用docker部署m3e
FastGPT 默认使用了 openai 的 embedding 向量模型,但是现在我们想在本地私有部署,并且调用本地的LLM,对本地的文本资料进行向量化处理,我们可以使用 M3E 向量模型进行替换。M3E 向量模型属于小模型,资源使用不高,CPU 也可以运行。
镜像名: stawky/m3e-large-api:latest
国内镜像: registry.cn-hangzhou.aliyuncs.com/fastgpt_docker/m3e-large-api:latest 端口号: 6008 环境变量
安全凭证(即oneapi中的渠道密钥) 默认值:sk-aaabbbcccdddeeefffggghhhiiijjjkkk
确认端口
由于m3e的部署默认要用到6008端口,我们在部署之前,需要先确认该端口是否被其他程序占用,如果被占用则需要在部署的时候修改为其他的端口!
在cmd命令窗口输入下面的命令,查看被占用的端口情况:
netsh int ipv4 show excludedport tcp
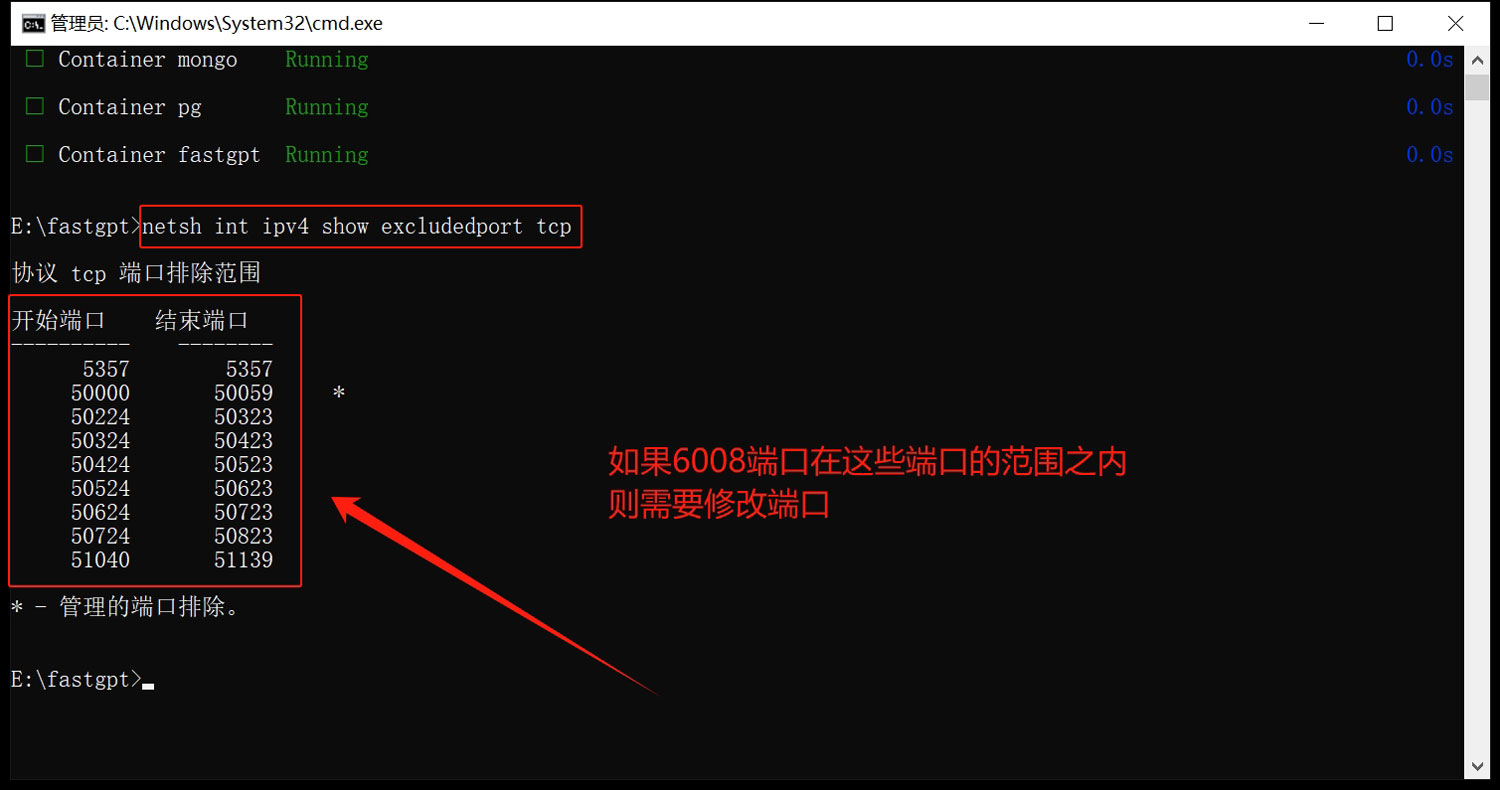
我的6008端口不在被占用的端口之内,所以我可以直接用6008端口进行部署!
