带成本函数的模型拟合评估
由若干参数生成的回归直线。 如何判断哪一条直线才是最佳拟合呢?
一元线性回归拟合模型的参数估计常用方法是普通最小二乘法(ordinary least squares )或线性最小二乘法(linear least squares)。 首先,我们定义出拟合成本函数,然后对参数进行数理统计。
成本函数(cost function)也叫损失函数(loss function),用来定义模型与观测值的误差。 模型预测的价格与训练集数据的差异称为残差(residuals)或训练误差(training errors)。 后面会用模型计算测试集,那时模型预测的价格与测试集数据的差异称为预测误差(prediction errors)或训练误差(test errors)。模型的残差是训练样本点与线性回归模型的纵向距离,如下图所示:
model = LinearRegression() model.fit(X,y) X2 = [[0], [10], [14], [25]] y2 = model.predict(X2) plt.plot(X, y, 'k.') plt.plot(X2, y2, 'g-') # 残差预测值 yr = model.predict(X) for idx, x in enumerate(X): plt.plot([x,x], [y[idx], yr[idx]], 'r-') plt.show()
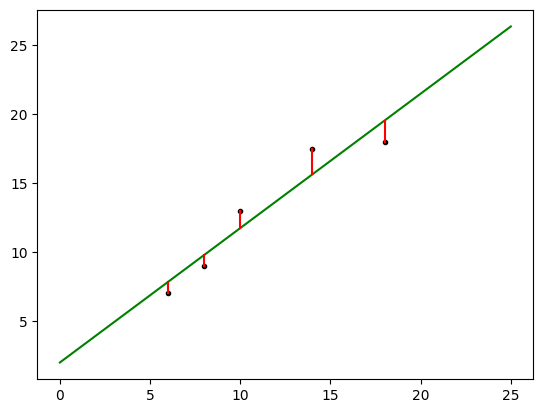
我们可以通过残差之和最小化实现最佳拟合,也就是说模型预测的值与训练集的数据最接近就是最佳拟合。对模型的拟合度进行评估的函数称为残差平方和(residual sum of squares)成本函数。 就是让所有训练数据与模型的残差的平方之和最小化,如下所示:
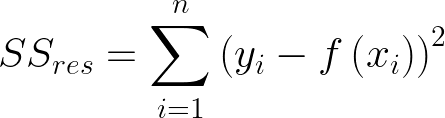
残差平方和计算如下:
import numpy as np
print("残差平方和:%.2f" %np.mean((model.predict(X) - y)**2))
原创文章,作者:朋远方,如若转载,请注明出处:https://caovan.com/08-xianxinghuigui-linear-regression/.html
 微信扫一扫
微信扫一扫