


梯度下降
我们把木棒(实线、模型)的表示数学化,我们既然可以用3、4做为x的系数,那我们当然可以尝试别的数字。我们用如下公式表示这种关系:
y=wx+b
其中,x和y是已知的,我们不断调整w(权重)和b(偏差),然后再带入损失函数以求得最小值的过程,就是梯度下降。
我们从-50开始到50结束设置w的值,我们通过随机数来设置偏置b,然后再带入损失函数计算我们的预测和实际值的误差损失,得到如下曲线:
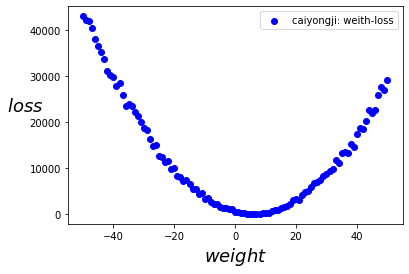
需要注意的是,我们绘制的图像是根据权重和损失绘制的曲线。而我们的模型表示是一条直线。
我们可以看到,在上图中我们是可以找到极小值的,大概在5左右,此处是我们损失最小的位置,这时我们的模型最能表示数据的规律。
梯度可以完全理解为导数,梯度下降的过程就是我们不断求导的过程。
学习率(步长)
不断调整权重和偏差来来寻找损失函数最小值的过程就是我们使用梯度下降方法拟合数据寻找最佳模型的过程。那么既然我们有了解决方案,是不是该考虑如何提升效率了,我们如何快速地找到最低点?
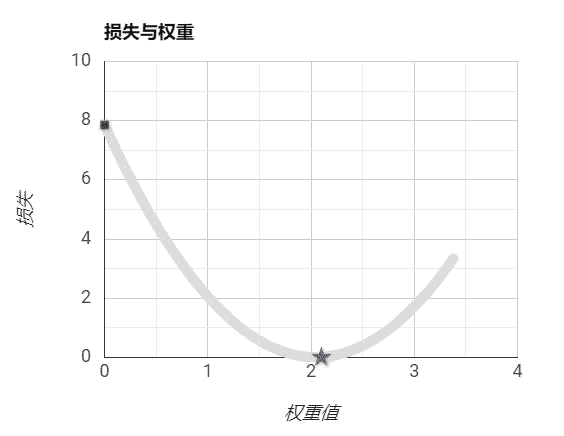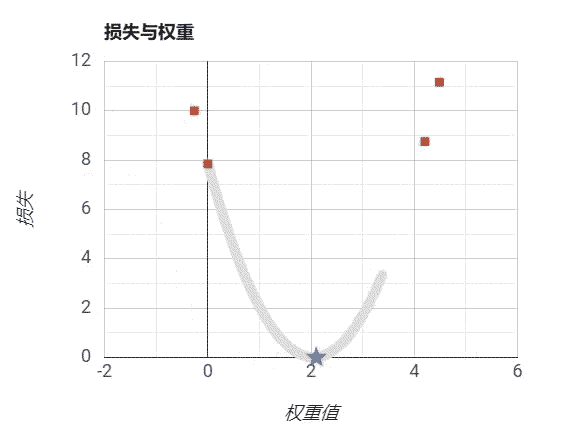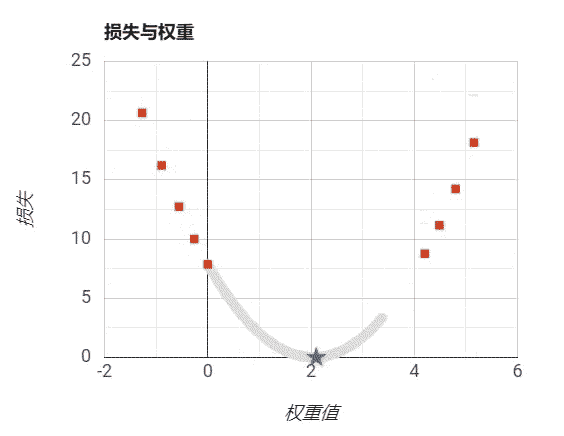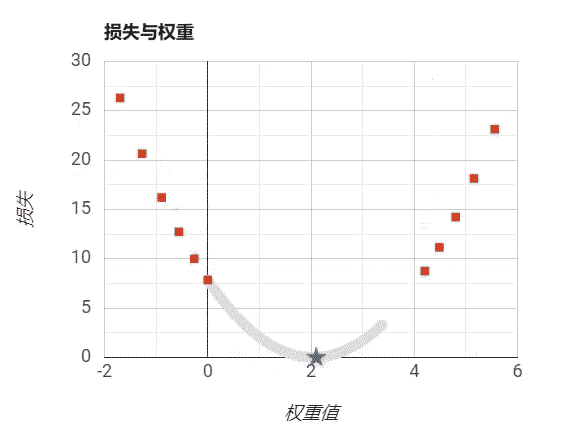
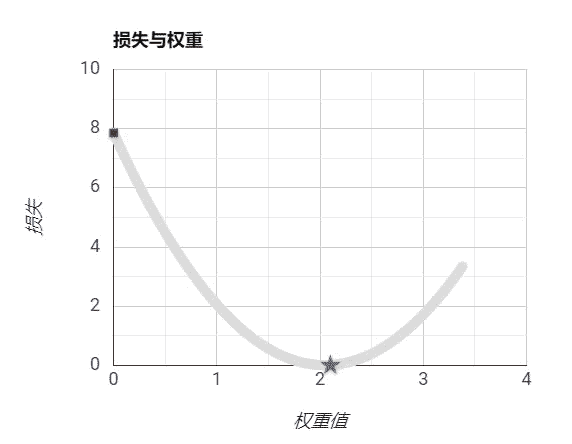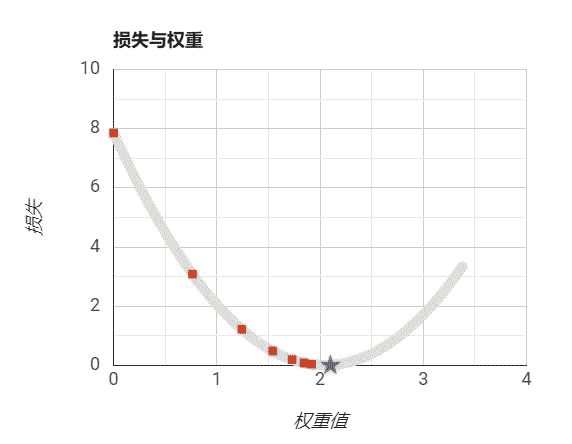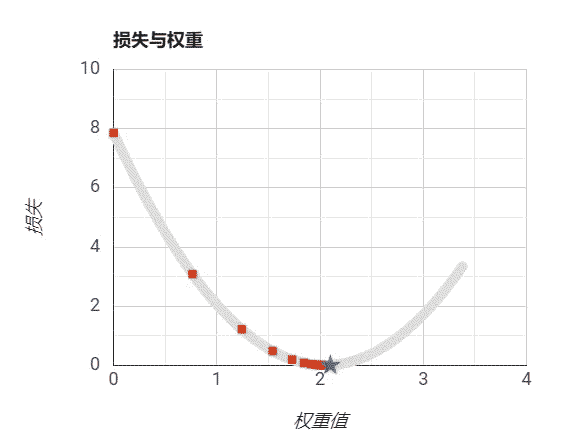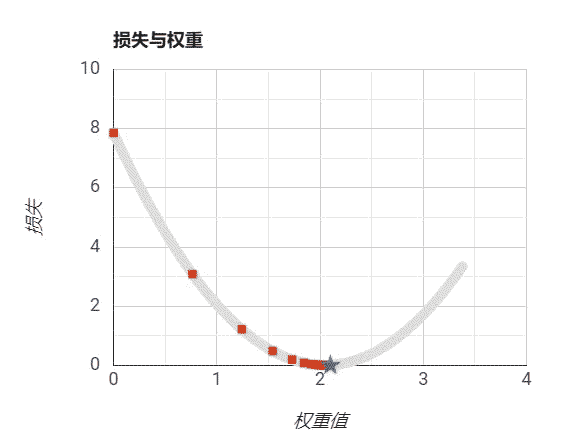