部署m3e
用docker部署m3e,默认用CPU运行:
docker run -d -p 6008:6008 --name=m3e-large-api registry.cn-hangzhou.aliyuncs.com/fastgpt_docker/m3e-large-api:latest
使用GPU运行:
docker run -d -p 6008:6008 --gpus all --name=m3e-large-api registry.cn-hangzhou.aliyuncs.com/fastgpt_docker/m3e-large-api:latest
原镜像(推荐):
docker run -d -p 6008:6008 --gpus all --name=m3e-large-api stawky/m3e-large-api:latest
其中的“–gpus all”是用GPU运行,如果你要使用CPU来运行,你可以将该参数删除!
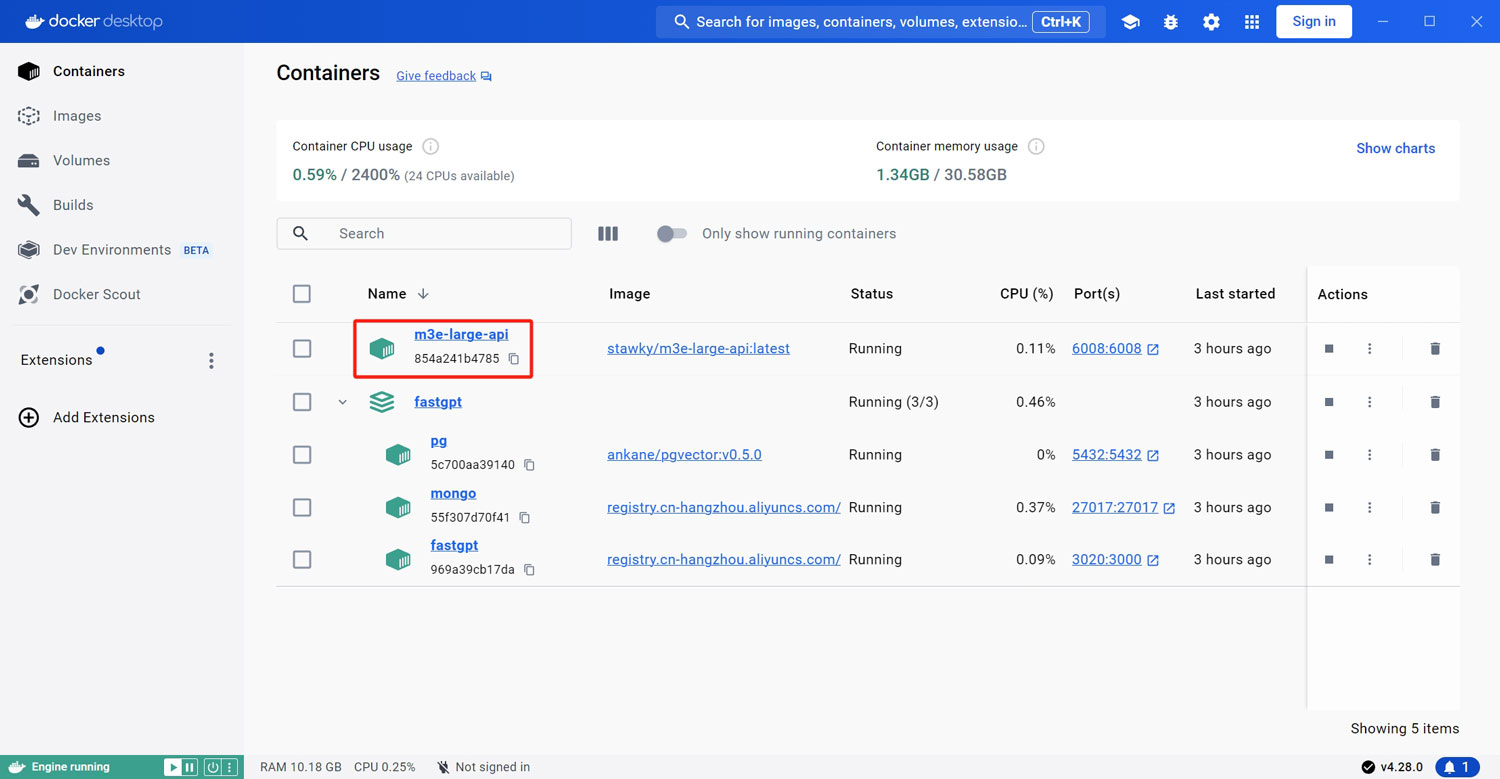
由于部署的过程中要下载几个体积比较大的文件,因此该过程需要一点时间等待!,部署完成之后你就可以在docker desktop中看到m3e
原创文章,作者:朋远方,如若转载,请注明出处:https://caovan.com/windowswsldocker-desktopfastgptm3eoneapichatglm3bushubendeaizhishiku/.html
 微信扫一扫
微信扫一扫