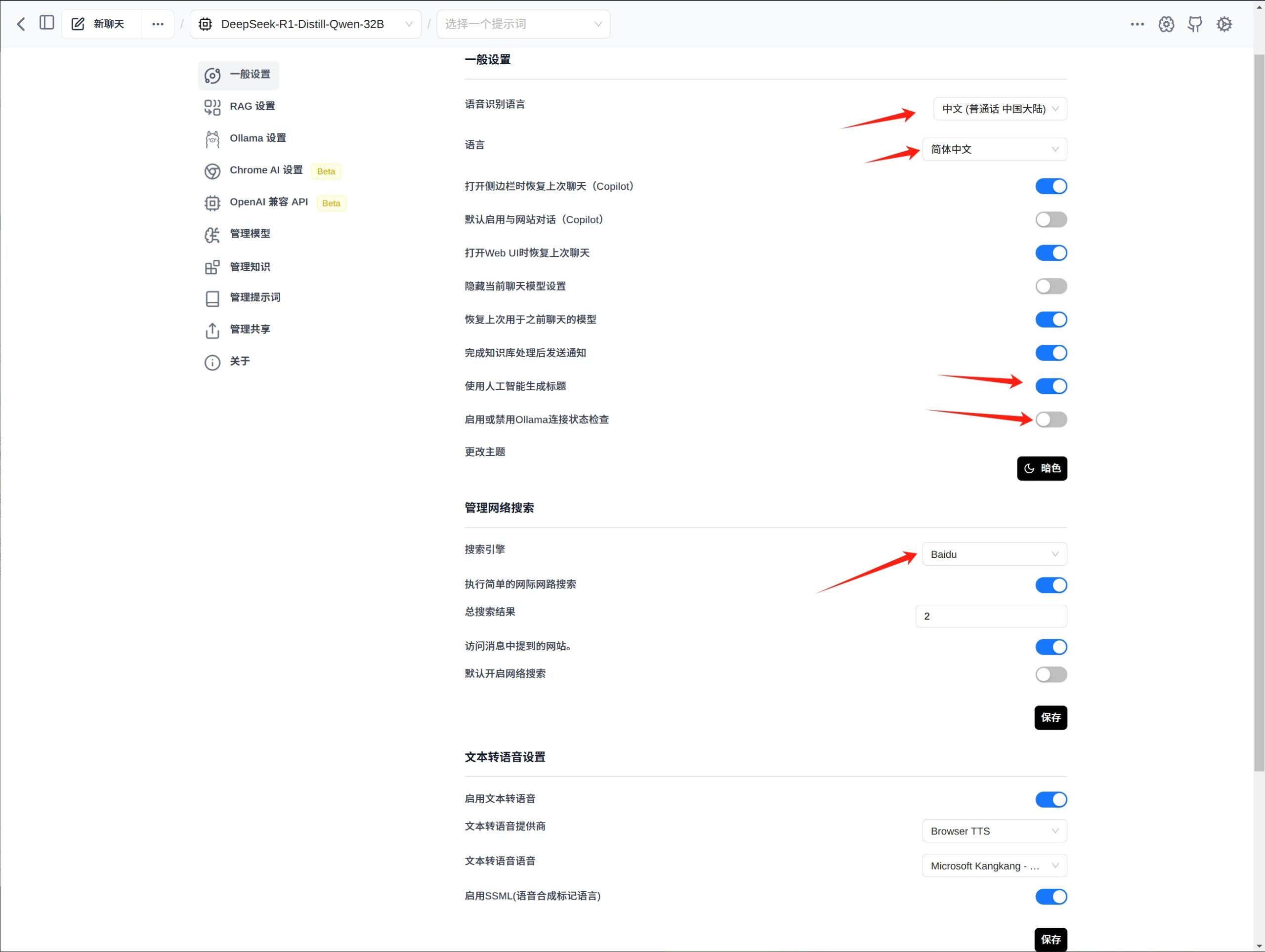
设置“一般设置”,重要的地方我已经打上了箭头
设置“OpenAI兼容API”,这里的“基础URL”指的是oneapi所在的设备地址+3000端口+/v1
如果你的oneapi是在本机(与Chrome浏览器在同一台电脑)则地址应该是
http://0.0.0.0:3000/v1
如果你的oneapi是在局域网中其他电脑(同一个路由器或者WiFi中)则地址应该是
http://192.168.x.x:3000/v1
这里的x根据实际的地址修改
如果你的oneapi所在的服务器有公网地址,你也可以直接用公网IP,或者用域名解析到对应的公网IP,这里就填写实际的域名!

