


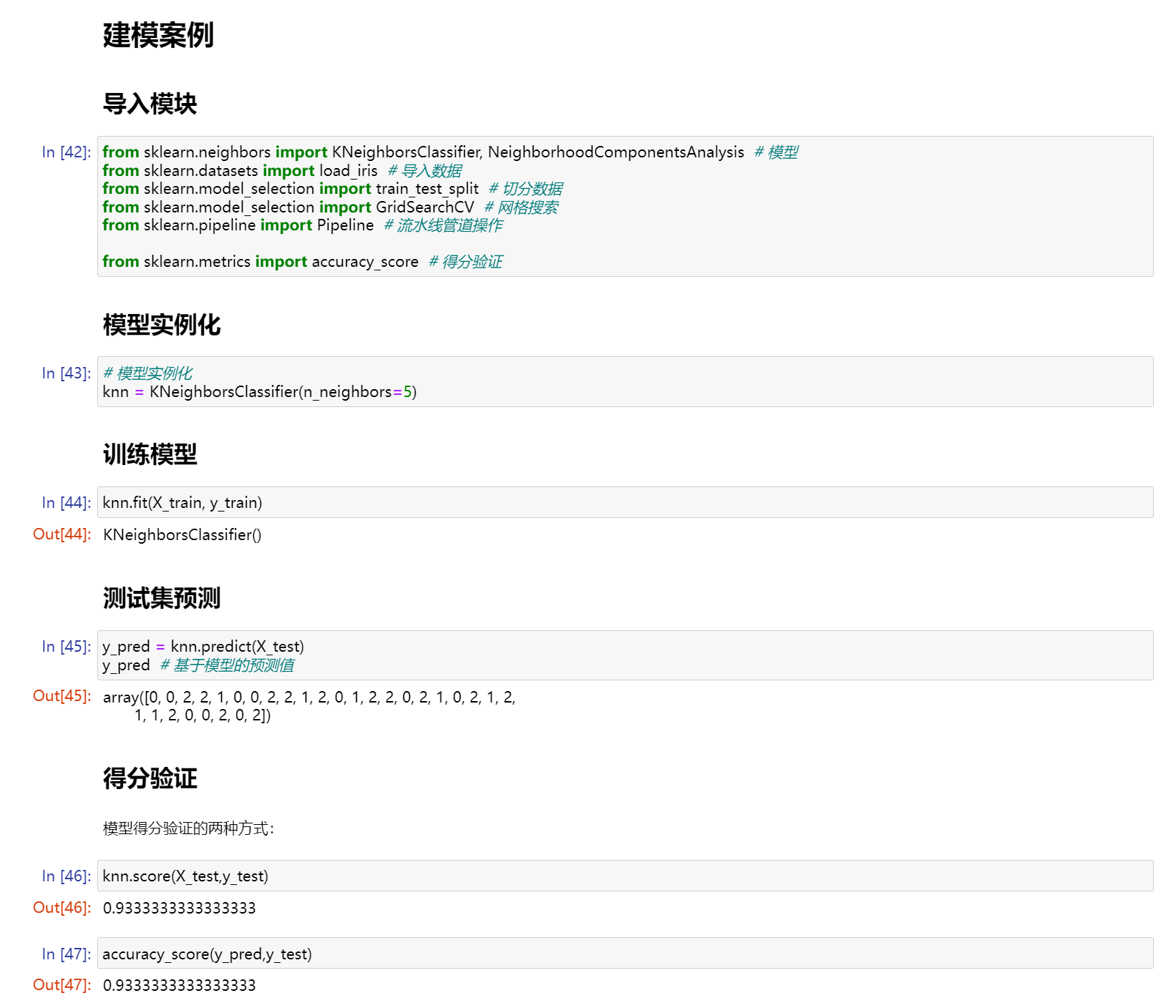
建模案例
导入模块
from sklearn.neighbors import KNeighborsClassifier, NeighborhoodComponentsAnalysis # 模型 from sklearn.datasets import load_iris # 导入数据 from sklearn.model_selection import train_test_split # 切分数据 from sklearn.model_selection import GridSearchCV # 网格搜索 from sklearn.pipeline import Pipeline # 流水线管道操作 from sklearn.metrics import accuracy_score # 得分验证
模型实例化
# 模型实例化 knn = KNeighborsClassifier(n_neighbors=5)
训练模型
knn.fit(X_train, y_train)
测试集预测
y_pred = knn.predict(X_test) y_pred # 基于模型的预测值
得分验证
模型得分验证的两种方式:
knn.score(X_test,y_test)
accuracy_score(y_pred,y_test)
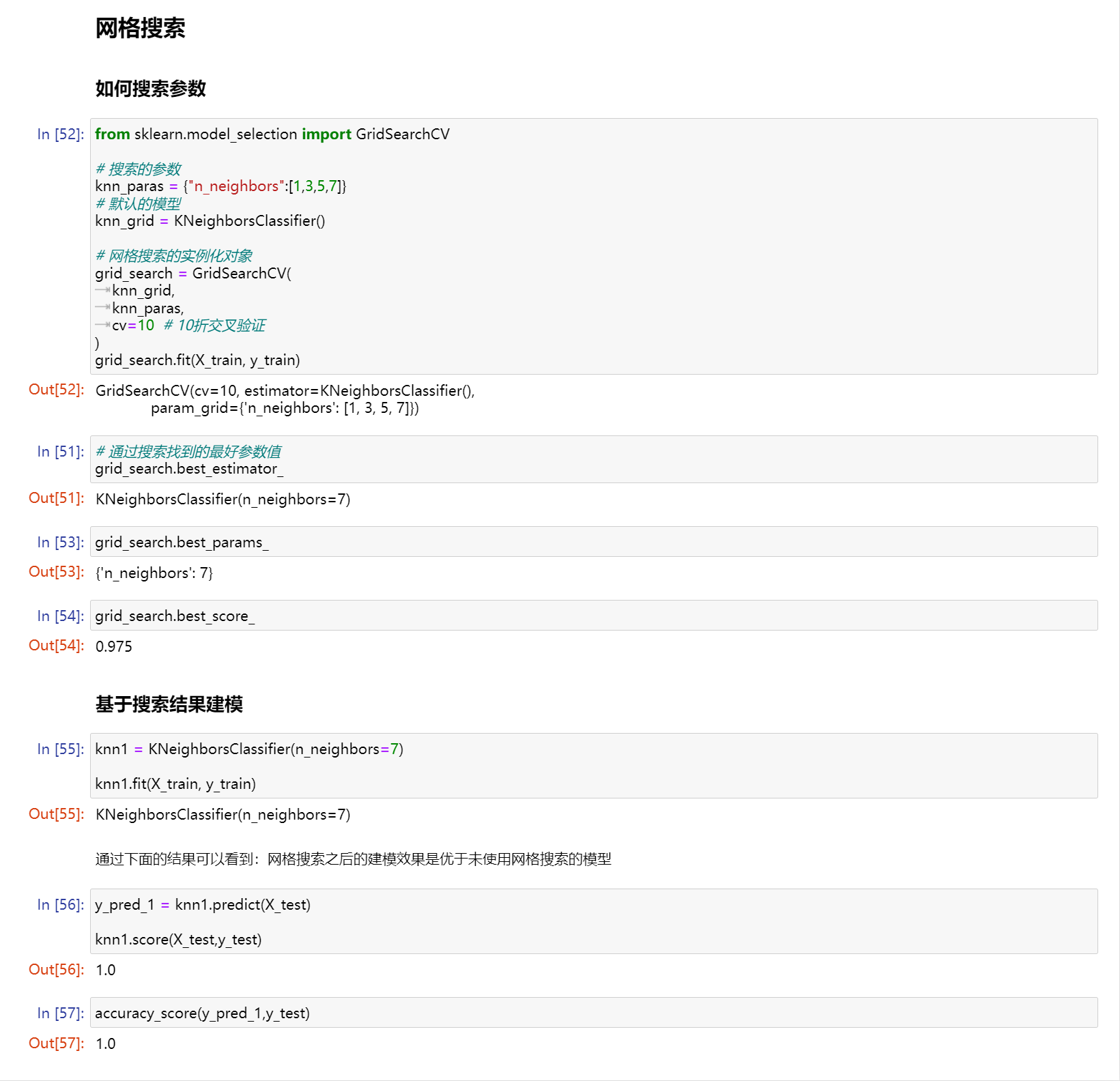
网格搜索
如何搜索参数
from sklearn.model_selection import GridSearchCV
# 搜索的参数
knn_paras = {"n_neighbors":[1,3,5,7]}
# 默认的模型
knn_grid = KNeighborsClassifier()
# 网格搜索的实例化对象
grid_search = GridSearchCV(
knn_grid,
knn_paras,
cv=10 # 10折交叉验证
)
grid_search.fit(X_train, y_train)
# 通过搜索找到的最好参数值 grid_search.best_estimator_
grid_search.best_params_
grid_search.best_score_
基于搜索结果建模
knn1 = KNeighborsClassifier(n_neighbors=7) knn1.fit(X_train, y_train)
通过下面的结果可以看到:网格搜索之后的建模效果是优于未使用网格搜索的模型
y_pred_1 = knn1.predict(X_test) knn1.score(X_test,y_test)
accuracy_score(y_pred_1,y_test)

原创文章,作者:朋远方,如若转载,请注明出处:https://caovan.com/06-scikit-learnjiaocheng/.html
 微信扫一扫
微信扫一扫