想象一下,当你迷失在山上的浓雾之中,你能感觉到的只有你脚下路面的坡度。快速到达山脚的一个策略就是沿着最陡的方向下坡。梯度下降中的一个重要的参数就是每一步的步长(学习率),如果步长太小,算法需要经过大量迭代才会收敛,如果步长太大,你可能会直接越过山谷,导致算法发散,值越来越大。
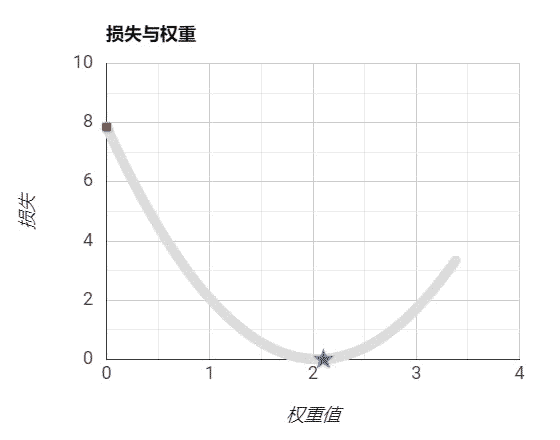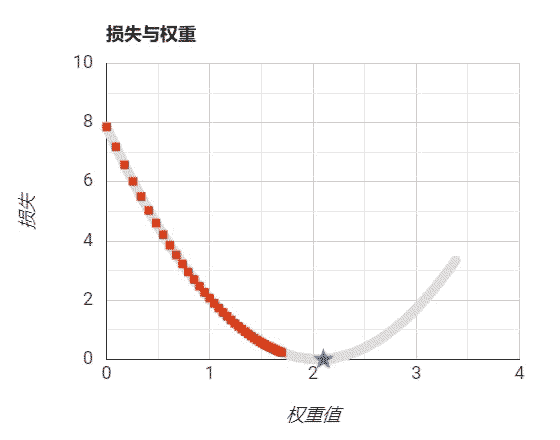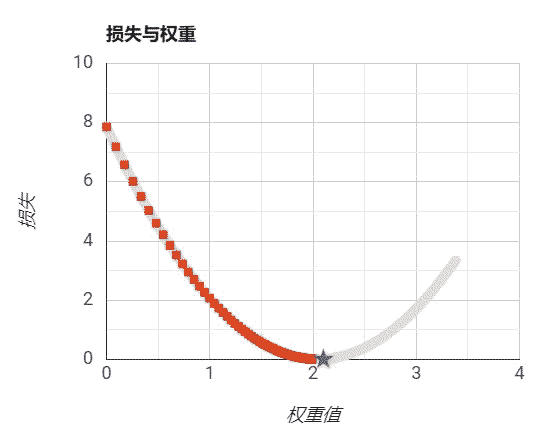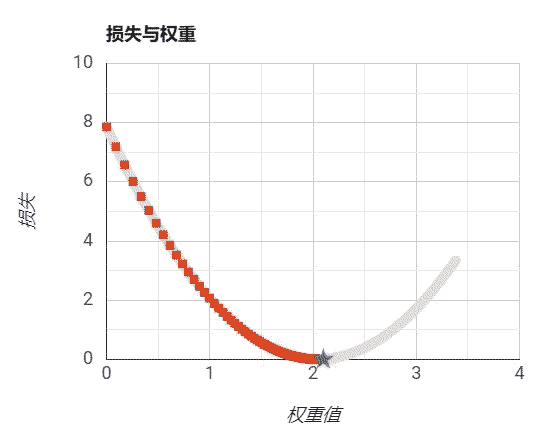
设置步长为过小:
设置步长过大:
设置步长适当:
步长是算法自己学习不出来的,它必须由外界指定。
这种算法不能学习,需要人为设定的参数,就叫做超参数。
原创文章,作者:朋远方,如若转载,请注明出处:https://caovan.com/07-lijiexianxinghuiguiyutiduxiajiangbingzuojiandanyuce/.html
 微信扫一扫
微信扫一扫 