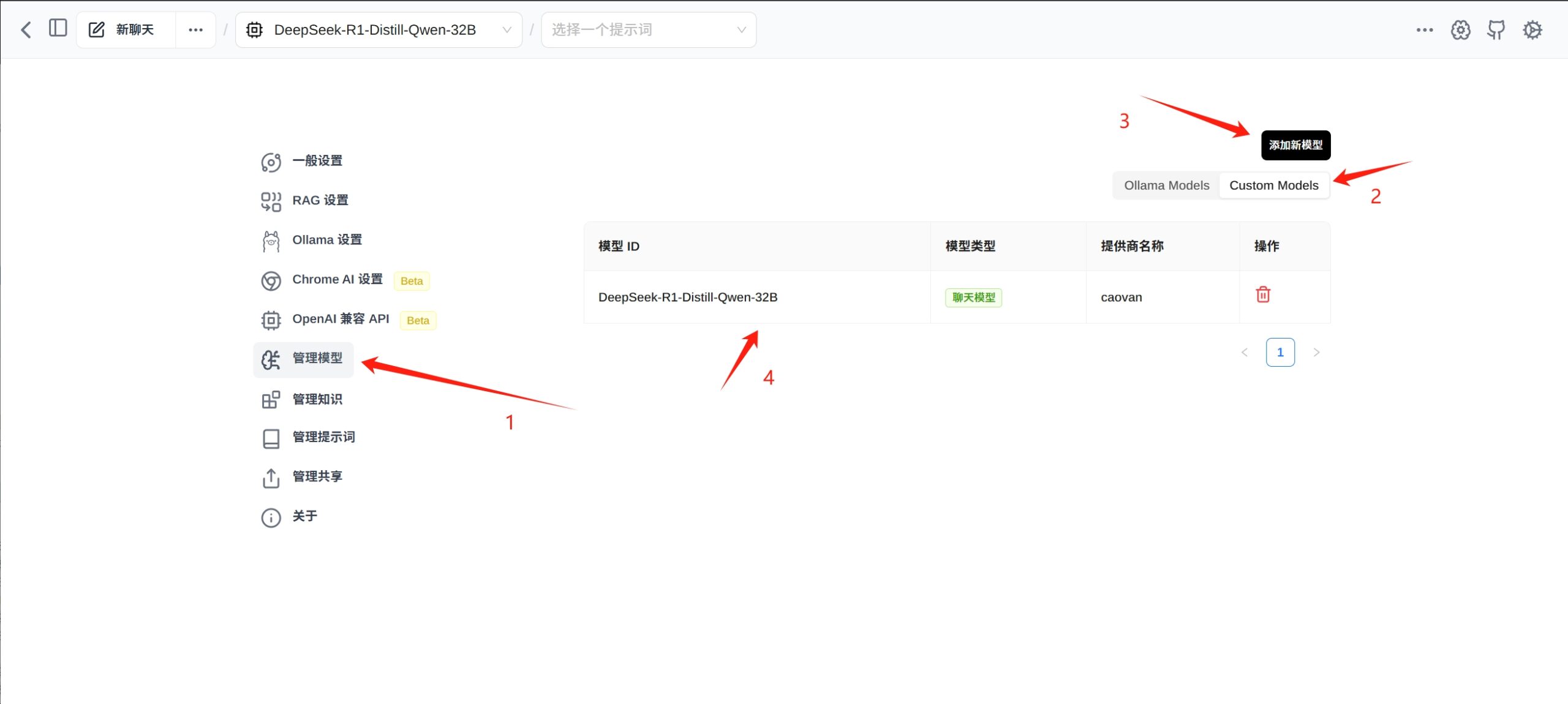
设置“管理模型”
然后就可以愉快地跟deepseek聊天了!再也不会出现“服务器繁忙,请稍后再试。”的提示了!!!
原创文章,作者:朋远方,如若转载,请注明出处:https://caovan.com/zai4ka2080ti-22gdeubuntufuwuqishangliuchengyunxingdeepseek-r1-distill-qwen-32b/.html
 微信扫一扫
微信扫一扫 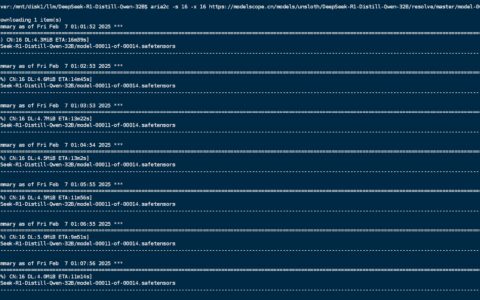



![[图文对照]stable diffusion人物表情提示词大全](https://caovan.com/./uploads/2023/08/face-promptcaovan-480x300.jpg)