

使用教程
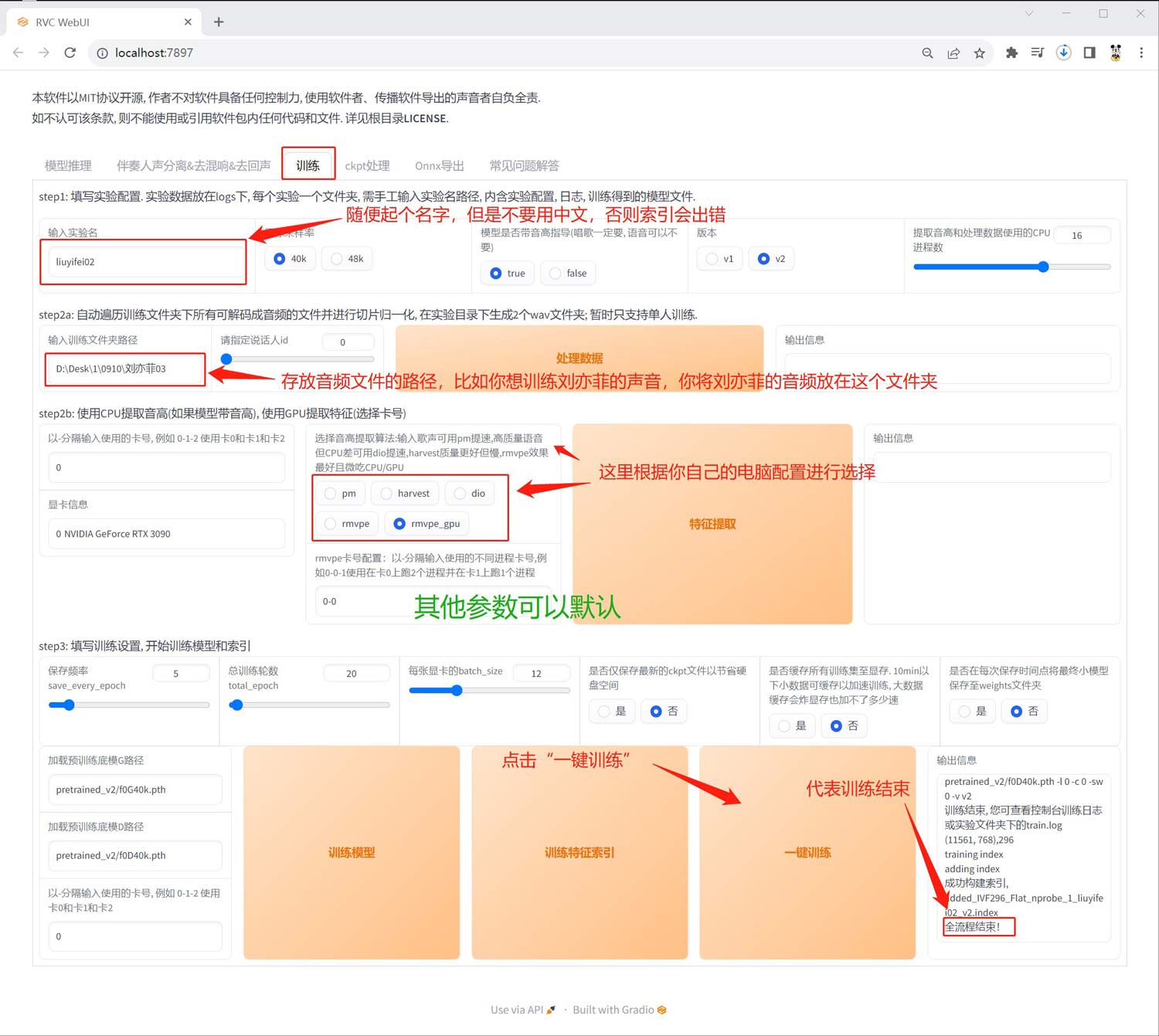
声音模型训练
尽量使用干净无背景音乐或者杂音的音频文件进行训练,音频文件推荐推荐10min至50min,高水平的训练集(精简+音色有特色),5min至10min也是可以的,可以是单个文件,也可以是多个文件(同一个人的声音),可以是wav文件,也可以是mp3文件。

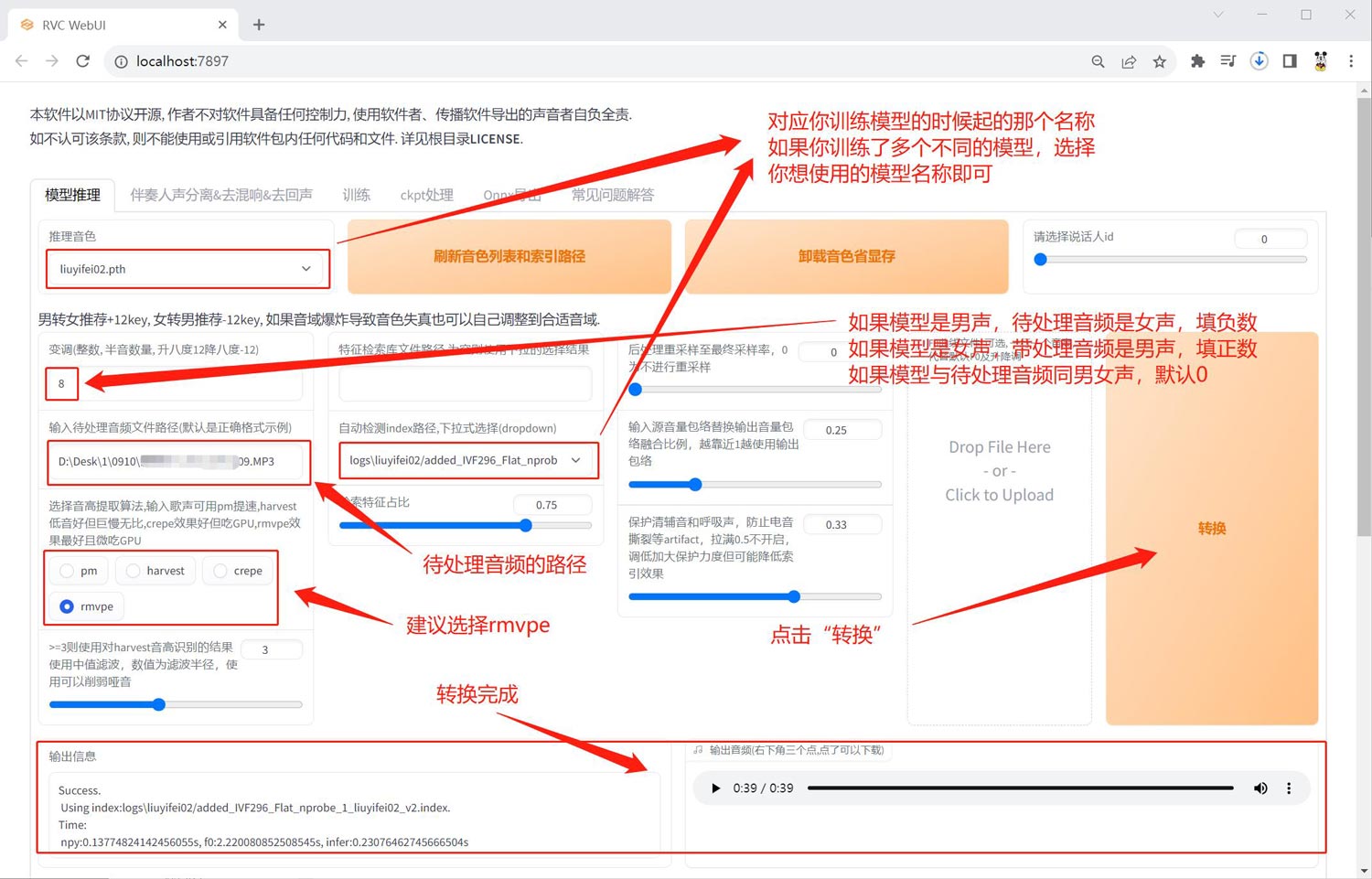
模型推理
模型推理的意思就是声音克隆,比如你已经训练好了刘亦菲的声音,你现在要将你自己的声音替换成刘亦菲的声音,这个处理过程就叫做“模型推理”,你自己的声音文件在这里就叫做“待处理音频”,待处理的音频可以是wav格式,也可以是mp3格式;
原创文章,作者:朋远方,如若转载,请注明出处:https://caovan.com/jiyuvitsdeyuyinzhuanhuanbianshengqikuangjiaretrieval-based-voice-conversion-webui/.html
 微信扫一扫
微信扫一扫